Wan2.1 ComfyUI 워크플로우 - 완벽 가이드
이 튜토리얼은 ComfyUI에서 Wan2.1 모델을 사용하는 방법을 자세히 설명합니다. 설치 구성, 워크플로우 사용 및 매개변수 조정 등의 내용을 포함하며, 텍스트 생성 비디오, 이미지 생성 비디오, 비디오 변환 비디오 등을 다룹니다.
알리바바가 2025년 2월에 오픈소스로 공개한 Wan2.1은 현재 비디오 생성 분야의 표준 모델입니다. Apache 2.0 라이선스로 제공되며, 14B(140억 매개변수)와 1.3B(13억 매개변수) 두 가지 버전으로 제공됩니다. 텍스트 생성 비디오(T2V), 이미지 생성 비디오(I2V) 등 다양한 작업을 지원합니다.
또한 현재 커뮤니티 저자들이 GGUF 및 양자화 버전을 제작했습니다.
- GGUF: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
- 양자화 버전: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
이 문서에서는 Wan2.1 관련 워크플로우를 안내합니다:
- ComfyUI에서 원주율 지원하는 Wan2.1 워크플로우
- Kijai의 버전
- City96의 GGUF 버전
ComfyUI/output 디렉토리에 저장됩니다.
Wan2.1은 480P와 720P 모델을 분리했지만, 해당 워크플로우는 모델과 캔버스 크기를 제외하고는 다른 차이가 없습니다. 따라서 720P 또는 480P 워크플로우에 따라 다른 버전의 워크플로우를 조정할 수 있습니다.
Wan2.1 ComfyUI 원주율 워크플로우 예시
다음 워크플로우는 ComfyUI 공식 블로그에서 가져온 것으로, 현재 ComfyUI가 Wan2.1을 원주율 지원합니다. 공식 원주율 지원 버전을 사용하려면 ComfyUI를 최신 버전으로 업그레이드하세요. ComfyUI 업그레이드 방법 섹션의 가이드를 참조하여 업그레이드를 완료하세요. ComfyUI Wiki에서는 원본 워크플로우를 정리했습니다.
ComfyUI를 최신 버전으로 업데이트한 후, 메뉴 바의 Workflows -> Workflow Templates에서 Wan2.1의 워크플로우 템플릿을 확인할 수 있습니다.
이 버전의 해당 워크플로우 파일은 모두 Comfy-Org/Wan_2.1_ComfyUI_repackaged에서 가져온 것입니다.
Diffusion models Comfy-org는 여러 버전을 제공합니다. 이 문서에서 사용된 공식 원주율 버전의 모델이 하드웨어 요구 사항이 높은 경우, 필요한 버전을 선택하여 사용할 수 있습니다.
- i2v는 image to video 즉 이미지 생성 비디오 모델, t2v는 text to video 즉 텍스트 생성 비디오 모델입니다.
- 14B, 1.3B는 해당 매개변수 수량으로, 수치가 클수록 하드웨어 성능 요구 사항이 높아집니다.
- bf16, fp16, fp8은 다양한 정밀도를 나타내며, 정밀도가 높을수록 하드웨어 성능 요구 사항이 높아집니다.
- bf16은 Ampere 아키텍처 이상의 GPU 지원이 필요할 수 있습니다.
- fp16은 더 널리 지원됩니다.
- fp8은 정밀도가 가장 낮아 하드웨어 성능 요구 사항이 가장 낮지만, 효과도 상대적으로 떨어집니다.
- 일반적으로 파일 크기가 클수록 장치의 하드웨어 요구 사항도 높아집니다.
1. Wan2.1 텍스트 생성 비디오 워크플로우
1.1 Wan2.1 텍스트 생성 비디오 워크플로우 파일 다운로드
아래 이미지를 다운로드하고 ComfyUI에 드래그하거나 메뉴 바의 Workflows -> Open(Ctrl+O)를 사용하여 워크플로우를 로드하세요.

Json 형식 파일 다운로드
1.2 수동 모델 설치
위의 워크플로우 파일로 모델 다운로드가 완료되지 않으면 아래 모델 파일을 다운로드하여 해당 위치에 저장하세요.
아래에서 하나의 Diffusion models 모델 파일을 선택하여 다운로드하세요.
- wan2.1_t2v_14B_bf16.safetensors
- wan2.1_t2v_14B_fp16.safetensors
- wan2.1_t2v_14B_fp8_e4m3fn.safetensors
- wan2.1_t2v_14B_fp8_scaled.safetensors
- wan2.1_t2v_1.3B_bf16.safetensors
- wan2.1_t2v_1.3B_fp16.safetensors
Text encoders에서 하나의 버전을 선택하여 다운로드하세요.
