Guide d'utilisation complet des flux de travail Qwen-Image ComfyUI natif, GGUF et Nunchaku
Qwen-Image est un modèle MMDiT (Transformateur de diffusion multimodal) de 20 milliards de paramètres publié en open source sous licence Apache 2.0.
Qwen-Image est un modèle de base de génération d'images développé par l'équipe Tongyi Lab d'Alibaba, utilisant une architecture MMDiT (Transformateur de diffusion multimodal) de 20 milliards de paramètres, publié en open source sous la licence Apache 2.0. Le modèle présente des avantages techniques uniques dans le domaine de la génération d'images, particulièrement performant dans le rendu de texte et l'édition d'images.
Caractéristiques principales :
- Capacité de rendu de texte multilingue : Le modèle peut générer avec précision des images contenant de l'anglais, du chinois, du coréen, du japonais et d'autres langues, avec un texte clair et lisible qui s'harmonise avec le style de l'image
- Prise en charge de styles artistiques variés : Du style réaliste aux créations artistiques, du style anime au design moderne, le modèle peut basculer de manière flexible entre différents styles visuels selon les invites
- Fonction d'édition d'images précise : Prend en charge les modifications locales, les transformations de style et les ajouts de contenu sur les images existantes, tout en maintenant la cohérence visuelle globale
Ressources associées :
Guide du flux de travail natif Qwen-Image ComfyUI
Trois modèles différents sont utilisés dans le flux de travail joint à ce document :
- Modèle original Qwen-Image fp8_e4m3fn
- Version accélérée 8 étapes : Modèle original Qwen-Image fp8_e4m3fn utilisant le LoRA 8 étapes lightx2v
- Version distillée : Modèle distillé Qwen-Image fp8_e4m3fn
Référence d'utilisation de la VRAM GPU : RTX4090D 24GB
| Modèle utilisé | Utilisation VRAM | Première génération | Deuxième génération |
|---|---|---|---|
| fp8_e4m3fn | 86% | ≈ 94s | ≈ 71s |
| fp8_e4m3fn utilisant LoRA 8 étapes lightx2v | 86% | ≈ 55s | ≈ 34s |
| Version distillée fp8_e4m3fn | 86% | ≈ 69s | ≈ 36s |
1. Fichier de flux de travail
