Flux de travail et tutoriel de génération vidéo pilotée par l'audio Wan2.2-S2V ComfyUI
Créez des avatars parlants avec un lip-sync naturel en utilisant Wan2.2-S2V dans ComfyUI. Couvre la configuration du modèle, le pipeline S2V et des exemples de workflow.
Wan2.2-S2V représente une avancée significative dans la technologie de génération vidéo par IA, capable de créer du contenu vidéo dynamique à partir d'images statiques et d'entrées audio. Ce modèle innovant excelle dans la production de vidéos synchronisées avec une synchronisation labiale naturelle, ce qui le rend particulièrement précieux pour les créateurs de contenu travaillant sur des scènes de dialogue, des performances musicales et des récits axés sur les personnages.
Points forts du modèle
- Génération vidéo pilotée par l'audio : Transforme des images statiques et de l'audio en vidéos synchronisées avec une synchronisation labiale et des expressions naturelles
- Qualité cinématographique : Génère des vidéos de qualité cinématographique avec des expressions faciales authentiques, des mouvements corporels et un langage caméra
- Génération de niveau minute : Prend en charge la création de vidéos de longue durée allant jusqu'à une minute dans une seule génération
- Prise en charge multi-format : Fonctionne avec des personnes réelles, des dessins animés, des animaux, des humains numériques et prend en charge les formats portrait, buste et corps entier
- Contrôle de mouvement amélioré : Génère des actions et des environnements à partir d'instructions textuelles avec des mécanismes de contrôle AdaIN et CrossAttention
- Métriques de haute performance : Atteint FID 15.66, CSIM 0.677 et SSIM 0.734 pour une qualité vidéo supérieure et une cohérence d'identité
Flux de travail natif Wan2.2 S2V ComfyUI
1. Télécharger le fichier de flux de travail
Téléchargez le fichier de flux de travail suivant et faites-le glisser dans ComfyUI pour charger le flux de travail.
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/wan2.2_s2v/wan2.2-s2v.mp4"
Téléchargez l'image et l'audio suivants comme entrée :

2. Liens des modèles
Vous pouvez trouver les modèles dans notre dépôt
diffusion_models
audio_encoders
vae
text_encoders
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_s2v_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_s2v_14B_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├───📂 audio_encoders/ # Créez-en un si vous ne trouvez pas ce dossier
│ │ └─── wav2vec2_large_english_fp16.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors3. Instructions du flux de travail
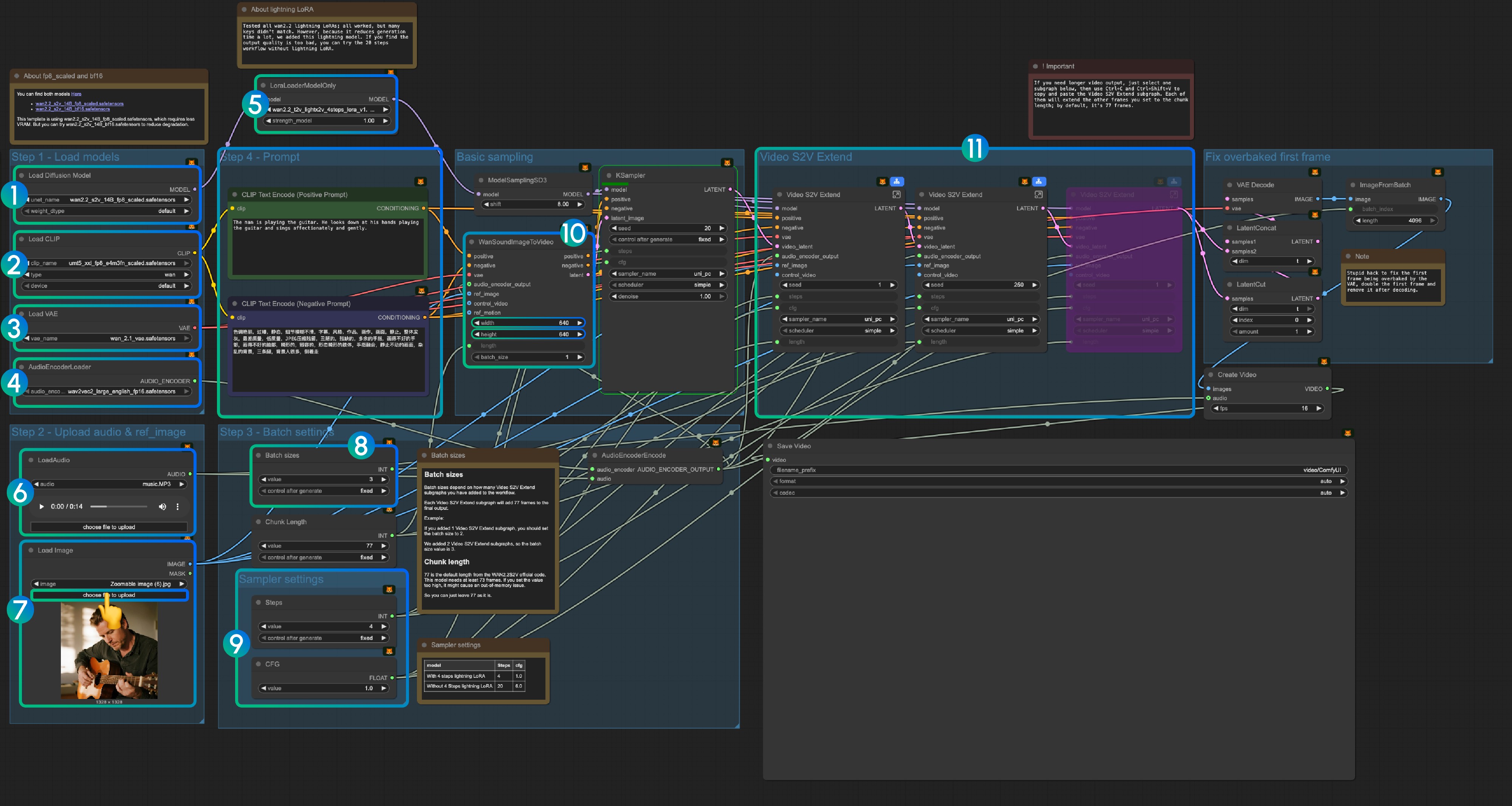
3.1 Lightning LoRA (Facultatif, pour l'accélération)
Lightning LoRA réduit le temps de génération de 20 étapes à 4 étapes mais peut affecter la qualité. À utiliser pour des aperçus rapides, désactiver pour la sortie finale.