VAE
파일 저장 위치
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_t2v_14B_fp16.safetensors # 또는 선택한 버전
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 또는 선택한 버전
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 프로세스에 따라 워크플로우 실행 완료
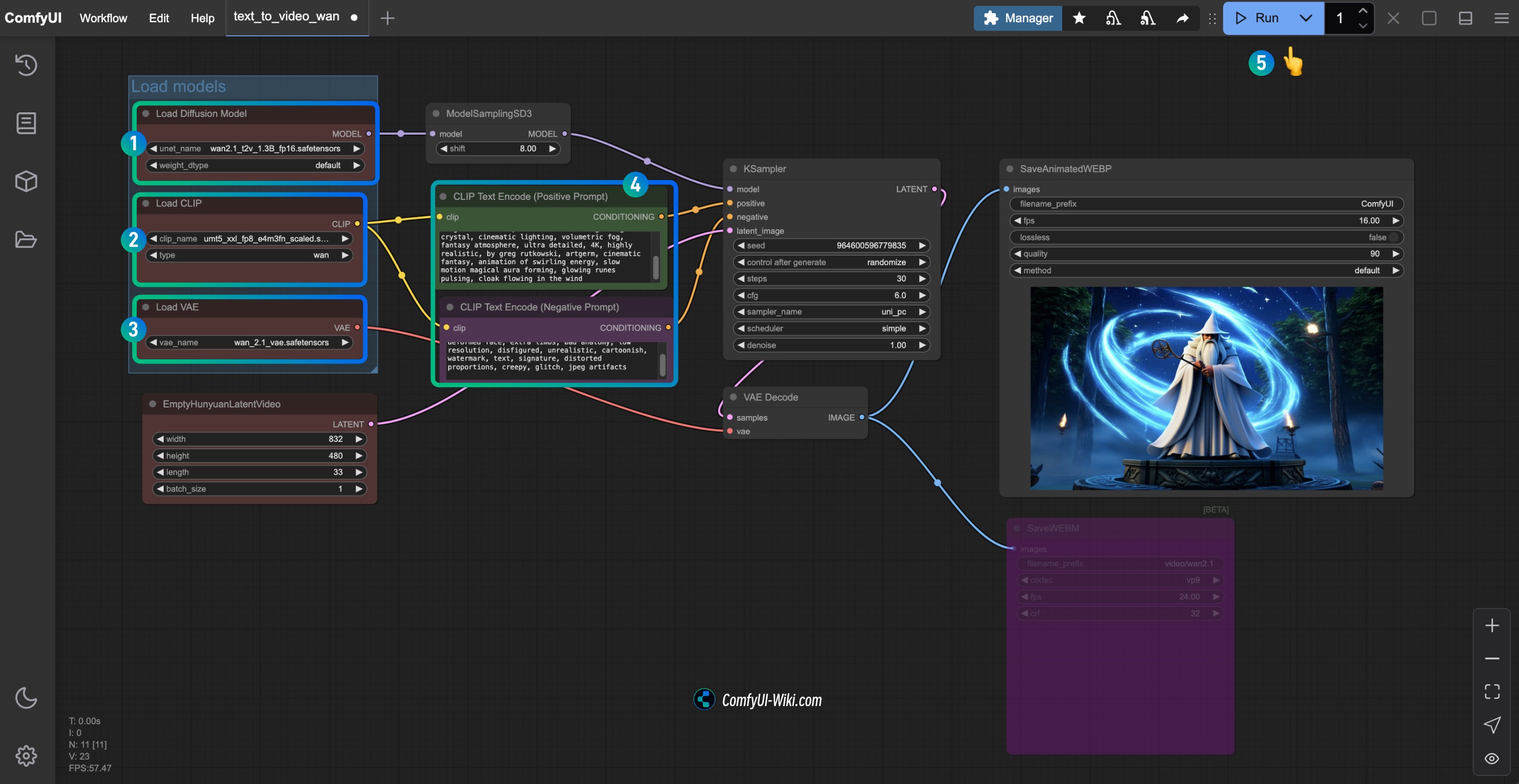
Load Diffusion Model노드가wan2.1_t2v_1.3B_fp16.safetensors모델을 로드했는지 확인하세요.Load CLIP노드가umt5_xxl_fp8_e4m3fn_scaled.safetensors모델을 로드했는지 확인하세요.Load VAE노드가wan_2.1_vae.safetensors모델을 로드했는지 확인하세요.CLIP Text Encoder노드에 생성하고자 하는 비디오 설명 내용을 입력할 수 있습니다.Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(엔터)를 사용하여 비디오 생성을 실행하세요.
2. Wan2.1 이미지 생성 비디오 워크플로우
2.1 Wan2.1 이미지 생성 비디오 워크플로우 14B
워크플로우 파일 다운로드
아래 버튼을 클릭하여 해당 워크플로우를 다운로드한 후, ComfyUI 인터페이스로 드래그하거나 메뉴 바의 Workflows -> Open(Ctrl+O)를 사용하여 로드하세요.

Json 형식 파일 다운로드
이 버전의 워크플로우는 480P 버전과 기본적으로 동일하지만, 사용되는 diffusion model이 다르며 WanImageToVideo 노드의 크기도 다릅니다.
아래 이미지를 다운로드하여 입력 이미지로 사용하세요.

2.2 수동 모델 다운로드
위의 워크플로우 파일로 모델 다운로드가 완료되지 않으면 아래 모델 파일을 다운로드하여 해당 위치에 저장하세요.
