Qwen-Image ComfyUI 네이티브, GGUF, 눈차쿠 워크플로우 완전 사용 가이드
Qwen-Image는 Apache 2.0 라이선스로 오픈소스된 20B 파라미터 MMDiT(멀티모달 확산 변환기) 모델입니다.
Qwen-Image는 알리바바 통의천문 팀이 개발한 이미지 생성 기반 모델로, 20B 파라미터 MMDiT(멀티모달 확산 변환기) 아키텍처를 채택하여 Apache 2.0 라이선스로 오픈소스로 공개되었습니다. 이 모델은 이미지 생성 분야에서 독특한 기술적 우위를 보여주며, 특히 텍스트 렌더링과 이미지 편집에서 뛰어난 성능을 발휘합니다.
핵심 특징:
- 다국어 텍스트 렌더링 능력: 영어, 중국어, 한국어, 일본어 등 다양한 언어를 포함한 이미지를 정확하게 생성할 수 있으며, 텍스트는 선명하고 읽기 쉬우며 이미지 스타일과 조화를 이룹니다
- 풍부한 아트 스타일 지원: 사실적인 스타일부터 아트 창작, 애니메이션 스타일부터 현대 디자인까지, 프롬프트에 따라 유연하게 다양한 시각적 스타일을 전환할 수 있습니다
- 정밀한 이미지 편집 기능: 기존 이미지에 대한 부분 수정, 스타일 변환, 콘텐츠 추가 등의 작업을 지원하며, 전체 시각적 일관성을 유지합니다
관련 리소스:
Qwen-Image ComfyUI 네이티브 워크플로우 가이드
본 문서에 첨부된 워크플로우에서 사용되는 다양한 모델은 다음과 같습니다:
- Qwen-Image 원본 모델 fp8_e4m3fn
- 8단계 가속 버전: Qwen-Image 원본 모델 fp8_e4m3fn에 lightx2v 8단계 LoRA 사용
- 증류 버전: Qwen-Image 증류 버전 모델 fp8_e4m3fn
VRAM 사용량 참고 GPU: RTX4090D 24GB
| 사용 모델 | VRAM 사용량 | 첫 생성 | 두 번째 생성 |
|---|---|---|---|
| fp8_e4m3fn | 86% | ≈ 94s | ≈ 71s |
| fp8_e4m3fn에 lightx2v 8단계 LoRA 사용 | 86% | ≈ 55s | ≈ 34s |
| 증류 버전 fp8_e4m3fn | 86% | ≈ 69s | ≈ 36s |
1. 워크플로우 파일
ComfyUI 업데이트 후 템플릿에서 워크플로우 파일을 찾을 수 있거나, 아래 워크플로우를 ComfyUI로 드래그하여 로드할 수 있습니다

<a className="prose" target='_blank' href="https://raw.githubusercontent.com/Comfy-Org/workflow_templates/refs/heads/main/templates/image_qwen_image.json" style={{ display: 'inline-block', backgroundColor: '#0078D6', color: '#ffffff', padding: '10px 20px', borderRadius: '8px', borderColor: "transparent", textDecoration: 'none', fontWeight: 'bold'}}> <p className="prose" style={{ margin: 0, fontSize: "0.8rem" }}>공식판 JSON 형식 워크플로우 다운로드
