OpenMOSS, MOVA 출시 - 오픈소스 동영상·오디오 동기화 생성 모델
2026. 01. 29.
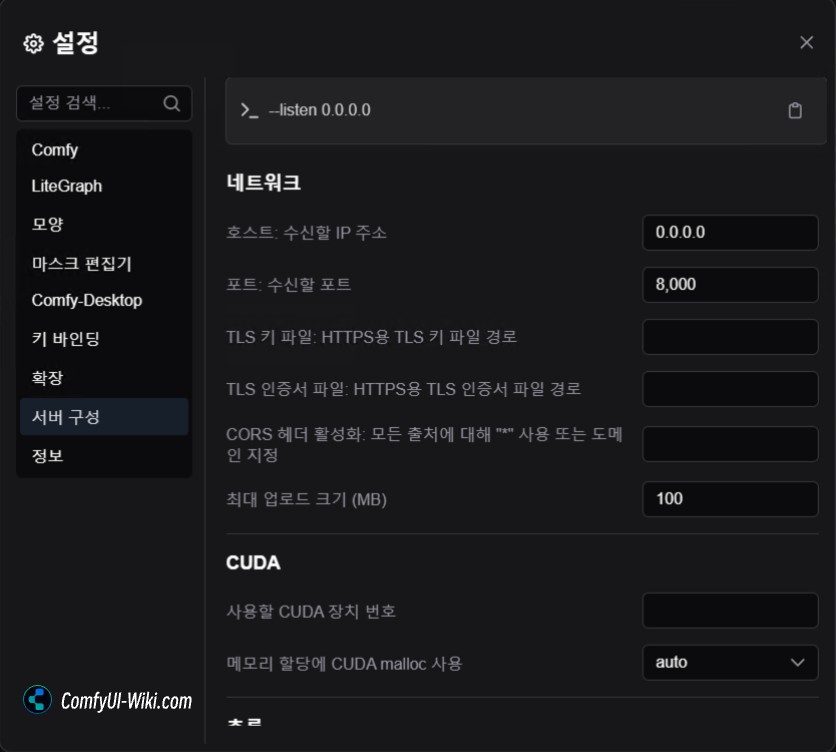
ComfyUI 서비스 구성 설명
현재 버전: ComfyUI Desktop v0.4.5
서버 구성은 ComfyUI Desktop의 서버 측(호스트 측)에서 수행되며, 여기서 ComfyUI의 LAN 액세스 설정, 다양한 정밀도 설정 및 캐시 설정 등을 구성할 수 있습니다. LAN의 다른 장치에서 액세스할 때는 이러한 설정을 수정할 수 없습니다.
네트워크
ComfyUI는 네트워크를 통한 서버 접근을 차단하지 않지만, 데스크톱 앱을 서버로 실행하는 것은 의도된 용도가 아닙니다. Electron은 이러한 용도에 전혀 적합하지 않습니다.
