ComfyUI Frame Pack 워크플로우 완전 단계별 튜토리얼
이 튜토리얼은 ComfyUI에서 Frame Pack 워크플로우를 사용하는 방법에 대한 자세한 단계별 지침을 제공합니다.
FramePack은 ControlNet의 저자인 스탠퍼드 대학교의 Lvmin Zhang 박사 팀이 개발한 AI 비디오 생성 기술입니다. 주요 특징은 다음과 같습니다:
- 동적 컨텍스트 압축: 비디오 프레임을 중요도에 따라 분류하여 키 프레임은 1536개의 특징 마커를 유지하고, 전환 프레임은 192개로 단순화합니다.
- 드리프트 방지 샘플링: 양방향 메모리 방법과 역방향 생성 기술을 활용하여 이미지 드리프트를 방지하고 동작의 연속성을 보장합니다.
- 감소된 VRAM 요구 사항: 비디오 생성을 위한 VRAM 임계값을 전문 등급 하드웨어(12GB+)에서 소비자 수준(단 6GB VRAM)으로 낮추어, RTX 3060 노트북을 가진 일반 사용자가 최대 60초 길이의 고품질 비디오를 생성할 수 있게 합니다.
- 오픈 소스 및 통합: FramePack은 현재 오픈 소스화되어 텐센트의 Hunyuan 비디오 모델에 통합되어 있으며, 멀티모달 입력(텍스트 + 이미지 + 음성)과 실시간 인터랙티브 생성을 지원합니다.
Frame Pack 관련 원본 링크
- 원본 저장소: https://github.com/lllyasviel/FramePack/
- ComfyUI 없이 Windows에서 원클릭 실행 통합 패키지: https://github.com/lllyasviel/FramePack/releases/tag/windows
해당 프롬프트
lllyasviel은 해당 저장소에서 비디오 생성을 위한 GPT 프롬프트를 제공합니다. Frame Pack 워크플로우를 사용하는 동안 프롬프트 작성 방법이 확실하지 않은 경우 다음을 시도해 볼 수 있습니다:
- 아래 프롬프트를 복사하여 GPT에 보냅니다.
- GPT가 요구 사항을 이해하면 해당 이미지를 제공하고 적절한 프롬프트를 받습니다.
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.ComfyUI에서 Frame Pack의 현재 구현
현재 ComfyUI에서 Frame Pack 기능을 구현한 커스텀 노드 저자는 세 명이 있습니다:
- Kijai: ComfyUI-FramePackWrapper
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
이러한 커스텀 노드 간의 차이점
아래에서는 이러한 커스텀 노드로 구현된 워크플로우의 차이점을 설명합니다.
Kijai의 커스텀 플러그인
Kijai는 해당 모델을 재패키징했으며, Kijai의 관련 커스텀 노드를 사용한 것 같습니다. 이렇게 빠른 업데이트를 가져온 것에 감사드립니다!
Kijai의 버전은 ComfyUI Manager에 등록되어 있지 않은 것 같아서 현재는 Manager의 커스텀 노드 관리자를 통해 설치할 수 없습니다. Manager의 Git을 통해 또는 수동으로 설치해야 합니다.
특징:
- 첫 번째 및 마지막 프레임으로 비디오 생성 지원
- Git을 통한 설치 또는 수동 설치 필요
- 모델을 재사용 가능
HM-RunningHub 및 TTPlanetPig의 커스텀 플러그인
이 두 커스텀 노드는 동일한 코드를 기반으로 한 수정 버전으로, 원래 HM-RunningHub에 의해 생성되었으며, 그 후 TTPlanetPig가 해당 플러그인 소스 코드를 기반으로 첫 번째 및 마지막 프레임으로 비디오 생성을 구현했습니다. 이 PR을 확인할 수 있습니다.
이 두 커스텀 노드에서 사용되는 모델의 폴더 구조는 일관되며, 둘 다 재패키징되지 않은 원본 저장소 모델 파일을 사용합니다. 따라서 이러한 모델 파일은 이 폴더 구조를 지원하지 않는 다른 커스텀 노드에서는 사용할 수 없어 디스크 공간 사용량이 더 커집니다.