증류 버전
2. 모델 다운로드
ComfyOrg 저장소에서 찾을 수 있는 버전
- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
- 증류 버전 (비공식, 15단계만)
모든 모델은 Huggingface 또는 魔搭에서 찾을 수 있습니다
확산 모델
Qwen_image_distill
LoRA
텍스트 인코더
VAE
모델 저장 위치
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ ├── qwen_image_fp8_e4m3fn.safetensors
│ │ └── qwen_image_distill_full_fp8_e4m3fn.safetensors ## 증류 버전
│ ├── 📂 loras/
│ │ └── Qwen-Image-Lightning-8steps-V1.0.safetensors ## 8단계 가속 LoRA 모델
│ ├── 📂 vae/
│ │ └── qwen_image_vae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors3. 단계별 워크플로우 완성
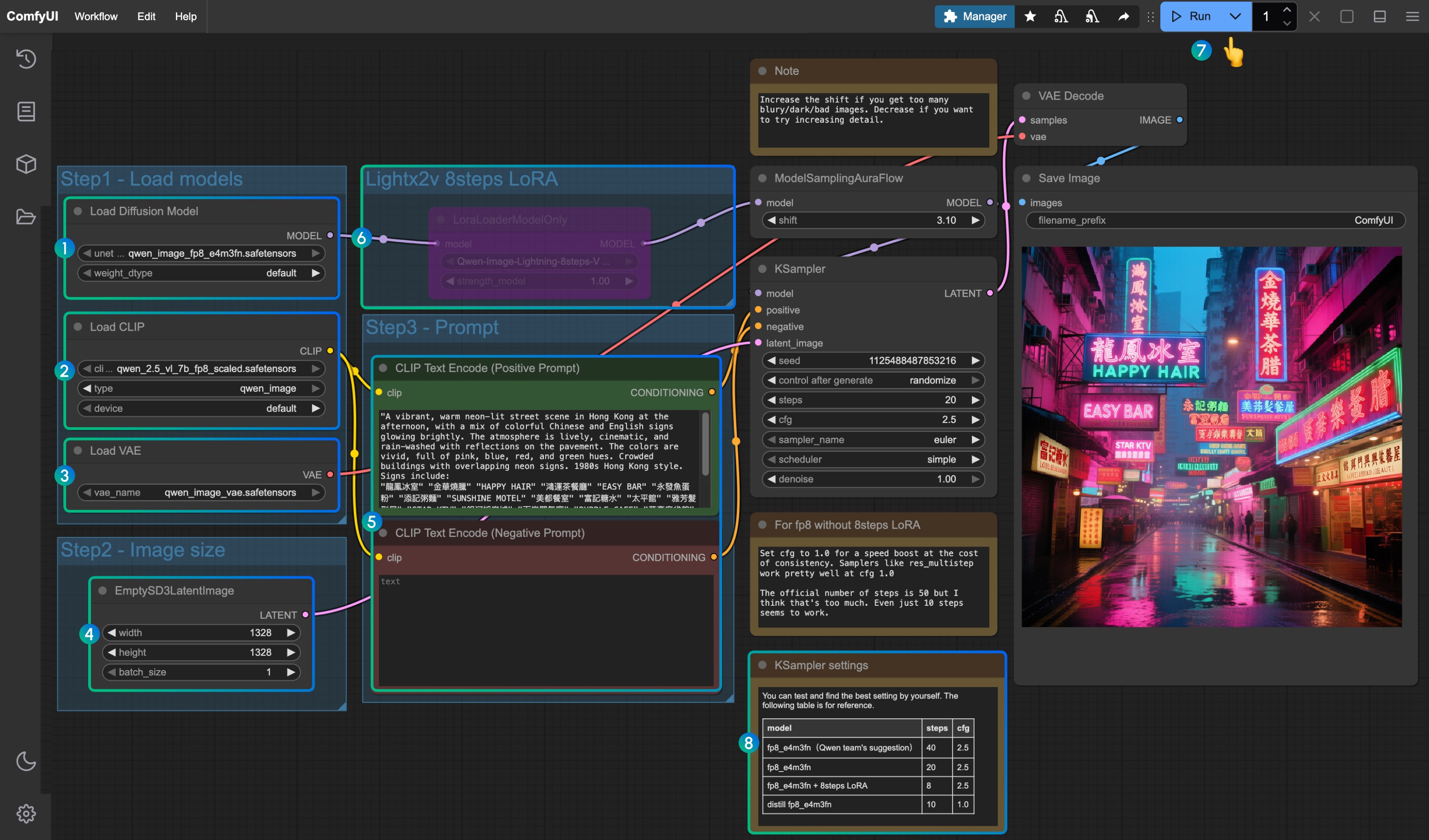
Load Diffusion Model노드가qwen_image_fp8_e4m3fn.safetensors를 로드하는지 확인Load CLIP노드가qwen_2.5_vl_7b_fp8_scaled.safetensors를 로드하는지 확인Load VAE노드가qwen_image_vae.safetensors를 로드하는지 확인EmptySD3LatentImage노드에서 이미지 크기가 올바르게 설정되었는지 확인CLIP Text Encoder노드에 프롬프트를 설정하세요. 현재 테스트 결과 최소한 다음 언어를 지원함: 영어, 중국어, 한국어, 일본어, 이탈리아어 등- lightx2v의 8단계 가속 LoRA를 활성화하려면 선택 후
Ctrl + B로 노드를 활성화하고, 번호8위치의 설정 매개변수에 따라 Ksampler 설정을 수정하세요 Queue버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(엔터)로 워크플로우를 실행- 다양한 버전의 모델과 워크플로우에 해당하는 KSampler 매개변수 설정
Qwen-Image GGUF 버전 ComfyUI 워크플로우
GGUF 버전은 저사양 VRAM 사용자에게 친화적이며, 특정 웨이트 상황에서는 약 8GB의 VRAM만으로도 Qwen-Image를 실행할 수 있습니다.