-
호스트 (listen)
- 기능: 서버가 수신할 IP 주소 설정
- 기본값:
127.0.0.1(로컬호스트만 접근 가능)
-
포트 (port)
- 기능: 서버가 수신할 포트 번호 설정
- 기본값:
8000(소프트웨어 충돌이 있는 경우에만 변경 필요)
-
TLS 키 파일 (tls-keyfile) 및 TLS 인증서 파일 (tls-certfile)
- 기능: HTTPS 보안 연결 설정용. HTTPS가 필요하지 않은 경우 무시 가능
-
CORS 헤더 활성화 (enable-cors-header)
- 기능: 다른 웹사이트의 서버 접근 허용. ”*“를 사용하여 모든 출처 허용
-
최대 업로드 크기 (max-upload-size)
- 기능: 파일 업로드의 최대 크기 제한 (MB 단위)
- 기본값:
100
CUDA 설정
-
CUDA 장치 (cuda-device)
- 기능: 사용할 GPU 선택
- 옵션:
- 0: 첫 번째 GPU
- 1: 두 번째 GPU (있는 경우)
- null: 자동 선택
- 권장: 단일 GPU 사용자는 기본값 유지
-
CUDA malloc 사용 (cuda-malloc)
- 기능: GPU 메모리 할당 방식 결정
- 옵션:
옵션 설명 사용 사례 자동 시스템이 최적의 방법 결정 초보자 권장 활성화 적극적인 메모리 할당 사용 VRAM이 더 필요할 때 비활성화 보수적인 메모리 할당 사용 VRAM 문제 발생 시
추론
-
전역 부동 소수점 정밀도 (global-precision)
- 기능: 전체 연산의 정밀도 제어
- 옵션:
옵션 설명 사용 사례 AUTO 최적의 정밀도 자동 선택 대부분의 경우 적합 FP32 최고 정밀도 모드 최상의 이미지 품질 필요 시 FP16 낮은 정밀도, 더 빠른 속도 빠른 생성이 필요할 때
-
UNET 정밀도 (unet-precision)
- 기능: AI 그림 그리기의 핵심 부분 정밀도 제어
- 옵션:
옵션 설명 사용 사례 AUTO 자동 선택, 초보자 권장 대부분의 경우 적합 FP32 최고 품질, 속도 느림 최상의 품질 필요 시 FP16 균형 모드, 중간 속도와 품질 일상적 사용 BF16 특별한 균형 모드 특정 새 GPU용
-
VAE 정밀도 (vae-precision)
- 기능: 최종 이미지 세부 처리 제어
- 옵션:
옵션 설명 사용 사례 AUTO 적절한 정밀도 자동 선택 초보자 권장 FP16 빠르지만 세부 사항 적음 빠른 생성 필요 시 FP32 최상의 품질, 속도 느림 최고 품질 필요 시 BF16 FP16과 FP32 사이 특정 새 GPU용
-
CPU에서 VAE 실행 (cpu-vae)
- 기능: CPU가 최종 이미지 처리 수행
- 사용 사례:
- GPU 메모리 부족 시
- 매우 큰 이미지 처리 시
- GPU 성능 부족 시
-
텍스트 인코더 정밀도 (text-encoder-precision)
- 기능: AI의 텍스트 이해 정밀도 제어
- 옵션:
옵션 설명 사용 사례 AUTO 최적의 정밀도 자동 선택 초보자 권장 FP32 가장 정확한 이해, 속도 느림 정확한 프롬프트 해석 필요 시 FP16 빠른 이해, 약간의 편차 가능 빠른 속도 필요 시 BF16 둘 사이의 균형 특정 GPU 최적화용
메모리
-
channels-last 메모리 형식 강제 적용 (force-channels-last)
- 기능: 메모리의 이미지 데이터 배열 방식 변경
- 권장: 영향을 이해하지 못하는 경우 기본값 유지
-
DirectML 장치 (directml)
- 기능: DirectML 장치 선택
- 사용 사례: AMD GPU 사용자용
-
IPEX 최적화 비활성화 (disable-ipex-optimize)
- 기능: IPEX 최적화 비활성화
- 기본값:
false
미리보기 설정
-
미리보기 방법 (preview-method)
- 기능: 생성 과정 미리보기 방식 제어
- 옵션:
옵션 설명 사용 사례 NoPreviews 미리보기 없음 최고 속도 필요 시 Latent 흐린 생성 과정 표시 진행 상황 확인 시 Taesd 더 선명한 생성 과정 표시 명확한 진행 상황 필요 시
-
미리보기 이미지 크기 (preview-size)
- 기능: 미리보기 창 크기 설정
- 권장값:
- 일반 사용: 512
- 성능 부족 시: 256
- 성능 충분 시: 더 크게 설정 가능
캐시
-
예전 방식의 캐시 시스템 사용 (cache-classic)
- 기능: 전통적인 캐시 관리 방식 사용
- 사용 사례:
- 시스템 메모리 충분 시
- 안정적 성능 필요 시
-
LRU 캐싱 사용 (cache-lru)
- 기능: 최근 사용된 데이터 캐시량 설정
- 권장값:
- 8GB RAM: 2-3
- 16GB RAM: 4-6
- 32GB+ RAM: 8-12
어텐션 설정
-
교차 어텐션 방법 (cross-attention-method)
- 기능: AI의 텍스트 이해 및 이미지 변환 방식 제어
- 옵션:
옵션 설명 사용 사례 auto 최적의 방법 자동 선택 초보자 권장 split VRAM 절약, 속도 느림 VRAM 부족 시 quad 전통적 방식, 안정적 안정적 효과 필요 시 pytorch PyTorch 기본 방식 호환성 문제 시
-
어텐션 업캐스트 강제 적용 (force-attention-upcast)
- 기능: 어텐션 메커니즘에 더 높은 정밀도 강제 사용
- 사용 사례: 이미지 세부 사항이 이상적이지 않을 때
-
어텐션 업캐스트 방지 (prevent-attention-upcast)
- 기능: 어텐션 메커니즘의 높은 정밀도 사용 방지
- 사용 사례: 빠른 생성 속도 필요 시
VRAM 관리
-
VRAM 관리 모드 (vram-management)
- 기능: GPU 메모리 사용 방식 제어
- 옵션:
옵션 설명 사용 사례 Auto 자동 관리 초보자 권장 Full 모든 가용 공간 사용 VRAM 충분 시 Low 공간 절약 VRAM 부족 시
-
예약된 VRAM (reserve-vram)
- 기능: 다른 프로그램용 GPU 메모리 예약
- 권장값: 다른 프로그램 필요에 따라 2-4GB
일반
-
xFormers 최적화 비활성화 (disable-xformers)
- 기능: xFormers 가속화 최적화 비활성화
- 권장: 문제가 없는 한 활성화 유지
-
기본 해싱 함수 (default-hashing-function)
- 기능: 모델 파일 무결성 검사 방법 선택
- 옵션:
옵션 설명 sha256 가장 일반적이고 안전한 검사 방법
-
결정론적 알고리즘 사용
- 기능: 더 안정적이지만 느린 랜덤 알고리즘 사용
- 권장: 일반적으로 활성화 불필요
-
실험적 최적화 활성화
- 기능: 테스트되지 않은 최적화 방법 사용
- 권장: 안정적 효과 추구 시 비권장
-
서버 출력을 콘솔에 출력하지 않음
- 기능: 백엔드 실행 로그 표시하지 않음
- 권장: 문제 해결 시 비활성화
-
프롬프트 메타데이터 저장 비활성화
- 기능: 생성된 이미지 파일에 프롬프트 정보 저장하지 않음
- 사용 사례: 프롬프트 비공개 유지 시
-
모든 사용자 정의 노드 로드 비활성화
- 기능: 모든 사용자 정의 기능 모듈 로드 방지
- 사용 사례: 가장 기본적인 안정적 경험 원할 때
-
로그 출력 수준 (log-level)
- 기능: 시스템 로그 상세 수준 설정
- 옵션:
옵션 설명 사용 사례 DEBUG 모든 세부 정보 표시 개발자 또는 문제 해결 시 INFO 일반 정보 표시 일상적 사용 권장 WARNING 경고와 오류만 표시 문제 알림만 필요 시 ERROR 오류만 표시 심각한 문제만 관심 있을 때 CRITICAL 치명적 오류만 표시 가장 심각한 문제만 필요 시
디렉토리 설정
-
입력 디렉토리 (input-directory)
- 기능: 입력 파일용 디렉토리 설정
- 기본값: 빈 문자열
-
출력 디렉토리 (output-directory)
- 기능: 출력 파일용 디렉토리 설정
- 기본값: 빈 문자열