ComfyUI Sonic 워크플로우, 디지털 사람 비디오 생성
텐센트 Sonic ComfyUI 워크플로우 상세 튜토리얼
Sonic은 텐센트 오픈 소스 디지털 사람 모델로, 이미지와 오디오만 입력하면 괜찮은 비디오 효과를 출력할 수 있습니다.
아래는 원본 Sonic 관련 링크입니다. 프로젝트 페이지: https://jixiaozhong.github.io/Sonic/ 온라인 체험: http://demo.sonic.jixiaozhong.online/ 프로젝트 소스코드: https://github.com/jixiaozhong/Sonic
최근 커뮤니티 사용자들이 해당 플러그인 통합을 완료하였으며, 본 튜토리얼은 ComfyUI_Sonic 플러그인을 기반으로 Sonic의 공식 예제 효과를 재현합니다.
1. ComfyUI Sonic 플러그인 설치
이 워크플로우는 아래 플러그인에 의존하므로, 시작하기 전에 플러그인 및 의존성 설치를 완료했거나 워크플로우를 다운로드한 후 ComfyUI-manager를 사용하여 누락된 노드를 설치했는지 확인하십시오.
ComfyUI_Sonic: https://github.com/smthemex/ComfyUI_Sonic ComfyUI-VideoHelperSuite: https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
해당 설치에 익숙하지 않다면 ComfyUI 플러그인 설치 튜토리얼을 참조하여 플러그인 설치를 완료하십시오.
2. Sonic 관련 모델의 다운로드 및 설치
플러그인 저장소 저자가 해당 플러그인 다운로드를 제공하고 있으며, 아래 모델 링크가 만료되었거나 접근할 수 없는 경우 플러그인 저자 저장소를 방문하여 업데이트가 있는지 확인하십시오.
모델을 저장해야 할 위치는 다음과 같습니다. 다운로드한 모델을 해당 위치에 저장하십시오:
📁ComfyUI
├── 📁models
│ ├── 📁checkpoints
│ │ └── 📁video // video 폴더는 주로 모델 분류를 위해 사용되며, 이 폴더를 만들지 않아도 됩니다.
│ │ └── svd_xt_1_1.safetensors // svd_xt.safetensors 또는 svd_xt_1_1.safetensors 모델 파일
│ └── 📁sonic // sonic 폴더를 새로 만들고, 모든 내용을 이 폴더에 저장합니다. 이 부분의 내용은 Google Drive에서 가져온 것입니다.
│ ├── 📁 whisper-tiny
│ │ ├── config.json
│ │ ├── model.safetensors
│ │ └── preprocessor_config.json
│ ├── 📁 RIFE
│ │ └── flownet.pkl
│ ├── audio2bucket.pth
│ ├── audio2token.pth
│ ├── unet.pth
│ └── yoloface_v5m.pt2.1 Stable video diffusion 아래 두 모델 중 하나를 선택하세요:
svd_xt_1_1.safetensors https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/tree/main svd_xt_1_1.safetensors https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/tree/main
2.2 Sonic 관련 모델 다운로드
아래의 구글 드라이브 주소를 방문하여 폴더 내 모든 리소스를 다운로드하세요. sonic 관련 모델: https://drive.google.com/drive/folders/1oe8VTPUy0-MHHW2a_NJ1F8xL-0VN5G7W
2.3 whisper-tiny 모델 다운로드
whisper-tiny https://huggingface.co/openai/whisper-tiny/tree/main
아래 세 개의 파일만 다운로드하세요.
- config.json
- model.safetensors
- preprocessor_config.json
ComfyUI Sonic 워크플로우 관련 자료
아래의 오디오, 사진 및 워크플로우 파일을 다운로드하거나 자신의 자료를 사용하세요.