VRAM 사용량 참고:
| 워크플로우 | VRAM 사용량 | 첫 생성 | 이후 생성 |
|---|---|---|---|
| qwen-image-Q4_K_S.gguf | 56% | ≈ 135s | ≈ 77s |
| 8steps LoRA 포함 | 56% | ≈ 100s | ≈ 45s |
모델 주소: Qwen-Image-gguf
1. 커스텀 노드 업데이트 또는 설치
GGUF 버전을 사용하려면 ComfyUI-GGUF 플러그인을 설치하거나 업데이트해야 합니다
자세한 내용은 ComfyUI 커스텀 노드 설치 방법을 참조하거나 Manager에서 검색하여 설치하세요
2. 워크플로우 다운로드

3. 모델 다운로드
GGUF 버전에서 사용되는 모델은 확산 모델만이 다른 모델들과 다릅니다
https://huggingface.co/city96/Qwen-Image-gguf 에 접속하여 임의의 웨이트를 다운로드하세요. 일반적으로 파일 크기가 클수록 품질이 우수하지만 더 높은 VRAM을 요구합니다. 본 튜토리얼에서는 다음 버전을 사용합니다:
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen-image-Q4_K_S.gguf # 또는 선택한 다른 버전3. GGUF 워크플로우 단계별 완성
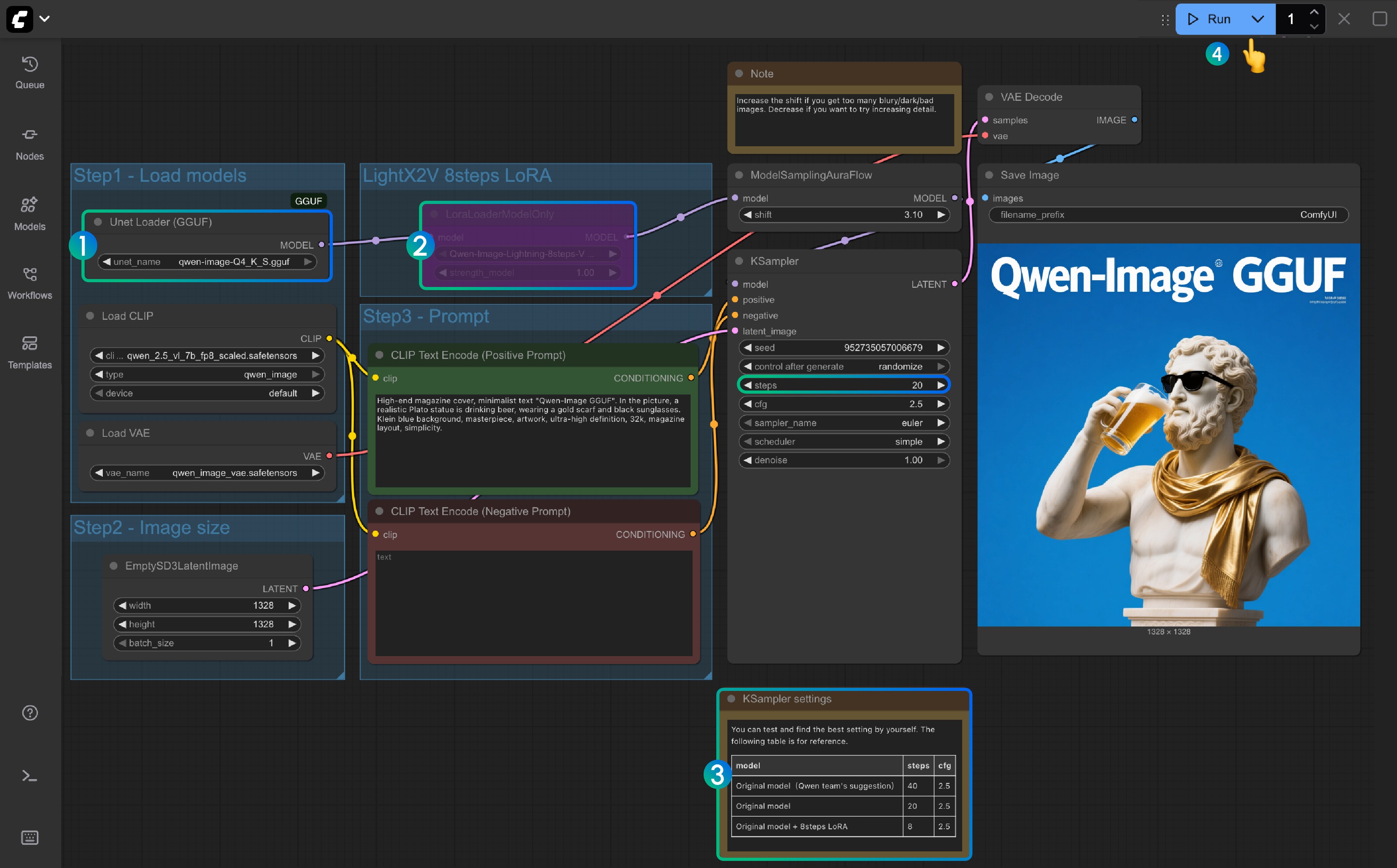
Unet Loader(GGUF)노드가qwen-image-Q4_K_S.gguf또는 다운로드한 다른 버전을 로드하는지 확인- ComfyUI-GGUF가 설치되고 업데이트되었는지 확인하세요
LightX2V 8Steps LoRA는 기본적으로 활성화되지 않으며, 선택 후 Ctrl+B로 노드를 활성화할 수 있습니다- 8단계 LoRA가 활성화되지 않은 경우 기본 단계 수는 20이며, 8단계 LoRA를 활성화하면 8로 설정하세요