Diffusion models
720P 版本
- wan2.1_i2v_720p_14B_bf16.safetensors
- wan2.1_i2v_720p_14B_fp16.safetensors
- wan2.1_i2v_720p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_720p_14B_fp8_scaled.safetensors
480P 版本
- wan2.1_i2v_480p_14B_bf16.safetensors
- wan2.1_i2v_480p_14B_fp16.safetensors
- wan2.1_i2v_480p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_480p_14B_fp8_scaled.safetensors
Text encoders
VAE
CLIP Vision
파일 저장 위치
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_i2v_480p_14B_fp16.safetensors # 또는 선택한 버전
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 또는 선택한 버전
│ └── vae/
│ │ └── wan_2.1_vae.safetensors
│ └── clip_vision/
│ └── clip_vision_h.safetensors2.3 Wan2.1 480P 비디오 생성 워크플로우 완료하기
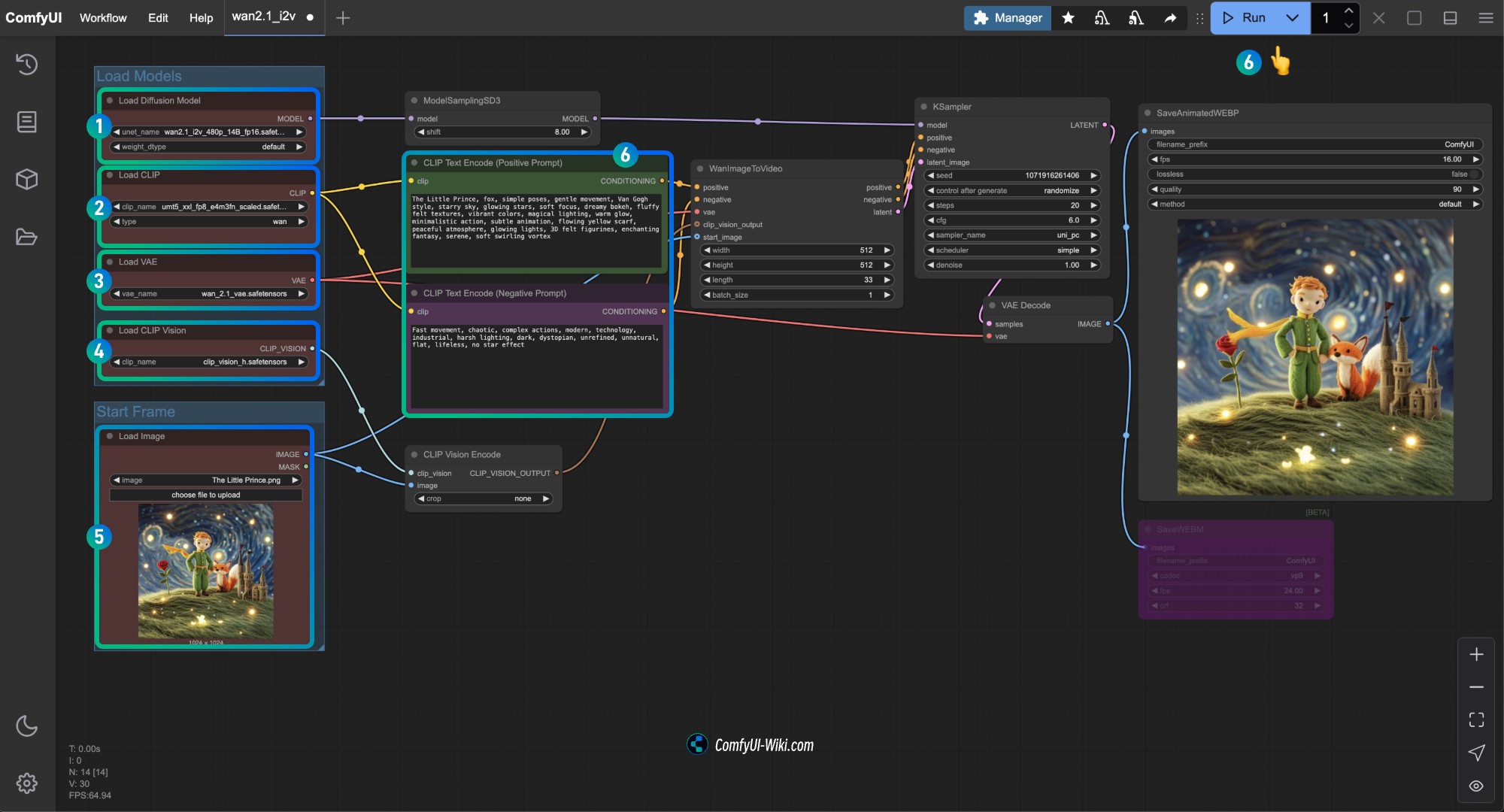
Load Diffusion Model노드가wan2.1_i2v_480p_14B_fp16.safetensors모델을 로드했는지 확인하세요.Load CLIP노드가umt5_xxl_fp8_e4m3fn_scaled.safetensors모델을 로드했는지 확인하세요.Load VAE노드가wan_2.1_vae.safetensors모델을 로드했는지 확인하세요.Load CLIP Vision노드가clip_vision_h.safetensors모델을 로드했는지 확인하세요.Load Image노드에 앞서 제공된 입력 이미지를 로드하세요.CLIP Text Encoder노드에 생성하고자 하는 비디오 설명 내용을 입력하거나 워크플로우의 예제를 사용하세요.Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(리턴)을 사용하여 비디오 생성을 실행하세요.
Kijai Wan2.1 양자화 버전 워크플로우
이 버전은 Kijai에서 제공하며, 다음 사용자 정의 노드와 함께 사용해야 합니다.