이미지:

오디오, 예시 부분의 임의의 오디오를 다운로드하세요: https://github.com/smthemex/ComfyUI_Sonic/tree/main/examples/wav
ComfyUI Sonic 워크플로우 설명
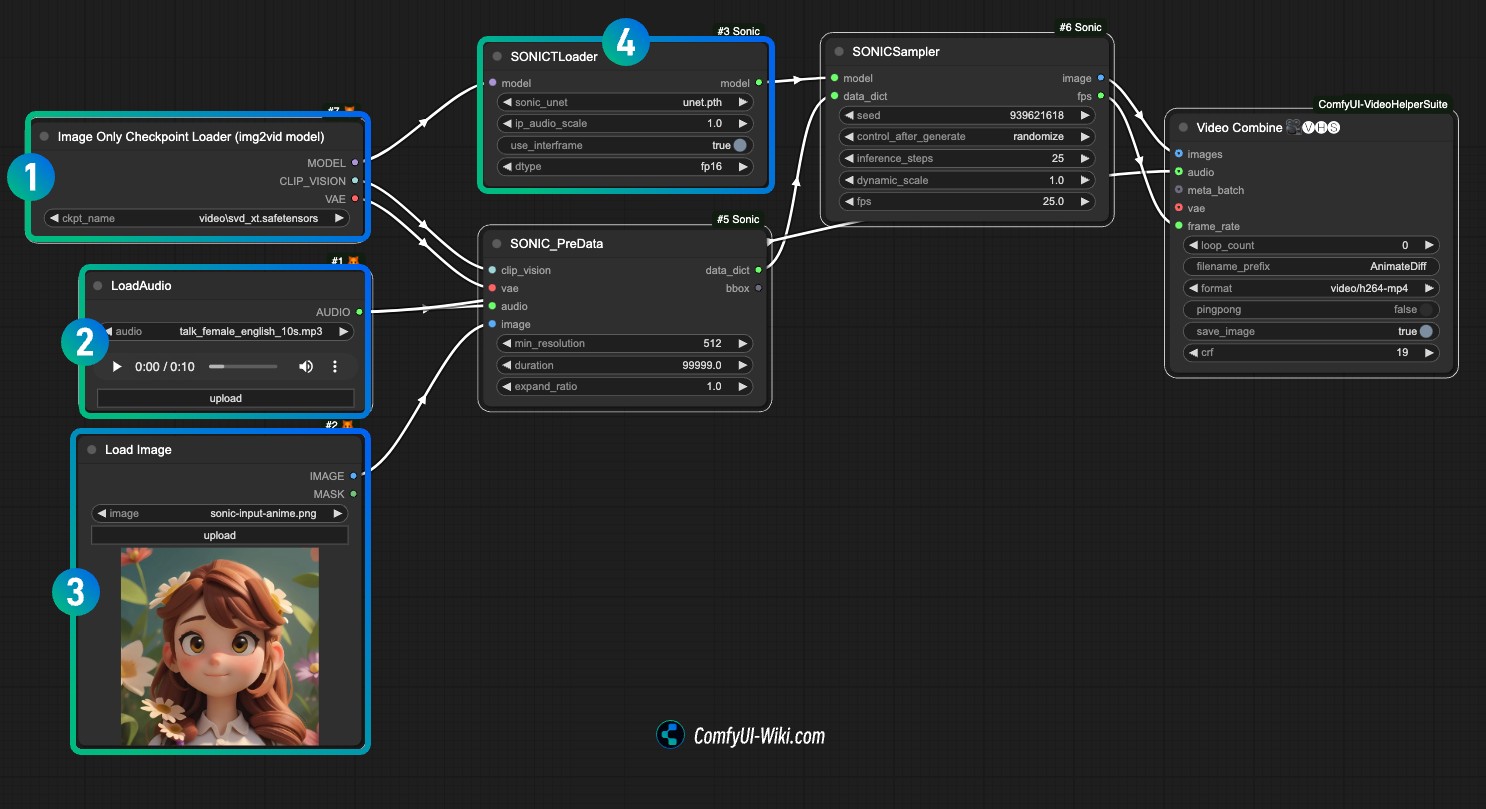
- 번호
1에서 stable video diffusion 관련 모델인 svd_xt_1_1.safetensors를 로드합니다. - 번호
2에서 오디오 파일을 업로드하여 오디오 파일을 로드합니다. - 번호
3에서 예시 이미지를 업로드합니다. - 번호
4에서 unet.pth 모델 파일을 로드합니다. - Queue를 사용하거나 단축키
Ctrl(Command)+Enter를 눌러 워크플로우를 실행하여 이미지를 생성합니다.
문제 해결
- transformers 버전 문제 해당 플러그인은 transformers==4.43.2를 사용해야 하므로, 만약 워크플로우가 정상적으로 작동하지 않는다면
📁ComfyUI
├── 📁custom_nodes
│ └── 📁ComfyUI_Sonic // 플러그인 디렉토리
│ └── requirements.txt // 의존성 파일requirements.txt 파일에서 다음을 수정하세요
#transformers ==4.43.2# 기호를 제거하세요
transformers ==4.43.2ComfyUI를 재시작하거나 pip를 사용하여 해당 의존성을 설치하세요.
- frame_rate 유형 불일치 문제
마지막 노드에서 숫자 유형 불일치 문제를 겪었고, primitive 노드를 입력으로 사용해 보았습니다.
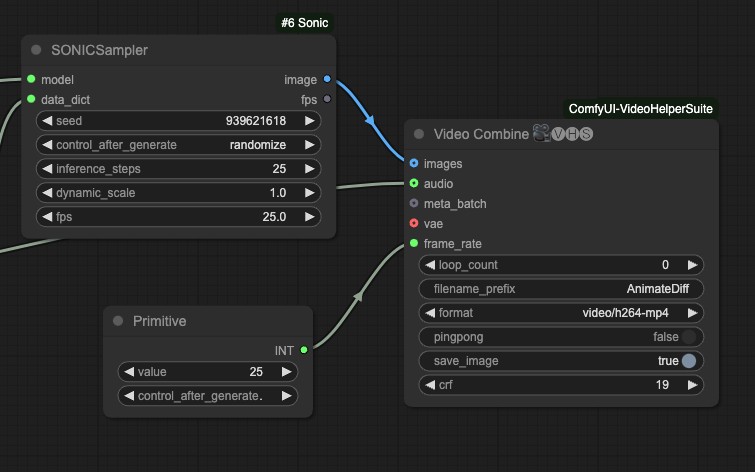
기타, 현재 이 워크플로우는 테스트 중이므로, 더 나은 해결책이 있다면 댓글로 남겨주세요. 이 튜토리얼에 즉시 업데이트하겠습니다.
댓글
GitHub로 로그인하고 토론에 참여하세요.