HunyuanVideo 이미지-투-비디오 GGUF, FP8 및 ComfyUI Native 워크플로우 완전 가이드
ComfyUI에서 텐센트의 HunyuanVideo 모델을 사용하여 이미지에서 동영상을 생성하는 완전한 튜토리얼. 환경 설정, 모델 설치 및 워크플로우 사용 방법을 자세히 설명합니다
텐센트는 2025년 3월 6일에 HunyuanVideo 이미지에서 동영상 생성 모델을 공식 출시했습니다. 현재 모델은 오픈소스로 공개되어 있으며, HunyuanVideo-I2V에서 찾을 수 있습니다.
다음은 HunyuanVideo의 전체 아키텍처 도표입니다
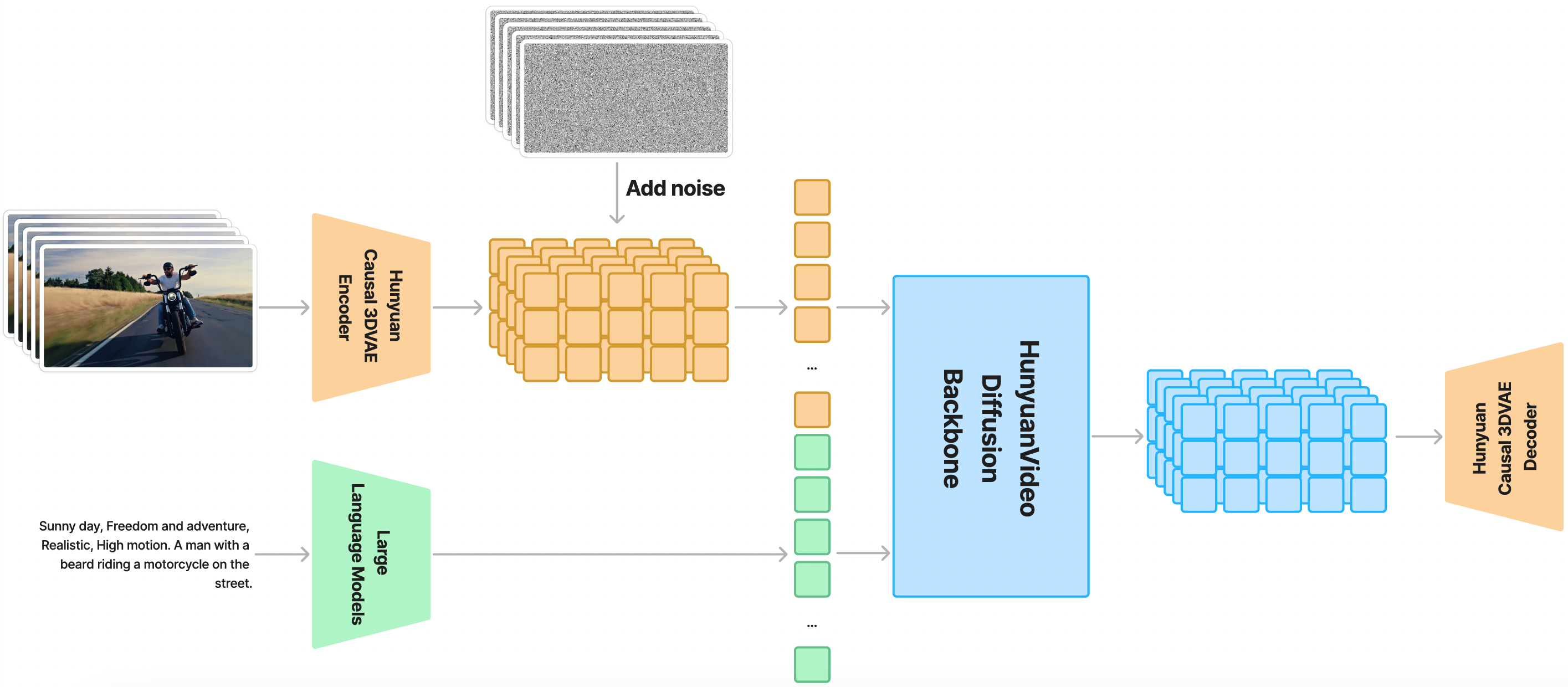
현재 ComfyUI 공식이 HunyuanVideo-I2V 모델을 기본 지원하고 있으며, 커뮤니티 개발자 kijai와 city96의 커스텀 노드도 HunyuanVideo-I2V 모델 지원을 업데이트했습니다.