아래 세 개의 노드를 설치해야 합니다:
시작하기 전에 ComfyUI-Manager를 사용하거나 ComfyUI 사용자 정의 노드 설치 가이드를 참조하여 이 세 개의 사용자 정의 노드를 설치하세요.
모델 저장소: Kijai/WanVideo_comfy
이 저장소는 다양한 버전의 모델을 제공하므로, 장치 성능에 맞는 적절한 모델을 선택하세요. 일반적으로 파일 크기가 클수록 효과가 좋지만, 동시에 장치 성능 요구 사항도 높아집니다.
1. Kijai 텍스트 생성 이미지 워크플로우
1.1 Kijai Wan2.1 텍스트 생성 이미지 워크플로우 다운로드
아래 버튼을 클릭하여 해당 워크플로우를 다운로드한 후, ComfyUI 인터페이스로 드래그하거나 메뉴 바의 Workflows -> Open(Ctrl+O)를 사용하여 로드하세요.
위의 두 워크플로우 파일은 기본적으로 동일하며, 2번 파일에는 선택적 주석 정보가 추가되어 있습니다.
1.2 수동 모델 설치
Diffusion models
- Wan2_1-T2V-14B_fp8_e4m3fn.safetensors
- Wan2_1-T2V-14B_fp8_e5m2.safetensors
- Wan2_1-T2V-1_3B_fp32.safetensors
- Wan2_1-T2V-1_3B_bf16.safetensors
- Wan2_1-T2V-1_3B_fp8_e4m3fn.safetensors
Text encoders
VAE
파일 저장 위치
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-T2V-14B_fp8_e4m3fn.safetensors # 또는 선택한 버전
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # 또는 선택한 버전
│ └─── vae/
│ └── Wan2_1_VAE_bf16.safetensors # 또는 선택한 버전1.3 단계별로 워크플로우 실행하기
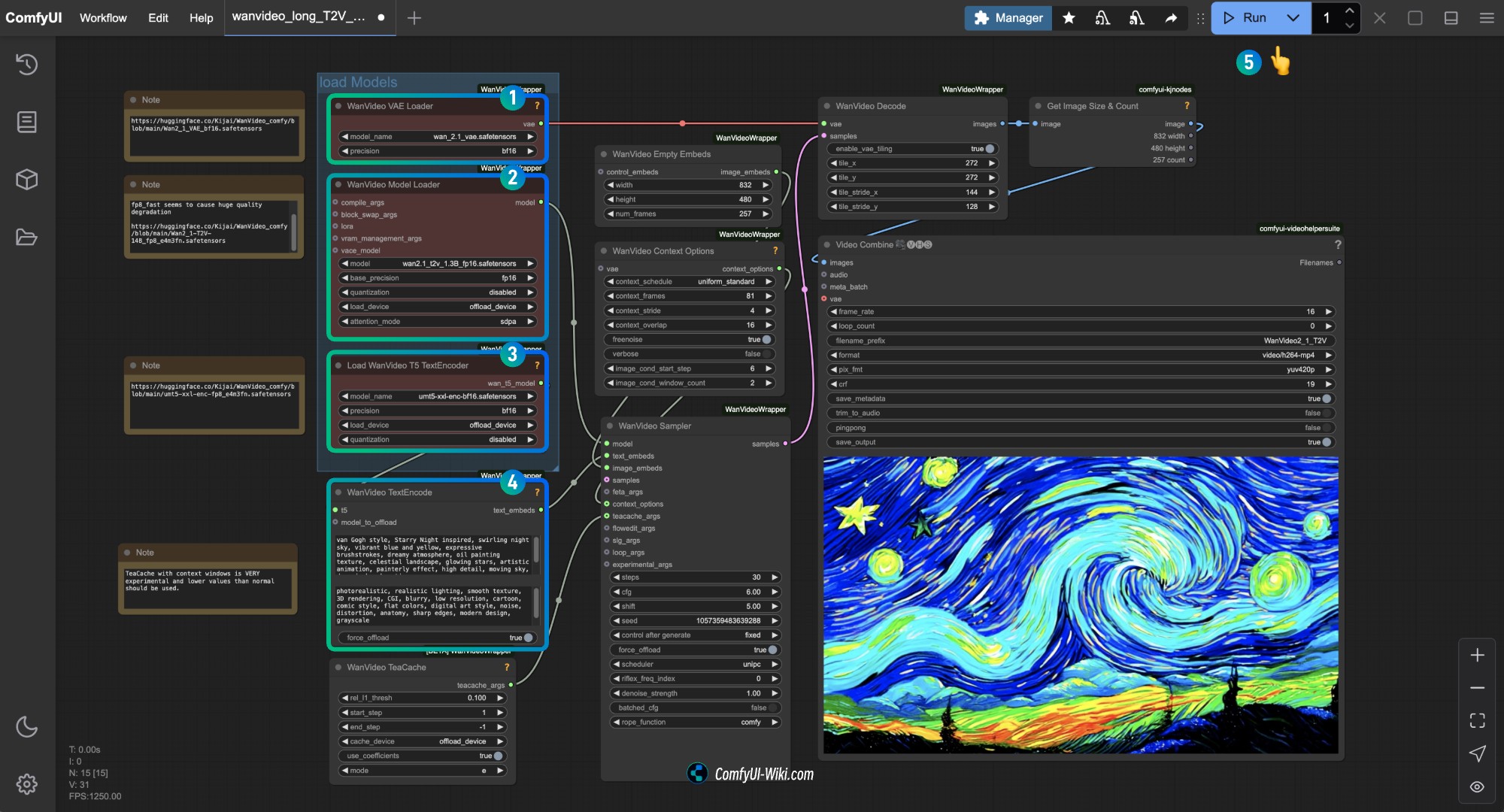
해당 노드에 적절한 모델이 로드되었는지 확인하고, 다운로드한 버전을 사용하세요.