Après avoir mis à jour ComfyUI, vous pouvez trouver le fichier de flux de travail dans les modèles, ou faites glisser le flux de travail ci-dessous dans ComfyUI pour le charger

<a className="prose" target='_blank' href="https://raw.githubusercontent.com/Comfy-Org/workflow_templates/refs/heads/main/templates/image_qwen_image.json" style={{ display: 'inline-block', backgroundColor: '#0078D6', color: '#ffffff', padding: '10px 20px', borderRadius: '8px', borderColor: "transparent", textDecoration: 'none', fontWeight: 'bold'}}> <p className="prose" style={{ margin: 0, fontSize: "0.8rem" }}>Télécharger le flux de travail au format JSON officiel
Version distillée
2. Téléchargement des modèles
Versions que vous pouvez trouver dans le dépôt ComfyOrg
- Qwen-Image_bf16 (40,9 Go)
- Qwen-Image_fp8 (20,4 Go)
- Version distillée (non officielle, seulement 15 étapes)
Tous les modèles peuvent être trouvés sur Huggingface ou ModelScope
Modèle de diffusion
Qwen_image_distill
LoRA
Encodeur de texte
VAE
Emplacement de stockage des modèles
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ ├── qwen_image_fp8_e4m3fn.safetensors
│ │ └── qwen_image_distill_full_fp8_e4m3fn.safetensors ## Version distillée
│ ├── 📂 loras/
│ │ └── Qwen-Image-Lightning-8steps-V1.0.safetensors ## Modèle LoRA d'accélération 8 étapes
│ ├── 📂 vae/
│ │ └── qwen_image_vae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors3. Compléter le flux de travail étape par étape
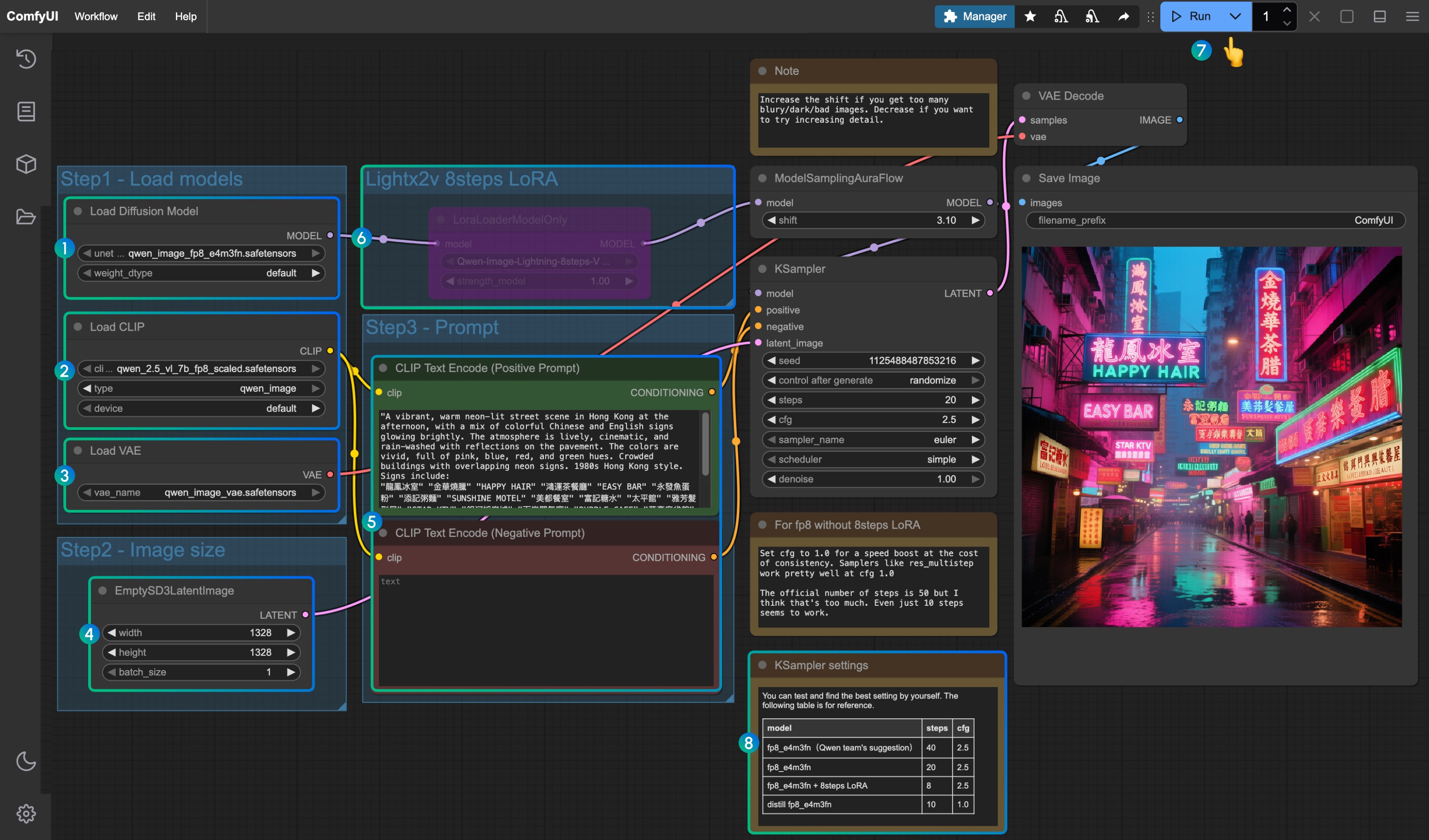
- Assurez-vous que le nœud
Load Diffusion Modelchargeqwen_image_fp8_e4m3fn.safetensors - Assurez-vous que le nœud
Load CLIPchargeqwen_2.5_vl_7b_fp8_scaled.safetensors - Assurez-vous que le nœud
Load VAEchargeqwen_image_vae.safetensors - Assurez-vous que les dimensions de l'image sont définies dans le nœud
EmptySD3LatentImage - Définissez les invites dans le nœud
CLIP Text Encoder; actuellement testé pour prendre en charge au moins : anglais, chinois, coréen, japonais, italien, etc. - Pour activer le LoRA d'accélération 8 étapes lightx2v, sélectionnez-le et utilisez