특징:
- 첫 번째 및 마지막 프레임으로 비디오 생성 지원
- 다운로드한 모델 파일은 다른 노드나 워크플로우에서 재사용이 불가능할 수 있음
- 모델 파일이 재패키징되지 않아 더 많은 디스크 공간 차지
- 종속성과 관련된 일부 호환성 문제
Kijai ComfyUI-FramePackWrapper FLF2V ComfyUI 워크플로우
1. 플러그인 설치
ComfyUI-FramePackWrapper의 경우, Manager의 Git을 사용하여 설치해야 할 수 있습니다:
다음은 유용할 수 있는 몇 가지 글입니다:
2. 워크플로우 파일 다운로드
아래 비디오 파일을 다운로드하고 ComfyUI로 드래그하여 해당 워크플로우를 로드합니다. 파일에 모델 정보를 추가했으며, 이는 모델 다운로드를 요청할 것입니다.
비디오 미리보기
아래 이미지를 다운로드하여 이미지 입력으로 사용할 것입니다.


3. 수동 모델 설치
워크플로우에서 모델을 성공적으로 다운로드할 수 없는 경우, 아래 모델을 다운로드하여 해당 위치에 저장하십시오.
CLIP Vision
VAE
텍스트 인코더
확산 모델 Kijai는 다른 정밀도의 두 가지 버전을 제공합니다. 그래픽 카드 성능에 따라 하나를 선택하여 다운로드할 수 있습니다.
| 파일 이름 | 정밀도 | 크기 | 다운로드 링크 | 그래픽 카드 요구 사항 |
|---|---|---|---|---|
| FramePackI2V_HY_bf16.safetensors | bf16 | 25.7GB | 다운로드 링크 | 높음 |
| FramePackI2V_HY_fp8_e4m3fn.safetensors | fp8 | 16.3GB | 다운로드 링크 | 낮음 |
파일 저장 위치
📂 ComfyUI/
├──📂 models/
│ ├──📂 diffusion_models/
│ │ └── FramePackI2V_HY_fp8_e4m3fn.safetensors # 또는 bf16 정밀도
│ ├──📂 text_encoders/
│ │ ├─── clip_l.safetensors