WanVideo Vae Loader노드에Wan2_1_VAE_bf16.safetensors모델이 로드되었는지 확인합니다.WanVideo Model Loader노드에Wan2_1-T2V-14B_fp8_e4m3fn.safetensors모델이 로드되었는지 확인합니다.Load WanVideo T5 TextEncoder노드에umt5-xxl-enc-bf16.safetensors모델이 로드되었는지 확인합니다.WanVideo TextEncode에서 생성하고자 하는 비디오 화면의 프롬프트를 입력합니다.Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(엔터)를 사용하여 비디오 생성을 실행합니다.
WanVideo Empty Embeds에서 크기를 수정하여 화면 크기를 조정할 수 있습니다.
2. Kiai Wan2.1 이미지 생성 비디오 워크플로우
2.1 워크플로우 파일 다운로드
아래 이미지를 다운로드하여 입력 이미지로 사용합니다.

2.2 수동 모델 다운로드
Diffusion models
720P 버전
480P 버전
Text encoders
VAE
CLIP Vision
파일 저장 위치
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors # 또는 선택한 버전
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # 또는 선택한 버전
│ ├── vae/
│ │ └── Wan2_1_VAE_fp32.safetensors # 또는 선택한 버전
│ └── clip_vision/
│ └── clip_vision_h.safetensors2.3 단계별로 워크플로우 실행하기
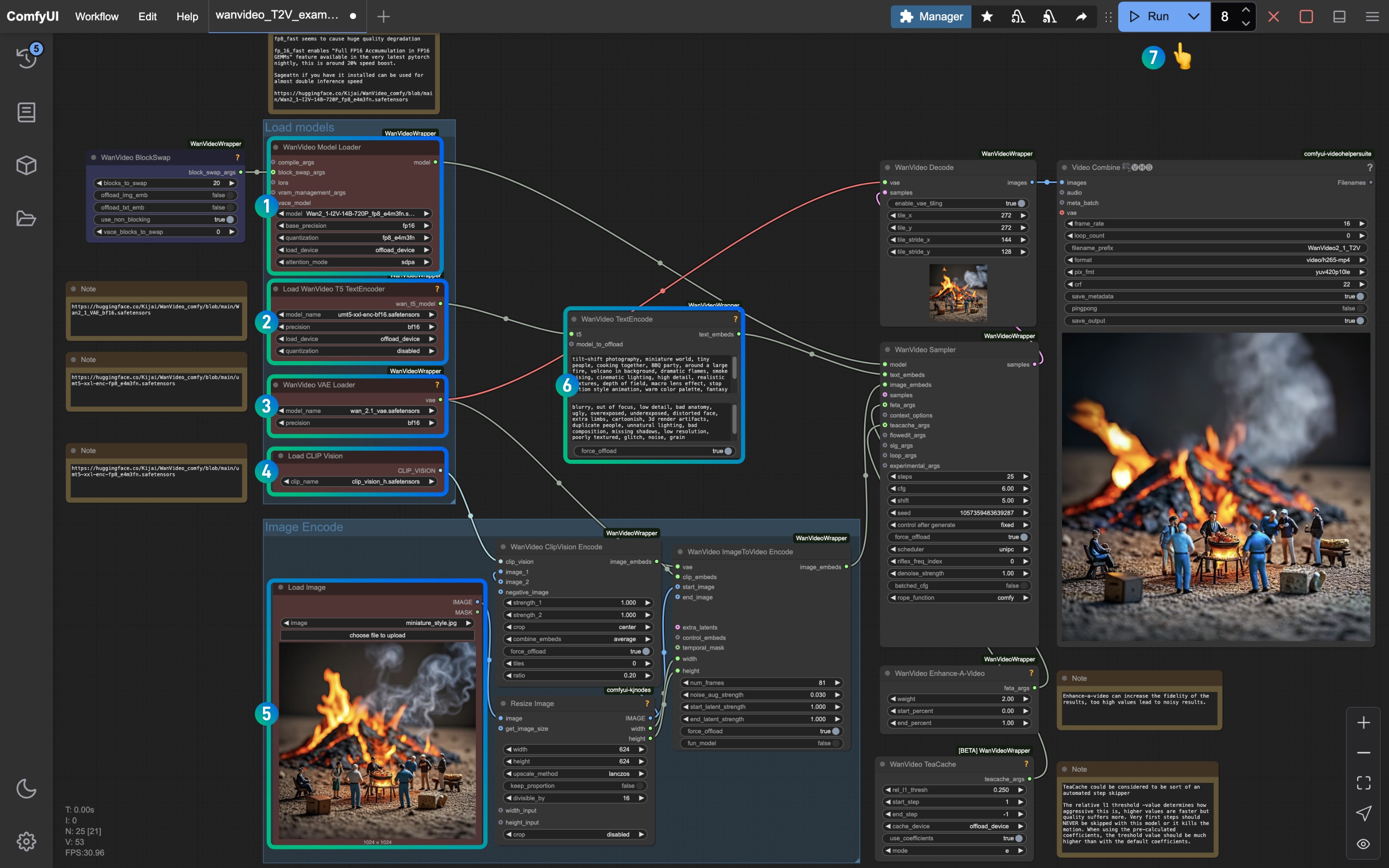
이미지 번호를 참조하여 각 노드와 모델이 올바르게 로드되었는지 확인하여 모델이 정상적으로 작동하도록 합니다.