텐센트 공식 버전 외에도 ComfyUI Wiki에서 확인할 수 있는 대응 버전은 다음과 같습니다:
- ComfyUI 공식 리패키지 버전(플러그인 불필요):Comfy-Org/HunyuanVideo_repackaged
- Kijai 버전, ComfyUI-HunyuanVideoWrapper 설치 필요:Kijai/HunyuanVideo_comfy
- city96 패키지 버전, ComfyUI-GGUF 설치 필요:city96/HunyuanVideo-I2V-gguf
본 글에서는 이러한 버전들을 기반으로 각각의 완전한 모델 설치와 워크플로우 사용 예시 설명을 제공합니다.
이 글에서는 주로 이미지에서 동영상 생성 워크플로우에 대해 설명합니다. 텐센트의 혼원 텍스트에서 동영상 생성 워크플로우에 대해 알고 싶다면, 텐센트 혼원 텍스트에서 동영상 생성 워크플로우 가이드 및 예시를 참조하세요.
ComfyUI 공식 HunyuanVideo I2V 워크플로우
이 워크플로우는 ComfyUI 공식 문서에서 가져왔습니다.
이 튜토리얼을 시작하기 전에 ComfyUI 업데이트 방법을 참조하여 ComfyUI를 최신 버전으로 업데이트하세요. 이를 통해 Comfy_Core의 HunyuanVideo 관련 노드 부족을 방지할 수 있습니다:
- HunyuanImageToVideo
- TextEncodeHunyuanVideo_ImageToVideo
1. HunyuanVideo I2V 워크플로우 파일
아래의 워크플로우 파일을 다운로드하고 ComfyUI에 드래그하거나, 메뉴의 Workflows -> Open(ctrl+o)를 사용하여 워크플로우를 불러옵니다.

JSON 형식 워크플로우 다운로드
2. HunyuanVideo I2V 관련 모델 다운로드
다음 모델들은 모두 Comfy-Org/HunyuanVideo_repackaged에서 구할 수 있습니다:
- llava_llama3_vision.safetensors
- clip_l.safetensors
- llava_llama3_fp16.safetensors
- llava_llama3_fp8_scaled.safetensors