- 이곳은 대응하는 단계 수 설정 참고입니다
Queue버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(엔터)로 워크플로우를 실행
Qwen-Image 눈차쿠 버전 워크플로우
모델 주소: nunchaku-qwen-image 커스텀 노드 주소: https://github.com/nunchaku-tech/ComfyUI-nunchaku
Qwen Image ControlNet
Qwen Image ControlNet DiffSynth-ControlNets Model Patches 워크플로우
이 모델은 실제로는 controlnet이 아니라 canny, depth, inpaint의 세 가지 다른 제어 모드를 지원하는 Model patch입니다.
원본 모델 주소: DiffSynth-Studio/Qwen-Image ControlNet Comfy Org 리호스트 주소: Qwen-Image-DiffSynth-ControlNets/model_patches
1. 워크플로우 및 입력 이미지
아래 이미지를 다운로드하여 ComfyUI에 드래그하여 해당 워크플로우를 로드하세요

아래 이미지를 입력 이미지로 다운로드하세요:

2. 모델 링크
다른 모델들은 Qwen-Image 기본 워크플로우와 일치합니다. 다음 모델들을 다운로드하여 ComfyUI/models/model_patches 폴더에 저장하세요:
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. 워크플로우 사용 설명
현재 diffsynth에는 세 가지 patch 모델이 있습니다: Canny, Depth, Inpaint 모델입니다.
