Lumina Image 2.0 ComfyUI 워크플로우 예제
Lumina Image 2.0 모델의 ComfyUI 사용법에 대한 상세 가이드로, 모델 설치, 워크플로우 구성 및 매개변수 최적화 팁을 포함합니다.
 Lumina-Image-2.0은 Alpha-VLLM 팀이 2025년 설날 기간 동안 오픈소스로 공개한 텍스트-투-이미지 모델입니다. 2.6B 매개변수를 가지고 있으며 DiT 아키텍처를 기반으로 하여 이미지 품질, 레이아웃, 프롬프트 이해 등 다양한 측면에서 우수한 성능을 보여줍니다.
Lumina-Image-2.0은 Alpha-VLLM 팀이 2025년 설날 기간 동안 오픈소스로 공개한 텍스트-투-이미지 모델입니다. 2.6B 매개변수를 가지고 있으며 DiT 아키텍처를 기반으로 하여 이미지 품질, 레이아웃, 프롬프트 이해 등 다양한 측면에서 우수한 성능을 보여줍니다.
Lumina-Image-2.0 Github: https://github.com/Alpha-VLLM/Lumina-Image-2.0 Lumina-Image-2.0 huggingface: https://huggingface.co/Alpha-VLLM/Lumina-Image-2.0 온라인 데모 1(중국어): https://magic-animation.intern-ai.org.cn/image/create 온라인 데모(Gradio): http://47.100.29.251:10010/
이 글에서는 ComfyUI Example을 기반으로 한 예제를 설명하겠습니다.
Lumina Image 2.0 워크플로우 예제
1. Lumina Image 2.0 모델 다운로드 및 설치
| 이름 | 크기 | 설치 위치 | 다운로드 링크 |
|---|---|---|---|
| Lumina Image 2.0 | 10.6GB | ComfyUI/models/checkpoints | 다운로드 |
📁ComfyUI
└── 📁models
└── 📁checkpoints
└── lumina_2.safetensors // 모델을 이 파일 위치에 저장하십시오.2. Lumina Image 2.0 ComfyUI 워크플로우
아래 버튼을 클릭하여 해당 ComfyUI 워크플로우를 다운로드하고 ComfyUI로 열어주세요
Lumina Image 2.0 워크플로우 설명
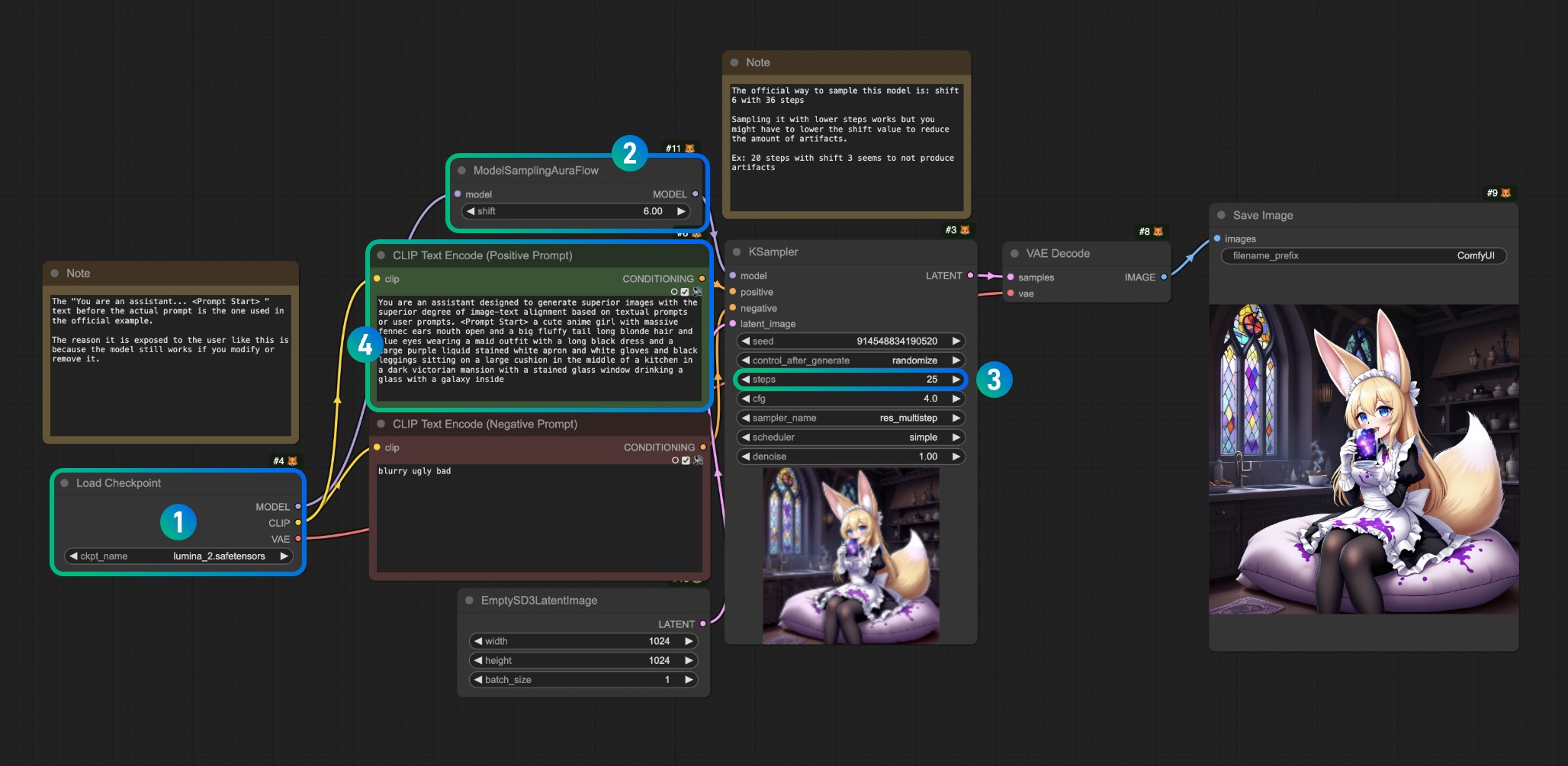
이미지를 참고하여 각 번호에 해당하는 작업을 수행해 주세요
- Load Checkpoint에서
lumina_2.safetensors모델이 정상적으로 로드되었는지 확인하세요. 해당 모델이 없는 경우 모델 위치를 확인하거나 ComfyUI를 새로고침/재시작하세요
해당 모델을 로드한 후 Queue 또는 단축키 Ctrl(Command)+Enter를 사용하여 워크플로우를 실행하여 이미지를 생성합니다
번호 3의 샘플링 스텝 수를 수정하는 경우 번호 2의 오프셋을 비례적으로 조정할 수 있습니다
예시:
- 스텝 36은 시프트 6에 해당
- 스텝 20은 시프트 3에 해당