- hunyuan_video_vae_bf16.safetensors
- hunyuan_video_image_to_video_720p_bf16.safetensors
다운로드 후 아래의 파일 구성에 따라 ComfyUI/models의 해당 폴더에 저장하세요:
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_image_to_video_720p_bf16.safetensors3. 입력 이미지
아래의 이미지를 입력 이미지로 다운로드하세요

HunyuanVideo I2V 워크플로우 노드 확인 절차
이미지를 참조하여 해당 노드의 내용을 확인하고, 워크플로우가 정상적으로 작동하는지 확인하세요
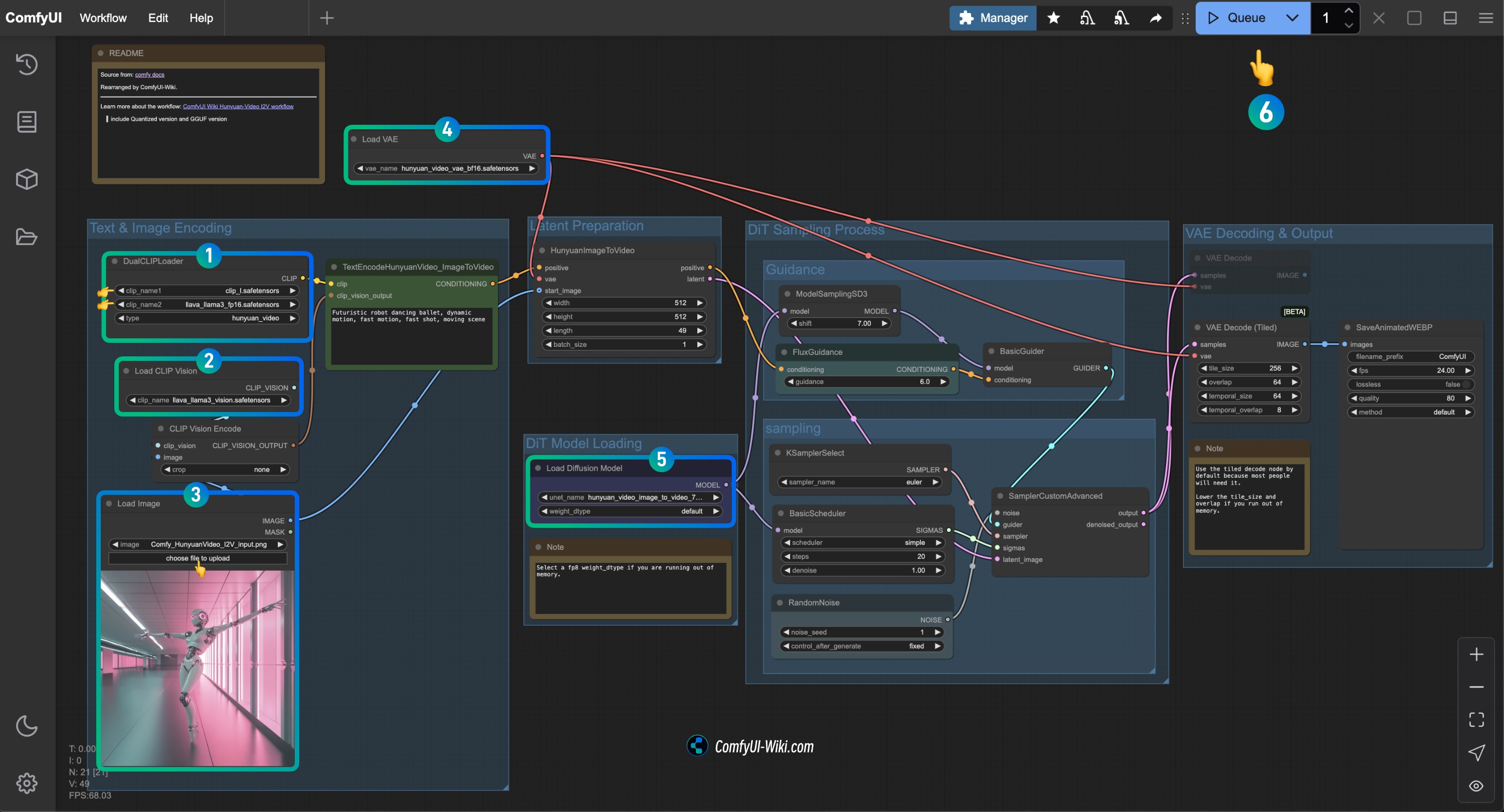
DualCLIPLoader노드 확인:
clip_name1: clip_l.safetensors가 올바르게 로드되었는지 확인clip_name2: llava_llama3_vision.safetensors가 올바르게 로드되었는지 확인
Load CLIP Vision노드 확인: llava_llama3_vision.safetensors가 올바르게 로드되었는지 확인Load Image노드에서 앞서 제공한 입력 이미지 업로드Load VAE노드 확인: hunyuan_video_vae_bf16.safetensors가 올바르게 로드되었는지 확인Load Diffusion Model노드 확인: hunyuan_video_image_to_video_720p_bf16.safetensors가 올바르게 로드되었는지 확인
- 실행 중
running out of memory.오류가 발생하면weight_dtype를fp8타입으로 설정해보세요
Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter를 사용하여 동영상 생성 실행
Kijai HunyuanVideoWrapper 버전
1. 커스텀 노드 설치
다음 커스텀 노드를 설치해야 합니다:
커스텀 노드 설치 방법을 모르는 경우 ComfyUI 커스텀 노드 설치 가이드를 참조하세요.
2. 모델 다운로드
다운로드 후 아래의 파일 구성에 따라 ComfyUI/models의 해당 폴더에 저장하세요:
ComfyUI/
├── models/
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_I2V_fp8_e4m3fn.safetensors3. HunyuanVideo I2V 워크플로우 파일
HunyuanVideo I2V 워크플로우 노드 확인 절차 (Kijai)
이미지를 참조하여 해당 노드의 내용을 확인하고, 워크플로우가 정상적으로 작동하는지 확인하세요
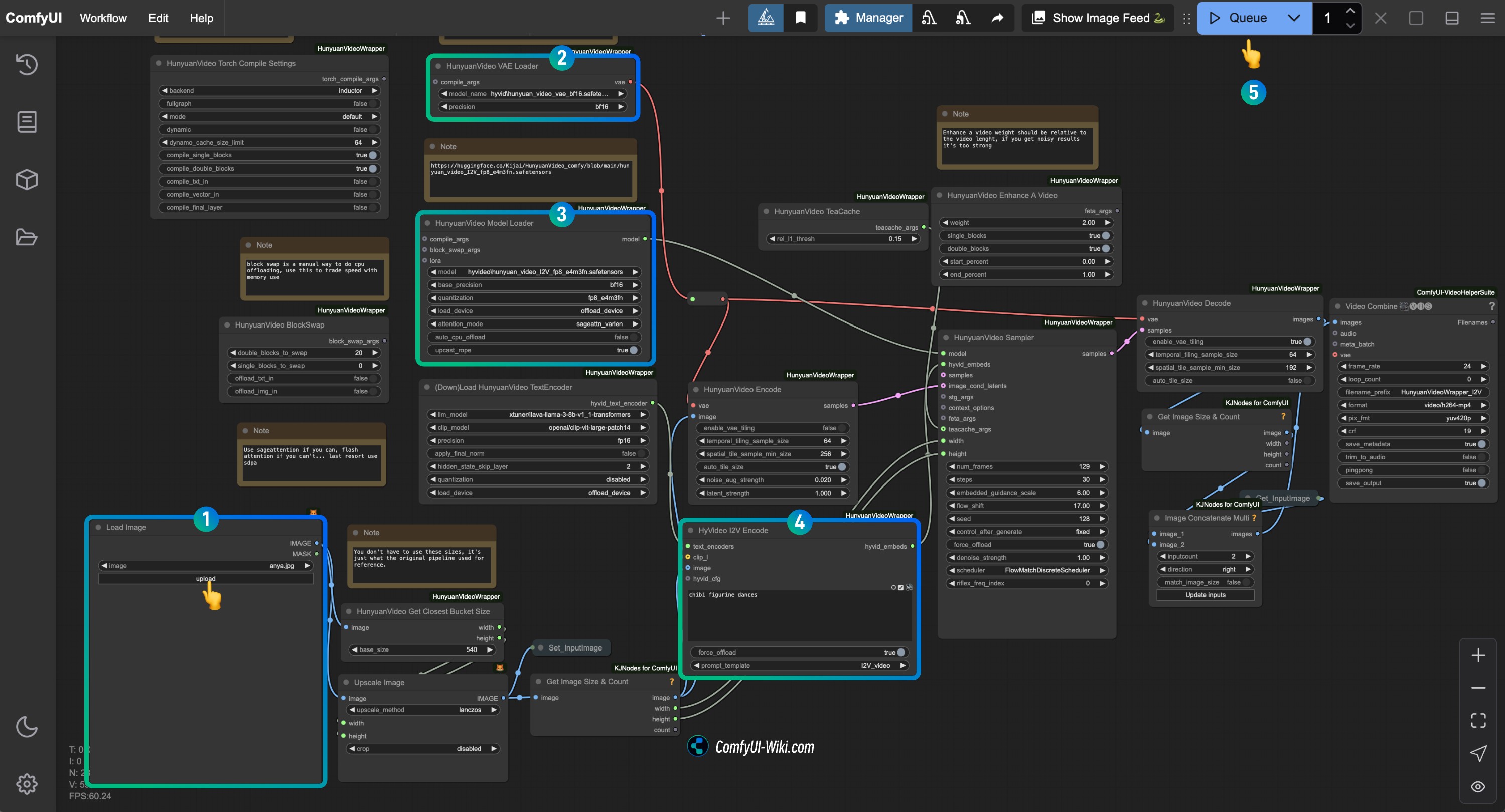
Load Image노드에서 이미지에서 동영상을 생성하고 싶은 이미지 업로드HunyuanVideo VAE Loader노드에서hunyuan_video_vae_bf16.safetensors가 올바르게 로드되었는지 확인HunyuanVideo Model Loader노드에서hunyuan_video_I2V_fp8_e4m3fn.safetensors가 올바르게 로드되었는지 확인HyVideo I2V Encode노드의 프롬프트 텍스트를 수정하여 생성하고 싶은 동영상 설명 입력Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter를 사용하여 동영상 생성 실행
city96 GGUF 버전
1. 커스텀 노드 설치 (GGUF)
다음 커스텀 노드를 설치해야 합니다:
커스텀 노드 설치 방법을 모르는 경우 ComfyUI 커스텀 노드 설치 가이드를 참조하세요.
2. 모델 다운로드 (GGUF)
이 부분의 모델은 HunyuanVideo 모델을 제외하고는 기본적으로 ComfyUI 공식 버전과 동일합니다. 해당 모델은 본 글의 ComfyUI 공식 버전 부분을 참조하여 수동으로 다운로드하세요.
city96/HunyuanVideo-I2V-gguf에 접속하여 필요한 버전의 모델을 다운로드하고, 해당 gguf 모델 파일을 ComfyUI/models 폴더에 저장해야 합니다.