ControlNet 관련 워크플로우를 처음 사용하는 경우, 제어에 사용되는 이미지는 모델에서 사용되고 인식되기 전에 지원되는 이미지 형식으로 전처리되어야 한다는 것을 이해해야 합니다.

- Canny: 처리된 canny, 선화 윤곽
- Depth: 전처리된 깊이 맵, 공간 관계 표현
- Inpaint: 다시 그려야 할 부분을 표시하기 위해 마스크를 사용해야 합니다
이 patch 모델은 세 가지 다른 모델로 나뉘어 있으므로, 입력 시 올바른 전처리 타입을 선택하여 이미지의 올바른 전처리를 보장해야 합니다.
Canny 모델 ControlNet 사용 설명
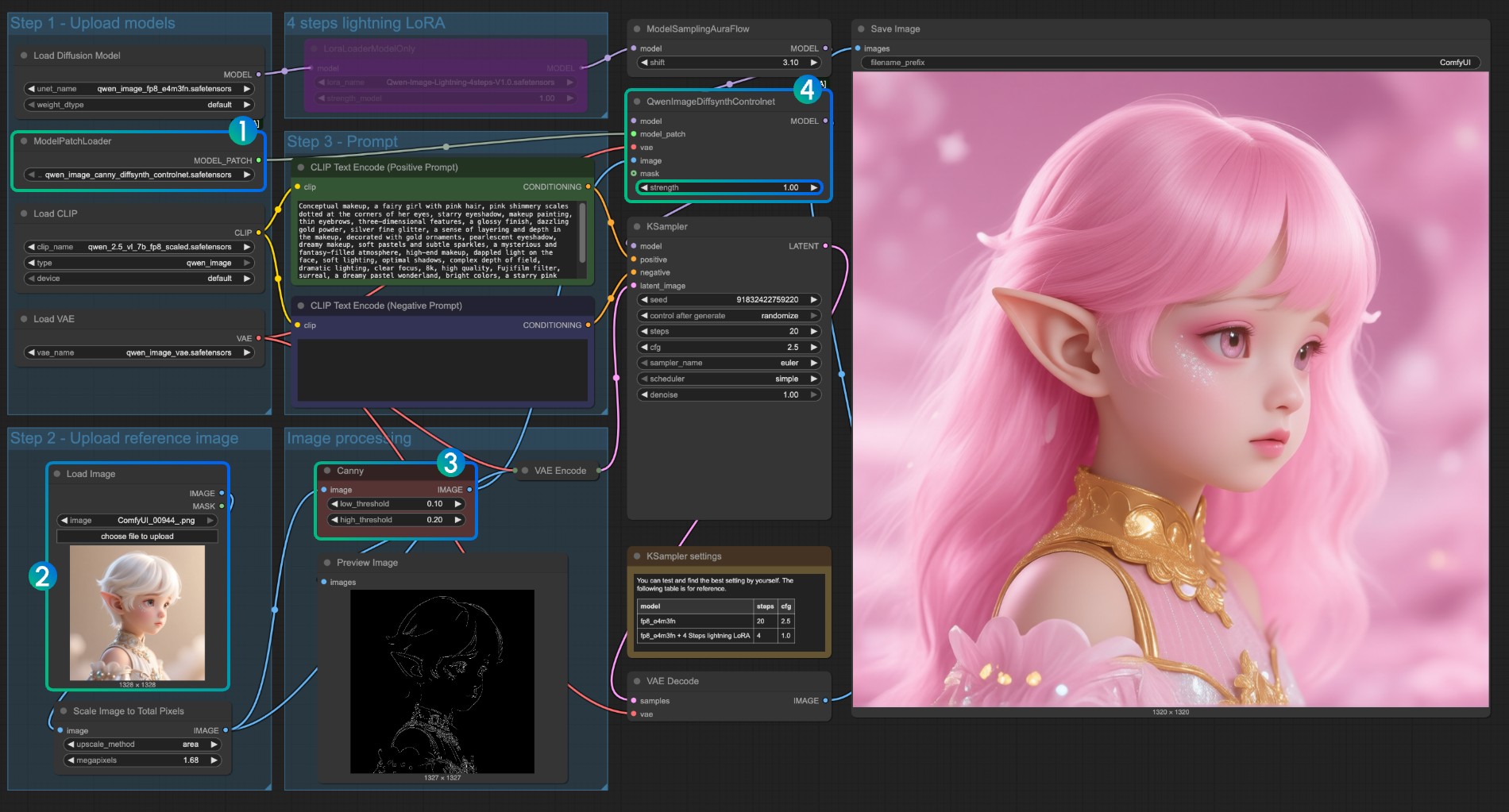
qwen_image_canny_diffsynth_controlnet.safetensors가 로드되었는지 확인- 후속 처리를 위해 입력 이미지 업로드
- Canny 노드는 네이티브 전처리 노드로, 설정한 매개변수에 따라 입력 이미지를 전처리하여 생성을 제어합니다
- 필요에 따라
QwenImageDiffsynthControlnet노드의strength매개변수를 수정하여 선화 제어의 강도를 제어할 수 있습니다 Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(엔터)로 워크플로우를 실행
qwen_image_depth_diffsynth_controlnet.safetensors를 사용하려면 이미지를 깊이 맵으로 전처리하고