WanVideo Model Loader노드가Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors모델을 로드했는지 확인합니다.Load WanVideo T5 TextEncoder노드가umt5-xxl-enc-bf16.safetensors모델을 로드했는지 확인합니다.WanVideo Vae Loader노드가Wan2_1_VAE_fp32.safetensors모델을 로드했는지 확인합니다.Load CLIP Vision노드가clip_vision_h.safetensors모델을 로드했는지 확인합니다.Load Image노드에 앞서 제공한 입력 이미지를 로드합니다.- 기본값을 저장하거나
WanVideo TextEncode프롬프트를 수정하여 화면 효과를 조정합니다. Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(리턴)을 사용하여 비디오 생성을 실행합니다.
Wan2.1 GGUF 버전 워크플로우
이 부분에서는 GGUF 버전 모델을 사용하여 비디오 생성을 완료합니다. 모델 저장소: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
해당 모델을 로드하기 위해 ComfyUI-GGUF가 필요합니다. 시작하기 전에 ComfyUI-Manager를 사용하거나 ComfyUI 사용자 정의 노드 설치 가이드를 참조하여 필요한 사용자 정의 노드를 설치합니다.
1. Wan2.1 GGUF 버전 텍스트 생성 비디오 워크플로우
1.1 워크플로우 파일 다운로드

1.2 수동 모델 다운로드
아래에서 하나의 Diffusion models 모델 파일을 선택하여 다운로드합니다. city96은 다양한 버전의 모델을 제공하므로, https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main 에서 적합한 버전을 다운로드하세요. 일반적으로 파일 크기가 클수록 효과가 좋지만, 동시에 장치 성능 요구 사항도 높아집니다.