│ │ └─── llava_llama3_fp16.safetensors
│ ├──📂 clip_vision/
│ │ └── sigclip_vision_patch14_384.safetensors
│ └──📂 vae/
│ └── hunyuan_video_vae_bf16.safetensors4. 해당 워크플로우 단계별 완성
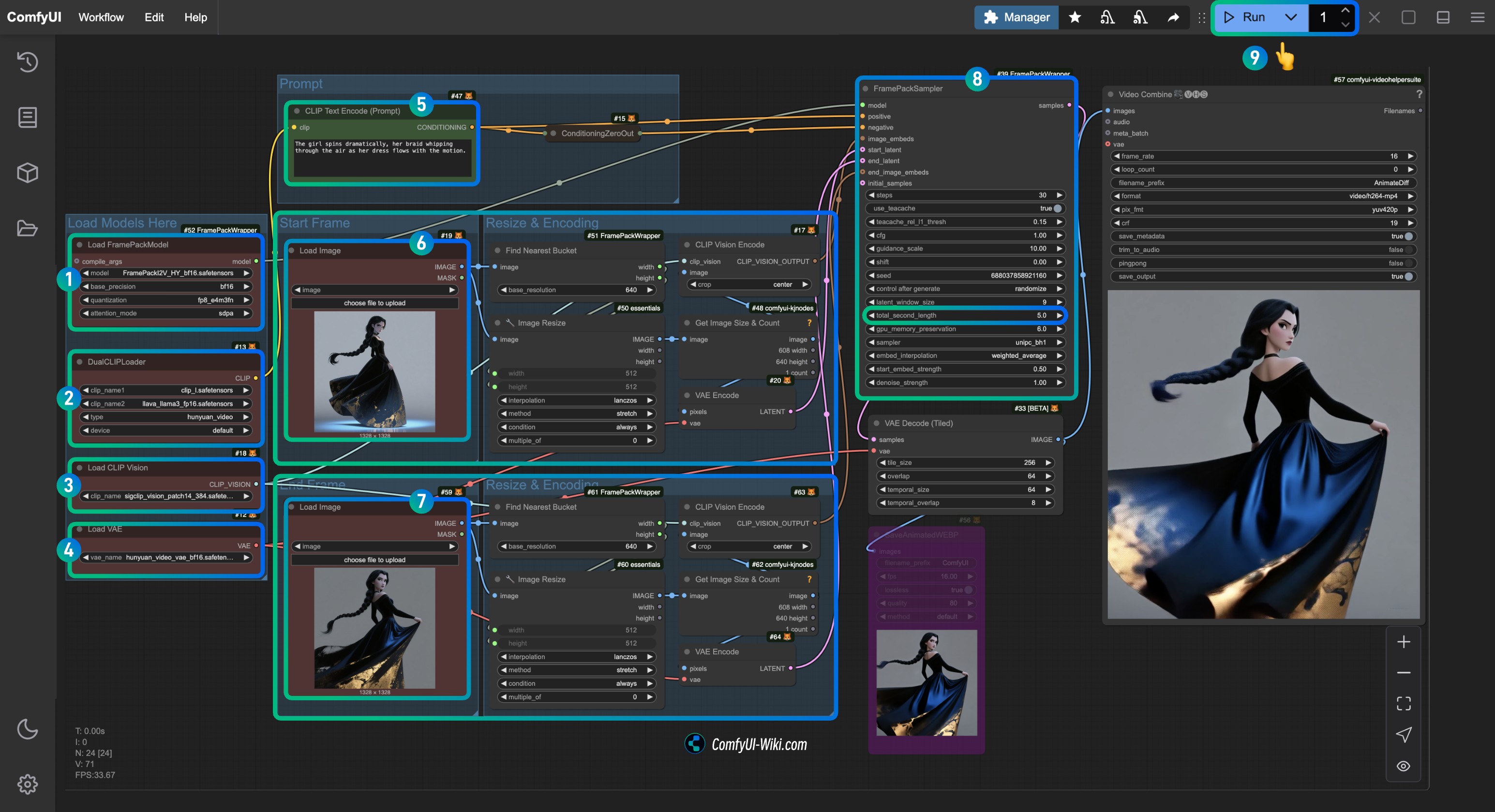
Load FramePackModel노드가FramePackI2V_HY_fp8_e4m3fn.safetensors모델을 로드했는지 확인합니다.DualCLIPLoader노드가 다음을 로드했는지 확인합니다:clip_l.safetensors모델llava_llama3_fp16.safetensors모델
Load CLIP Vision노드가sigclip_vision_patch14_384.safetensors모델을 로드했는지 확인합니다.Load VAE노드에hunyuan_video_vae_bf16.safetensors모델을 로드할 수 있습니다.- (선택 사항, 내 입력 이미지를 사용하는 경우)
CLIP Text Encoder노드의Prompt매개변수를 수정하여 생성하려는 비디오에 대한 설명을 입력합니다. Load Image노드에서first_frame입력 처리와 관련된first_frame.jpg를 로드합니다.Load Image노드에서last_frame입력 처리와 관련된last_frame.jpg를 로드합니다(마지막 프레임이 필요하지 않은 경우 삭제하거나 Bypass를 사용하여 비활성화할 수 있습니다).FramePackSampler노드에서total_second_length매개변수를 수정하여 비디오 길이를 변경할 수 있습니다. 내 워크플로우에서는5초로 설정되어 있으며, 필요에 따라 조정할 수 있습니다.Run버튼을 클릭하거나Ctrl(cmd) + Enter단축키를 사용하여 비디오 생성을 실행합니다.
마지막 프레임이 필요하지 않은 경우, last_frame과 관련된 모든 입력 처리를 우회하십시오.