image processing부분을 교체해야 합니다. 이 사용법에 대해서는 이 문서의 InstantX 처리 방법을 참조하세요. 다른 부분은 Canny 모델 사용과 유사합니다.
Inpaint 모델 ControlNet 사용 설명
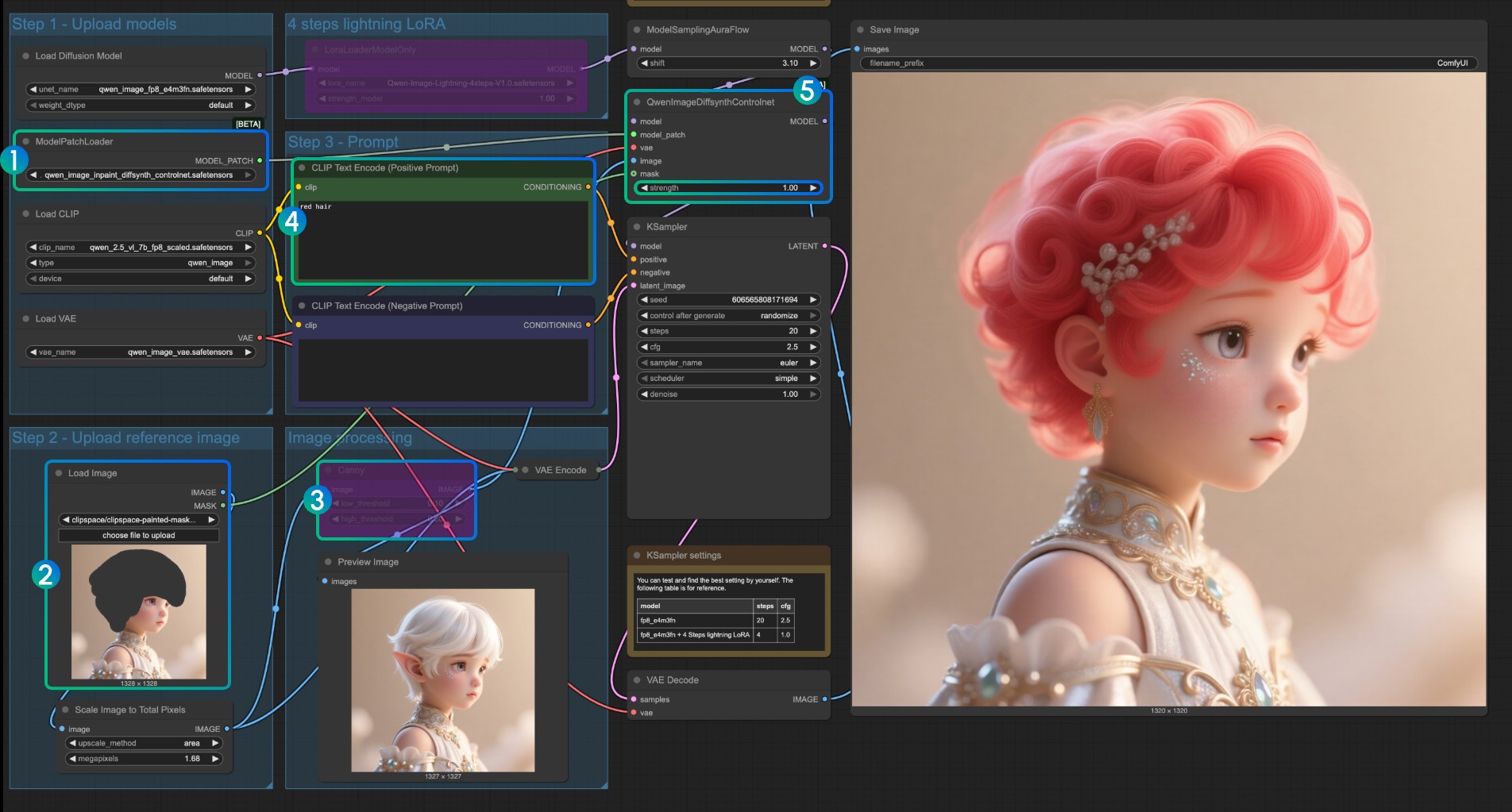
Inpaint 모델의 경우, 마스크 에디터를 사용하여 마스크를 그리고 입력 제어 조건으로 사용해야 합니다.
ModelPatchLoader가qwen_image_inpaint_diffsynth_controlnet.safetensors모델을 로드하는지 확인- 이미지를 업로드하고 마스크 에디터를 사용하여 마스크를 그립니다. 해당
Load Image노드의mask출력을QwenImageDiffsynthControlnet의mask입력에 연결하여 해당 마스크가 로드되도록 해야 합니다 Ctrl-B단축키를 사용하여 원래 워크플로우의 Canny를 바이패스 모드로 설정하여 해당 Canny 노드 처리가 효과를 발휘하지 않도록 합니다CLIP Text Encoder에서 마스크된 부분을 변경하고 싶은 스타일을 입력합니다- 필요에 따라
QwenImageDiffsynthControlnet노드의strength매개변수를 수정하여 해당 제어 강도를 제어할 수 있습니다 Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(엔터)로 워크플로우를 실행
Qwen Image Union ControlNet LoRA 워크플로우
원본 모델 주소: DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Comfy Org 리호스트 주소: qwen_image_union_diffsynth_lora.safetensors: canny, depth, pose, lineart, softedge, normal, openpose를 지원하는 이미지 구조 제어 LoRA
1. 워크플로우 및 입력 이미지
아래 이미지를 다운로드하여 ComfyUI에 드래그하여 워크플로우를 로드하세요

아래 이미지를 입력 이미지로 다운로드하세요:

2. 모델 링크
다음 모델을 다운로드하세요. 이것은 LoRA 모델이므로 ComfyUI/models/loras/ 폴더에 저장해야 합니다:
- qwen_image_union_diffsynth_lora.safetensors: canny, depth, pose, lineart, softedge, normal, openpose를 지원하는 이미지 구조 제어 LoRA
3. 워크플로우 설명
이 모델은 canny, depth, pose, lineart, softedge, normal, openpose 등의 제어를 지원하는 통합 제어 LoRA입니다. 많은 네이티브 이미지 전처리 노드가 완전히 지원되지 않기 때문에, comfyui_controlnet_aux와 같은 것을 사용하여 다른 이미지 전처리를 완료해야 할 수도 있습니다.