Ctrl + Bpour activer le nœud, et modifiez les paramètres de Ksampler selon les paramètres à la position8 - Cliquez sur le bouton
Queue, ou utilisez le raccourciCtrl(cmd) + Enterpour exécuter le flux de travail - Paramètres pour KSampler correspondant aux différentes versions de modèles et flux de travail
Flux de travail Qwen-Image version GGUF ComfyUI
La version GGUF est plus adaptée aux utilisateurs avec peu de VRAM, et dans certaines configurations de poids, vous n'avez besoin que d'environ 8 Go de VRAM pour exécuter Qwen-Image
Référence d'utilisation de la VRAM :
| Flux de travail | Utilisation VRAM | Première génération | Générations suivantes |
|---|---|---|---|
| qwen-image-Q4_K_S.gguf | 56% | ≈ 135s | ≈ 77s |
| Avec LoRA 8 étapes | 56% | ≈ 100s | ≈ 45s |
Adresse du modèle : Qwen-Image-gguf
1. Mettre à jour ou installer des nœuds personnalisés
L'utilisation de la version GGUF nécessite que vous installiez ou mettiez à jour le plugin ComfyUI-GGUF
Veuillez vous référer à Comment installer des nœuds personnalisés ComfyUI, ou rechercher et installer via le Manager
2. Téléchargement du flux de travail

3. Téléchargement des modèles
La version GGUF utilise uniquement le modèle de diffusion différemment des autres
Veuillez visiter https://huggingface.co/city96/Qwen-Image-gguf pour télécharger n'importe quel poids ; généralement, les fichiers de plus grande taille offrent une meilleure qualité mais nécessitent également plus de VRAM. Dans ce tutoriel, j'utiliserai la version suivante :
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen-image-Q4_K_S.gguf # Ou toute autre version que vous choisissez3. Compléter le flux de travail GGUF étape par étape
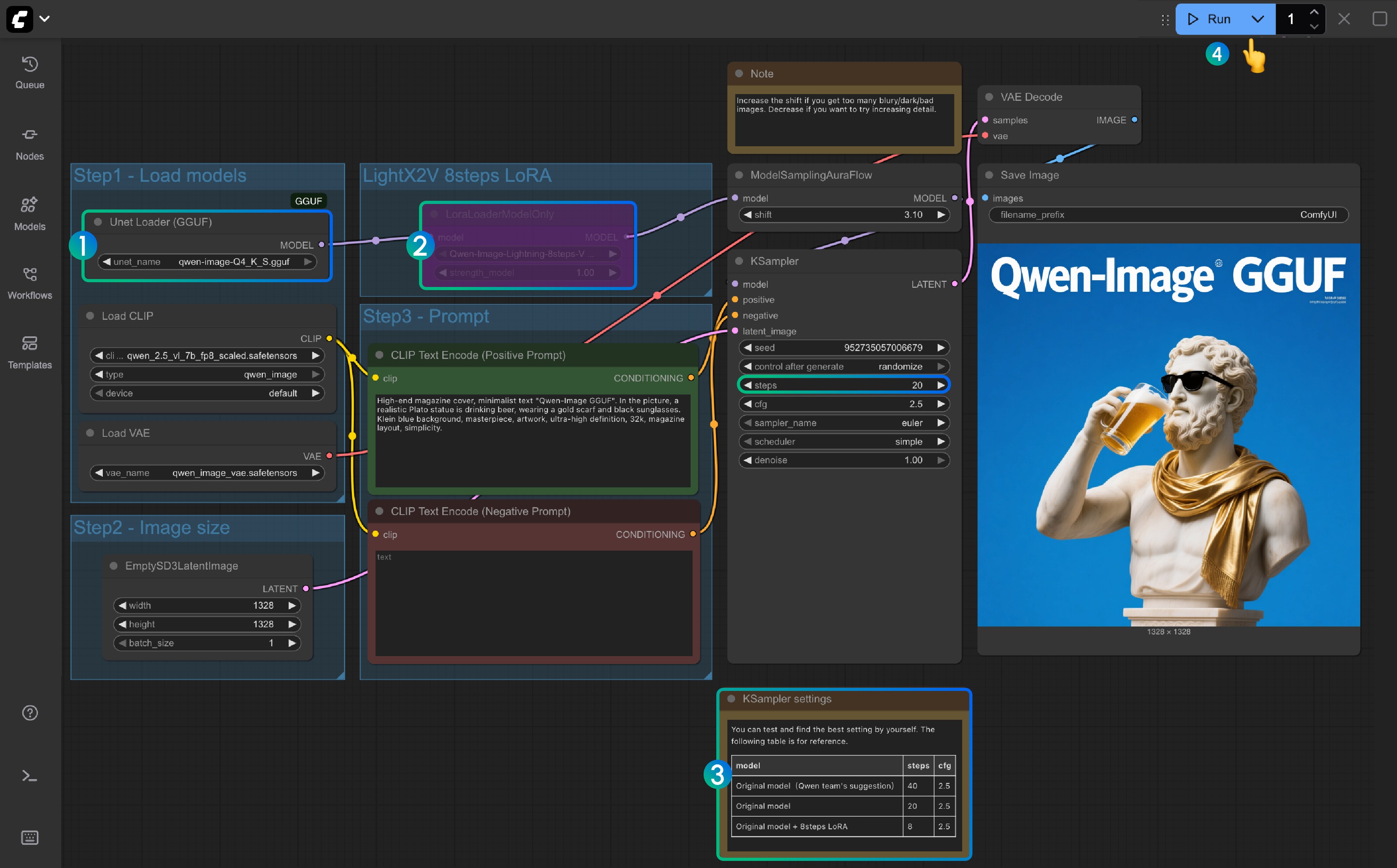
- Assurez-vous que le nœud
Unet Loader(GGUF)chargeqwen-image-Q4_K_S.ggufou toute autre version que vous avez téléchargée- Assurez-vous que ComfyUI-GGUF est installé et mis à jour
- Pour
LightX2V 8Steps LoRA, il n'est pas activé par défaut ; vous pouvez le sélectionner et utiliser Ctrl+B pour activer le nœud - Si le LoRA 8 étapes n'est pas activé, le nombre d'étapes par défaut est 20 ; si vous activez le LoRA 8 étapes, veuillez le régler sur 8