HM-RunningHub 및 TTPlanetPig 플러그인 상세 정보
이 두 플러그인은 동일한 모델 저장 위치를 사용하지만, 앞서 언급했듯이 지정된 위치에 저장해야 하는 전체 원본 저장소를 다운로드합니다. 이로 인해 다른 플러그인이 이러한 모델을 재사용하지 못하게 되어 일부 디스크 공간이 낭비됩니다. 그러나 첫 번째 및 마지막 프레임 생성을 구현하므로 원한다면 시도해 볼 수 있습니다.
list index out of range 문제가 발생했습니다. 이 이슈를 확인할 수 있습니다. 현재, 가능한 상황으로 논의된 것은 다음과 같습니다:
"사용 중인 torchvision 버전이 설치된 PyAV 버전과 호환되지 않을 가능성이 있습니다."
그러나 이슈에서 언급된 방법을 시도한 후에도 문제를 해결할 수 없었습니다. 따라서 여기서는 관련 튜토리얼 정보만 제공할 수 있습니다. 문제를 해결하는 데 성공하면 피드백을 제공해 주세요. 이 이슈를 확인하여 유사한 해결책을 제안한 사람이 있는지 확인하는 것이 좋습니다.
플러그인 설치
- 다음 중 하나 또는 둘 다 설치할 수 있습니다. 노드는 다르지만 둘 다 하나의 노드만으로 사용하기 간단합니다:
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
- ComfyUI에서 비디오 편집 경험 향상:
비디오 관련 워크플로우에 VideoHelperSuite를 사용한 경우, ComfyUI의 비디오 기능을 확장하는 데 여전히 중요합니다.
1. 모델 다운로드
HM-RunningHub는 모든 모델을 다운로드하기 위한 Python 스크립트를 제공합니다. 이 스크립트를 실행하고 안내를 따르기만 하면 됩니다. 내 접근 방식은 아래 코드를 download_models.py로 저장하고 ComfyUI/models 루트 디렉토리에 배치한 다음, 해당 디렉토리에서 터미널에서 python download_models.py를 실행하는 것입니다.
cd <your installation path>/ComfyUI/models/그런 다음 스크립트를 실행합니다:
python download_models.py이를 위해서는 Python 독립 환경/시스템 환경에 huggingface_hub 패키지가 설치되어 있어야 합니다.
from huggingface_hub import snapshot_download
# HunyuanVideo 모델 다운로드
snapshot_download(
repo_id="hunyuanvideo-community/HunyuanVideo",
local_dir="HunyuanVideo",
ignore_patterns=["transformer/*", "*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# flux_redux_bfl 모델 다운로드
snapshot_download(
repo_id="lllyasviel/flux_redux_bfl",
local_dir="flux_redux_bfl",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# FramePackI2V_HY 모델 다운로드
snapshot_download(
repo_id="lllyasviel/FramePackI2V_HY",
local_dir="FramePackI2V_HY",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)또한 아래 모델을 수동으로 다운로드하여 해당 위치에 저장할 수 있습니다. 이는 해당 저장소의 모든 파일을 다운로드한다는 의미입니다.
- HunyuanVideo: HuggingFace 링크
- Flux Redux BFL: HuggingFace 링크
- FramePackI2V: HuggingFace 링크
파일 저장 위치
comfyui/models/
flux_redux_bfl
├── feature_extractor
│ └── preprocessor_config.json
├── image_embedder
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── image_encoder
│ ├── config.json
│ └── model.safetensors
├── model_index.json
└── README.md
FramePackI2V_HY
├── config.json
├── diffusion_pytorch_model-00001-of-00003.safetensors
├── diffusion_pytorch_model-00002-of-00003.safetensors
├── diffusion_pytorch_model-00003-of-00003.safetensors
├── diffusion_pytorch_model.safetensors.index.json
└── README.md
HunyuanVideo
├── config.json
├── model_index.json
├── README.md
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ ├── model-00001-of-00004.safetensors
│ ├── model-00002-of-00004.safetensors
│ ├── model-00003-of-00004.safetensors
│ ├── model-00004-of-00004.safetensors
│ └── model.safetensors.index.json
├── text_encoder_2
│ ├── config.json
│ └── model.safetensors
├── tokenizer
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.json
├── tokenizer_2
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── vae
├── config.json
└── diffusion_pytorch_model.safetensors2. 워크플로우 다운로드
HM-RunningHub
TTPlanetPig

댓글
GitHub로 로그인하고 토론에 참여하세요.