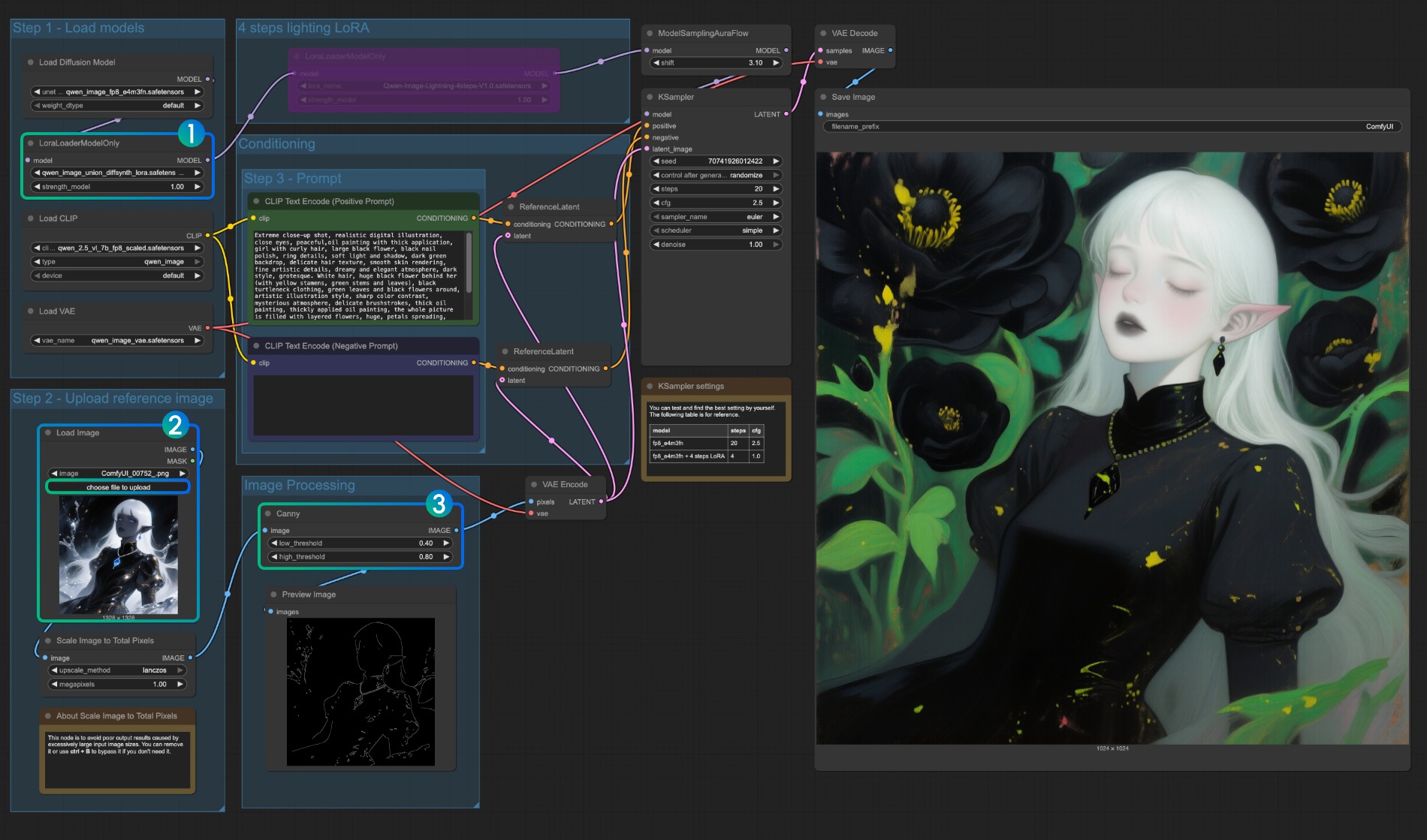
LoraLoaderModelOnly가qwen_image_union_diffsynth_lora.safetensors모델을 올바르게 로드하는지 확인- 입력 이미지 업로드
- 필요에 따라
Canny노드의 매개변수를 조정할 수 있습니다. 다른 입력 이미지는 더 나은 이미지 전처리 결과를 얻기 위해 다른 매개변수 설정이 필요하므로, 해당 매개변수 값을 조정하여 더 많은/더 적은 세부사항을 얻을 수 있습니다 Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(엔터)로 워크플로우를 실행
다른 타입의 제어에 대해서도 이미지 처리 부분을 교체해야 합니다.
댓글
GitHub로 로그인하고 토론에 참여하세요.