- Voici la référence pour régler le nombre d'étapes correspondant
- Cliquez sur le bouton
Queue, ou utilisez le raccourciCtrl(cmd) + Enterpour exécuter le flux de travail
Flux de travail version Nunchaku de Qwen-Image
Adresse du modèle : nunchaku-qwen-image Adresse du nœud personnalisé : https://github.com/nunchaku-tech/ComfyUI-nunchaku
Qwen Image ControlNet
Flux de travail Qwen Image ControlNet DiffSynth-ControlNets Model Patches
Ce modèle n'est en fait pas un controlnet, mais un Model patch qui prend en charge trois modes de contrôle différents : canny, depth et inpaint.
Adresse du modèle original : DiffSynth-Studio/Qwen-Image ControlNet Adresse de rehost Comfy Org : Qwen-Image-DiffSynth-ControlNets/model_patches
1. Flux de travail et images d'entrée
Téléchargez l'image ci-dessous et faites-la glisser dans ComfyUI pour charger le flux de travail correspondant

Téléchargez l'image ci-dessous comme image d'entrée :

2. Liens des modèles
Les autres modèles sont cohérents avec le flux de travail de base Qwen-Image. Vous devez uniquement télécharger les modèles suivants et les sauvegarder dans le dossier ComfyUI/models/model_patches :
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. Instructions d'utilisation du flux de travail
Actuellement, diffsynth a trois modèles de patch : les modèles Canny, Depth et Inpaint.
Si vous utilisez des flux de travail liés à ControlNet pour la première fois, vous devez comprendre que les images utilisées pour le contrôle doivent être prétraitées dans des formats d'image pris en charge avant de pouvoir être utilisées et reconnues par le modèle.

- Canny : Canny traité, contours de dessin au trait
- Depth : Carte de profondeur prétraitée, montrant les relations spatiales
- Inpaint : Nécessite l'utilisation d'un Masque pour marquer les zones qui doivent être redessinées
Étant donné que ce modèle de patch est divisé en trois modèles différents, vous devez sélectionner le bon type de prétraitement lors de la saisie pour assurer un prétraitement d'image correct.