Text encoders에서 하나의 버전을 선택하여 다운로드합니다.
VAE
파일 저장 위치
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-t2v-14b-Q4_K_M.gguf # 또는 선택한 버전
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 또는 선택한 버전
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 단계별로 워크플로우 실행하기
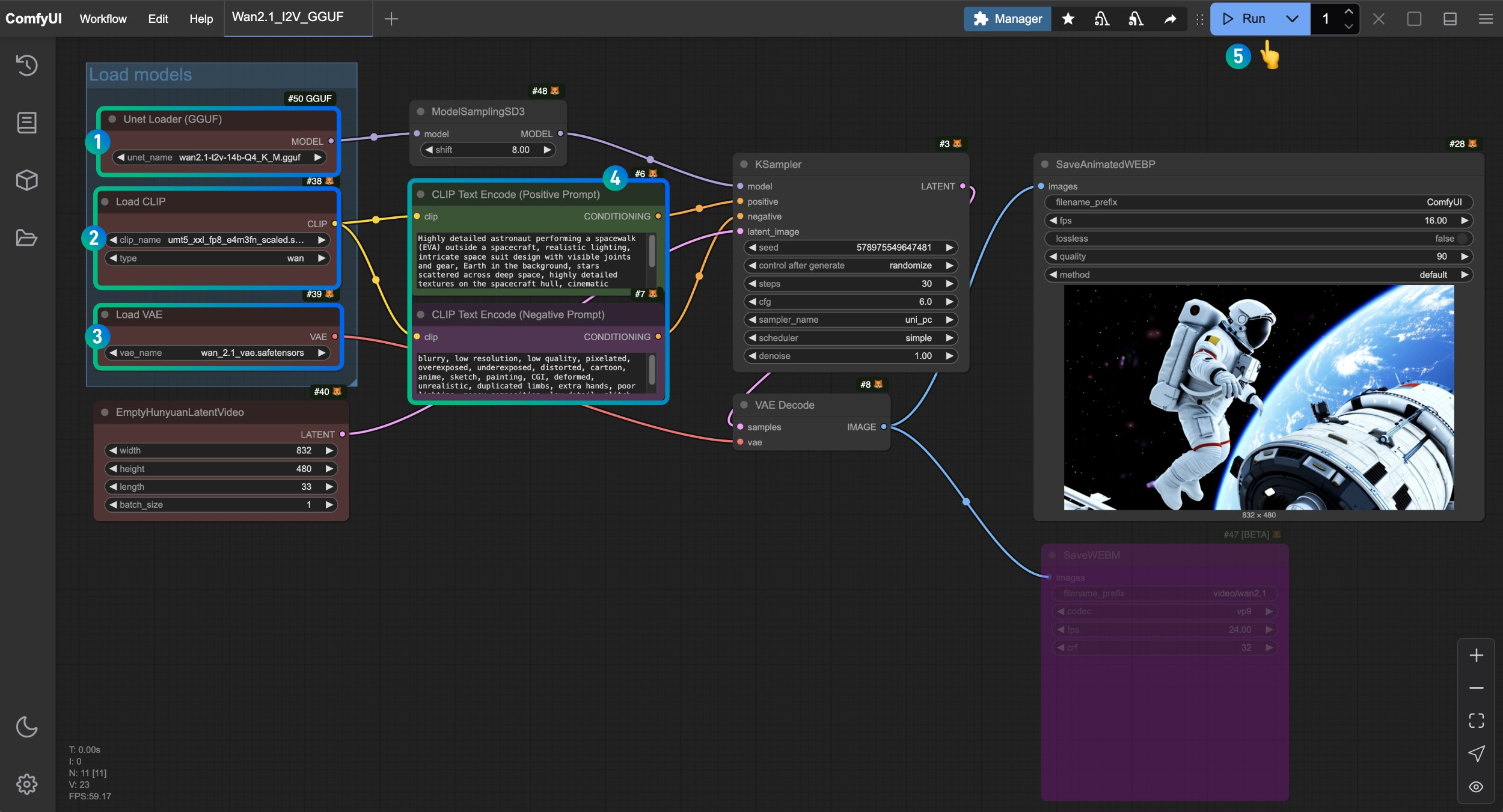
Unet Loader(GGUF)노드가wan2.1-t2v-14b-Q4_K_M.gguf모델을 로드했는지 확인합니다.Load CLIP노드가umt5_xxl_fp8_e4m3fn_scaled.safetensors모델을 로드했는지 확인합니다.Load VAE노드가wan_2.1_vae.safetensors모델을 로드했는지 확인합니다.CLIP Text Encoder노드에 생성하고자 하는 비디오 설명 내용을 입력할 수 있습니다.Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(리턴)을 사용하여 비디오 생성을 실행합니다.
2. Wan2.1 GGUF 버전 이미지 생성 비디오 워크플로우
2.1 워크플로우 파일 다운로드

2.2 수동 모델 다운로드
아래에서 하나의 Diffusion models 모델 파일을 선택하여 다운로드합니다. city96은 다양한 버전의 모델을 제공하므로, 해당 저장소를 방문하여 적합한 버전을 다운로드하세요. 일반적으로 파일 크기가 클수록 효과가 좋지만, 동시에 장치 성능 요구 사항도 높아집니다.
여기서는 wan2.1-i2v-14b-Q4_K_M.gguf 모델을 사용하여 예제를 완료합니다.
Text encoders에서 하나의 버전을 선택하여 다운로드합니다.
VAE
파일 저장 위치