3.1.1 Conseils de prétraitement audio
Séparation vocale pour de meilleurs résultats : Comme le noyau ComfyUI n'inclut pas de nœuds de séparation vocale, nous recommandons d'utiliser des outils externes pour séparer les voix de la musique de fond avant le traitement. C'est particulièrement important pour la génération de dialogues et de synchronisation labiale, car les pistes vocales propres produisent des résultats nettement meilleurs que l'audio mixé avec de la musique de fond ou du bruit.
3.2 À propos des modèles fp8_scaled et bf16
Vous pouvez trouver les deux modèles ici:
Le modèle utilise wan2.2_s2v_14B_fp8_scaled.safetensors pour une utilisation VRAM plus faible. Essayez wan2.2_s2v_14B_bf16.safetensors pour une meilleure qualité.
3.3 Instructions étape par étape
Étape 1 : Charger les modèles
- Charger le modèle de diffusion : Chargez
wan2.2_s2v_14B_fp8_scaled.safetensorsouwan2.2_s2v_14B_bf16.safetensors- Le flux de travail utilise
wan2.2_s2v_14B_fp8_scaled.safetensorspour des exigences VRAM plus faibles - Utilisez
wan2.2_s2v_14B_bf16.safetensorspour une sortie de meilleure qualité
- Le flux de travail utilise
- Charger CLIP : Chargez
umt5_xxl_fp8_e4m3fn_scaled.safetensors - Charger VAE : Chargez
wan_2.1_vae.safetensors - AudioEncoderLoader : Chargez
wav2vec2_large_english_fp16.safetensors - LoraLoaderModelOnly : Chargez
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA)- Ce LoRA réduit le temps de génération mais peut affecter la qualité
- Désactivez si la qualité de sortie est insuffisante
- LoadAudio : Téléchargez le fichier audio fourni ou votre propre audio
- Load Image : Téléchargez l'image de référence
- Tailles de lot : Définissez selon le nombre de nœuds de sous-graphe Video S2V Extend
- Chaque sous-graphe Video S2V Extend ajoute 77 images à la sortie
- Exemple : 2 sous-graphes Video S2V Extend = taille de lot 3
- Longueur de segment : Conserver la valeur par défaut de 77
- Paramètres de l'échantillonneur : Choisissez en fonction de l'utilisation de Lightning LoRA
- Avec Lightning LoRA 4 étapes : steps: 4, cfg: 1.0
- Sans Lightning LoRA : steps: 20, cfg: 6.0
- Paramètres de taille : Définissez les dimensions de la vidéo de sortie
- Video S2V Extend : Nœuds de sous-graphe d'extension vidéo
- Chaque extension génère 77 / 16 = 4,8125 secondes de vidéo
- Calculer les nœuds nécessaires : longueur audio (secondes) × 16 ÷ 77
- Exemple : audio de 14s = 224 images ÷ 77 = 3 nœuds d'extension
- Utilisez Ctrl-Entrée ou cliquez sur le bouton Exécuter pour exécuter le flux de travail
Liens associés
- Code Wan2.2 S2V : GitHub
- Modèle Wan2.2 S2V : Hugging Face
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.