Tencent Hunyuan 팀, 인간 선호도 정렬 훈련 효율성 향상을 위한 MixGRPO 프레임워크 오픈소스 공개
Tencent Hunyuan 팀이 GRPO에 슬라이딩 윈도우 혼합 ODE-SDE 샘플링을 통합한 최초의 프레임워크인 MixGRPO를 오픈소스로 출시. 확산 모델과 플로우 모델의 인간 선호도 정렬에서 최대 71%의 훈련 가속화를 달성.
Tencent Hunyuan 팀이 MixGRPO 프레임워크를 공식적으로 오픈소스로 공개했습니다! 이는 GRPO(Generalized Reward-based Policy Optimization)에 슬라이딩 윈도우 혼합 ODE-SDE 샘플링을 통합한 최초의 프레임워크로, AI 모델의 인간 선호도 정렬 효율성을 향상시키기 위해 특별히 설계되었습니다.
이 프레임워크는 우수한 성능을 유지하면서 훈련 오버헤드를 크게 감소시킵니다. MixGRPO-Flash 변형은 최대 71%의 훈련 가속화를 달성하여 DanceGRPO 등 기존 방법을 능가합니다.
 다양한 최적화된 노이즈 제거 단계 수에 대한 성능 비교. DanceGRPO의 성능 향상은 더 많은 최적화 단계에 의존하는 반면, MixGRPO는 단 4단계로 최적 성능을 달성
다양한 최적화된 노이즈 제거 단계 수에 대한 성능 비교. DanceGRPO의 성능 향상은 더 많은 최적화 단계에 의존하는 반면, MixGRPO는 단 4단계로 최적 성능을 달성
MixGRPO 프레임워크 특징
핵심 기술 혁신
- 슬라이딩 윈도우 혼합 샘플링: GRPO에 슬라이딩 윈도우 혼합 ODE-SDE 샘플링을 통합한 최초의 프레임워크
- 상당한 효율성 향상: MixGRPO-Flash는 최대 71%의 훈련 가속화 달성
- 고차 솔버 지원: 추가 가속화를 위한 고차 ODE 솔버 지원
- 범용 호환성: 확산 모델과 플로우 모델 모두에 적용 가능
 MixGRPO의 기술 아키텍처 다이어그램, 슬라이딩 윈도우 메커니즘의 작동 원리를 보여줌
MixGRPO의 기술 아키텍처 다이어그램, 슬라이딩 윈도우 메커니즘의 작동 원리를 보여줌
성능 우위
- 훈련 오버헤드의 대폭 감소: 기존 방법 대비 계산 자원 소비를 크게 감소
- 기존 방법 대비 우수: DanceGRPO 등 기존 방법을 효과성과 효율성 모두에서 능가
- 빠른 수렴: 소수의 반복 단계로 모델 잠재력 달성
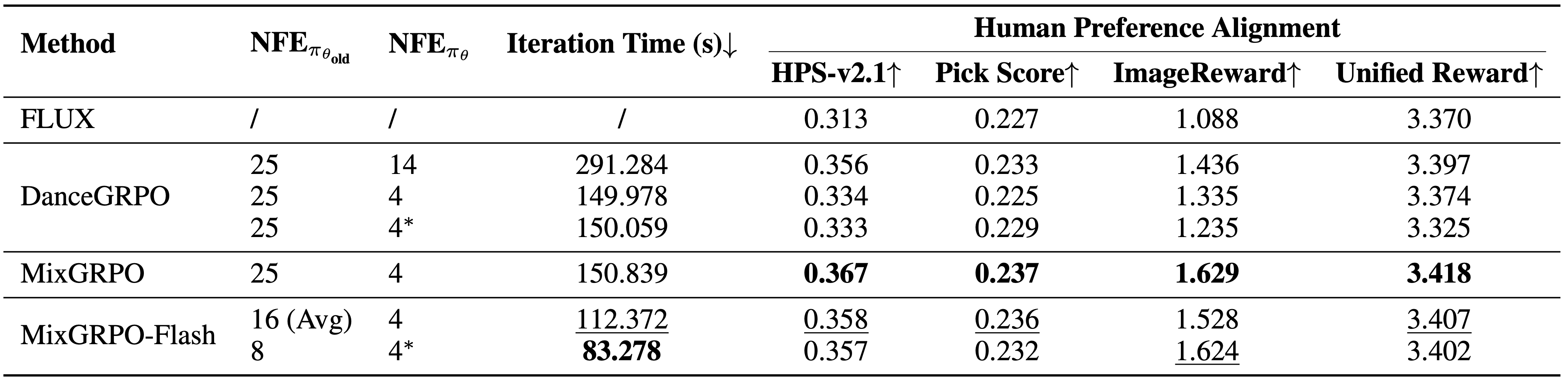 오버헤드와 성능 비교 결과. MixGRPO는 여러 지표에서 최고 성능을 달성하며, MixGRPO-Flash는 DanceGRPO를 능가하면서 샘플링 시간을 크게 단축
오버헤드와 성능 비교 결과. MixGRPO는 여러 지표에서 최고 성능을 달성하며, MixGRPO-Flash는 DanceGRPO를 능가하면서 샘플링 시간을 크게 단축
기술 적용 시나리오
MixGRPO 프레임워크는 주로 인간 선호도 정렬 작업에 사용되며, 이는 AI 분야의 중요한 연구 방향입니다. 이 프레임워크를 통해 연구자들은 다음과 같은 작업이 가능합니다:
- 인간 선호도에 더 잘 맞는 이미지 생성 모델을 더 효율적으로 훈련
- 대규모 모델 훈련의 계산 비용 감소
- 모델 품질을 유지하면서 실험 반복 가속화
이 기술은 AI 생성 콘텐츠의 품질과 사용자 만족도 향상에 중요한 의미를 갖습니다. 특히 이미지 생성과 콘텐츠 제작 애플리케이션에서 그렇습니다.
실험 결과
 정성적 비교 결과. MixGRPO는 의미론과 미학 모두에서 우수한 성능을 달성
정성적 비교 결과. MixGRPO는 의미론과 미학 모두에서 우수한 성능을 달성
 다양한 훈련 시점 샘플링 단계에 대한 정성적 비교. MixGRPO의 성능은 오버헤드 감소와 함께 크게 저하되지 않음
다양한 훈련 시점 샘플링 단계에 대한 정성적 비교. MixGRPO의 성능은 오버헤드 감소와 함께 크게 저하되지 않음
 다양한 전략으로 샘플링된 이미지의 t-SNE 시각화. 노이즈 제거 과정의 초기 단계에서 SDE 샘플링을 사용하면 더 이산적인 데이터 분포가 생성됨
다양한 전략으로 샘플링된 이미지의 t-SNE 시각화. 노이즈 제거 과정의 초기 단계에서 SDE 샘플링을 사용하면 더 이산적인 데이터 분포가 생성됨
오픈소스 리소스
MixGRPO 프레임워크는 현재 완전히 오픈소스입니다. 연구자와 개발자는 다음 채널을 통해 관련 리소스에 액세스할 수 있습니다:
관련 링크
- 프로젝트 페이지: https://tulvgengenr.github.io/MixGRPO-Project-Page/
- 코드 저장소: https://github.com/Tencent-Hunyuan/MixGRPO
- 연구 논문: https://arxiv.org/abs/2507.21802
MixGRPO의 오픈소스화는 AI 연구 커뮤니티에 강력한 도구 지원을 제공하여 인간 선호도 정렬 기술의 추가 개발과 적용을 촉진할 것입니다.
댓글
GitHub로 로그인하고 토론에 참여하세요.