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-i2v-14b-Q4_K_M.gguf # 또는 선택한 버전
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 또는 선택한 버전
│ └── vae/
│ └── wan_2.1_vae.safetensors2.3 단계별로 워크플로우 실행하기
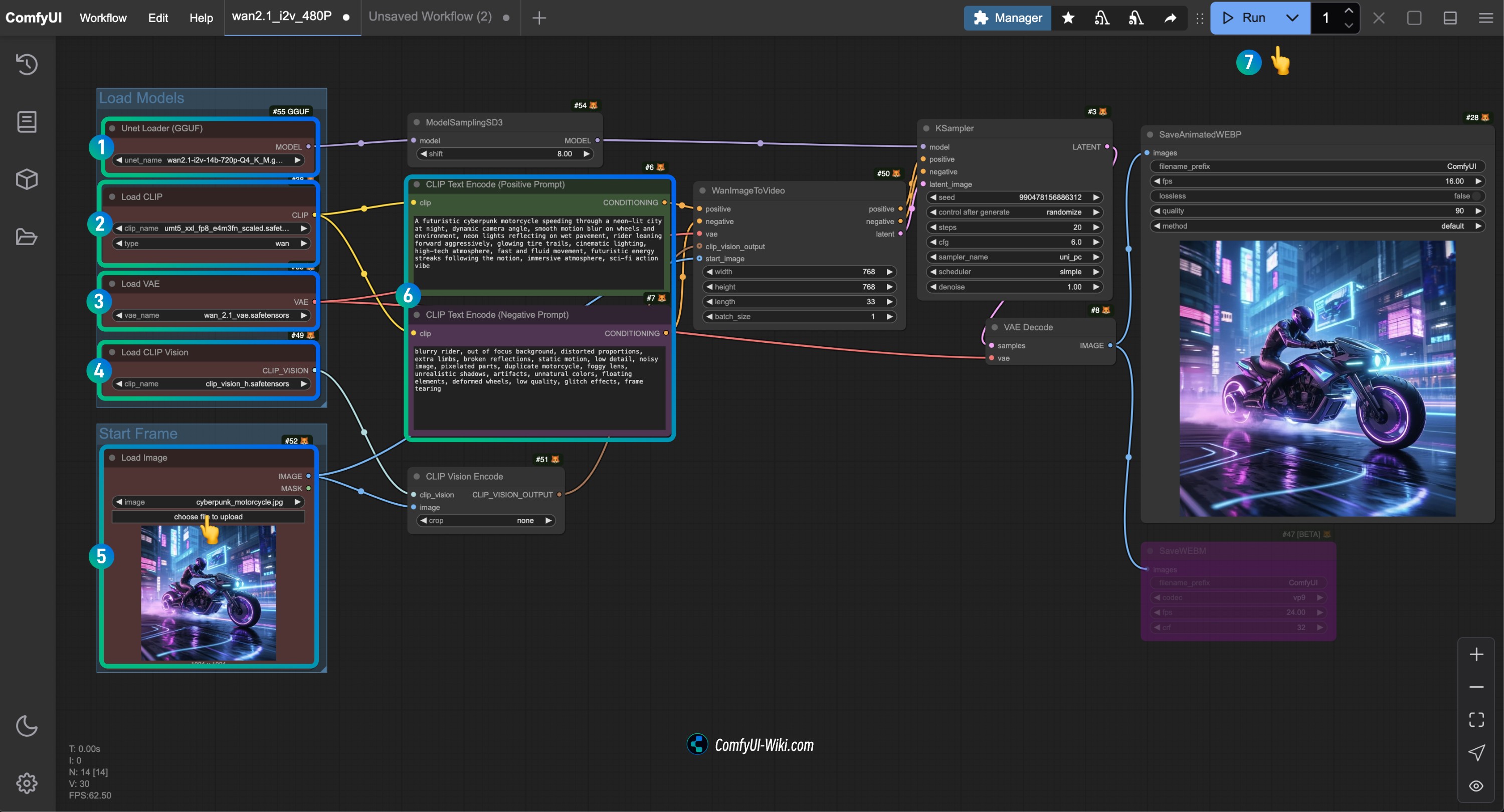
Unet Loader(GGUF)노드가wan2.1-i2v-14b-Q4_K_M.gguf모델을 로드했는지 확인합니다.Load CLIP노드가umt5_xxl_fp8_e4m3fn_scaled.safetensors모델을 로드했는지 확인합니다.Load VAE노드가wan_2.1_vae.safetensors모델을 로드했는지 확인합니다.Load CLIP Vision노드가clip_vision_h.safetensors모델을 로드했는지 확인합니다.Load Image노드에 앞서 제공된 입력 이미지를 로드합니다.CLIP Text Encoder노드에 생성하고자 하는 비디오 설명 내용을 입력하거나 워크플로우의 예제를 사용합니다.Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter(리턴)을 사용하여 비디오 생성을 실행합니다.
자주 묻는 질문
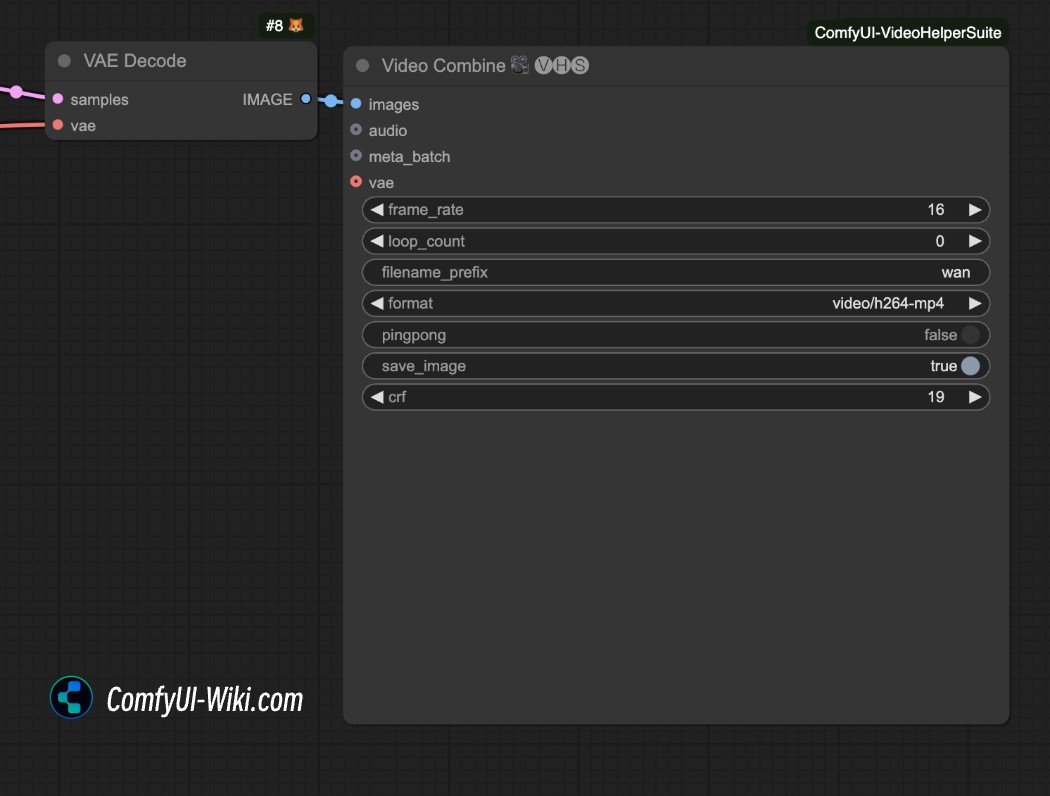
mp4 형식으로 비디오를 저장하려면 어떻게 해야 하나요?
위의 비디오 생성 워크플로우는 기본적으로 .webp 형식의 비디오를 생성합니다. 다른 형식의 비디오로 저장하고 싶다면 ComfyUI-VideoHelperSuite 플러그인의 video Combine 노드를 사용하여 mp4 형식으로 저장해 보세요.
관련 리소스
현재 모든 모델은 Hugging Face와 ModelScope 플랫폼에서 다운로드할 수 있습니다:
댓글
GitHub로 로그인하고 토론에 참여하세요.