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── unet/
│ └── hunyuan-video-i2v-720p-Q4_K_M.gguf // 다운로드한 버전에 따라 다름3. HunyuanVideo I2V 워크플로우 파일 (GGUF)
HunyuanVideo I2V 워크플로우 노드 확인 절차 (GGUF)
이미지를 참조하여 해당 노드의 내용을 확인하고, 워크플로우가 정상적으로 작동하는지 확인하세요
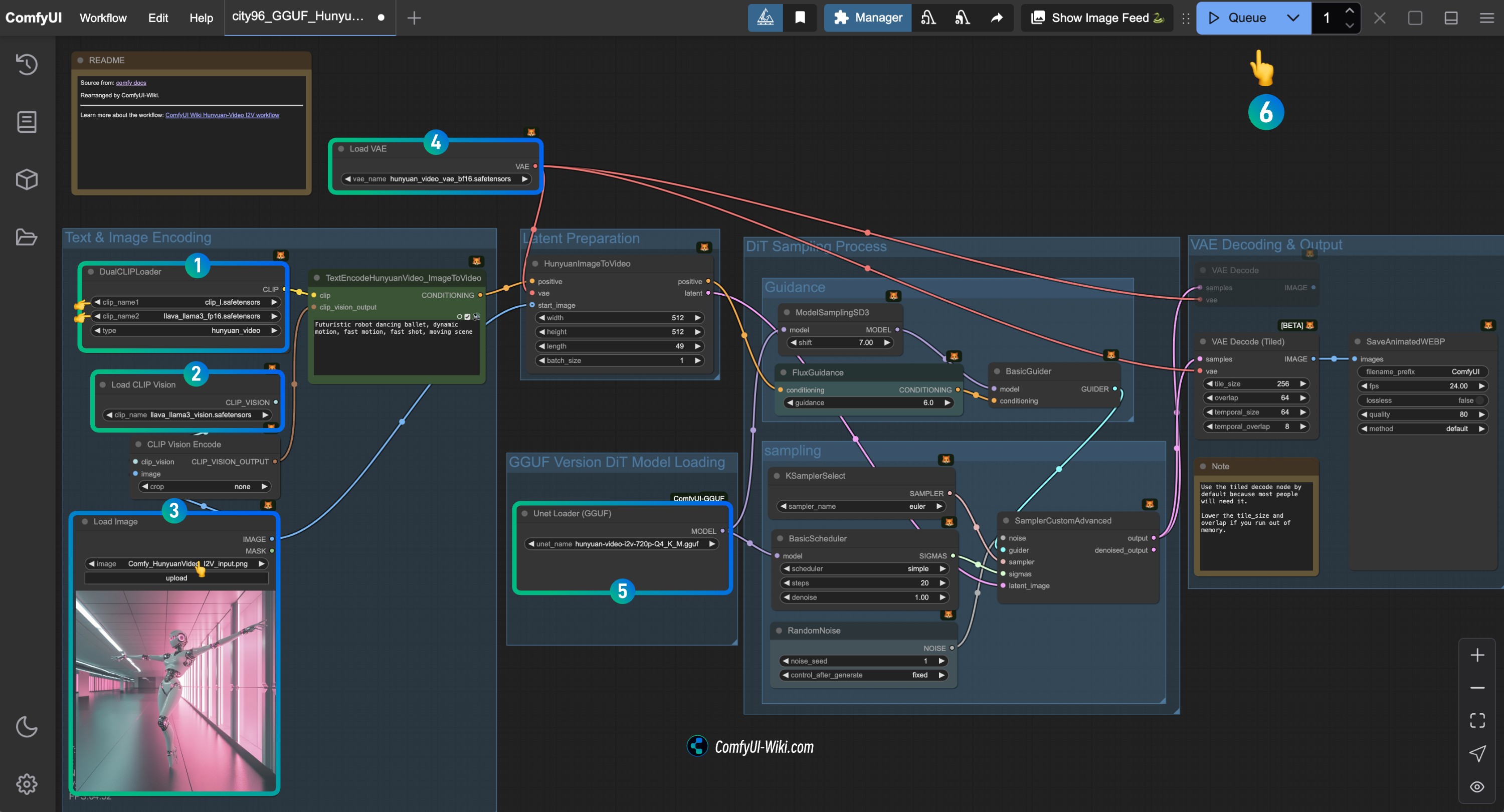
DualCLIPLoader노드 확인:
clip_name1: clip_l.safetensors가 올바르게 로드되었는지 확인clip_name2: llava_llama3_vision.safetensors가 올바르게 로드되었는지 확인
Load CLIP Vision노드 확인: llava_llama3_vision.safetensors가 올바르게 로드되었는지 확인Load Image노드에서 앞서 제공한 입력 이미지 업로드Load VAE노드 확인: hunyuan_video_vae_bf16.safetensors가 올바르게 로드되었는지 확인Load Diffusion Model노드 확인: 해당 HunyuanVideo GGUF 모델이 올바르게 로드되었는지 확인Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter를 사용하여 동영상 생성 실행
댓글
GitHub로 로그인하고 토론에 참여하세요.