Instructions d'utilisation du modèle Canny ControlNet
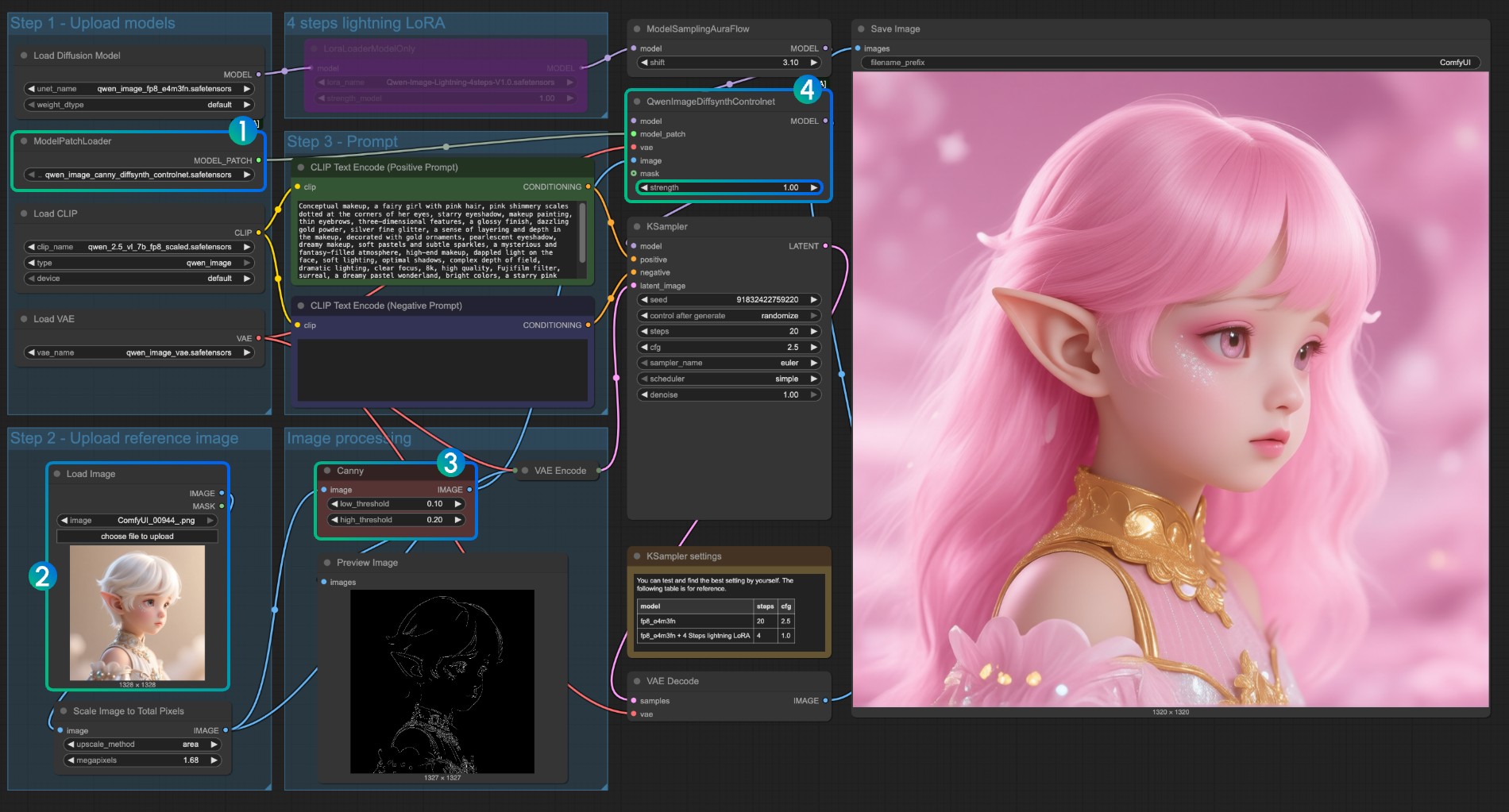
- Assurez-vous que
qwen_image_canny_diffsynth_controlnet.safetensorsest chargé - Téléchargez l'image d'entrée pour le traitement ultérieur
- Le nœud Canny est un nœud de prétraitement natif qui prétraitera l'image d'entrée selon vos paramètres définis pour contrôler la génération
- Si nécessaire, vous pouvez modifier le paramètre
strengthdu nœudQwenImageDiffsynthControlnetpour contrôler la force du contrôle de dessin au trait - Cliquez sur le bouton
Run, ou utilisez le raccourciCtrl(cmd) + Enterpour exécuter le flux de travail
Pour utiliser qwen_image_depth_diffsynth_controlnet.safetensors, vous devez prétraiter l'image en carte de profondeur, en remplaçant la partie
image processing. Pour cette utilisation, veuillez vous référer à la méthode de traitement InstantX dans ce document. Les autres parties sont similaires à l'utilisation du modèle Canny.
Instructions d'utilisation du modèle Inpaint ControlNet
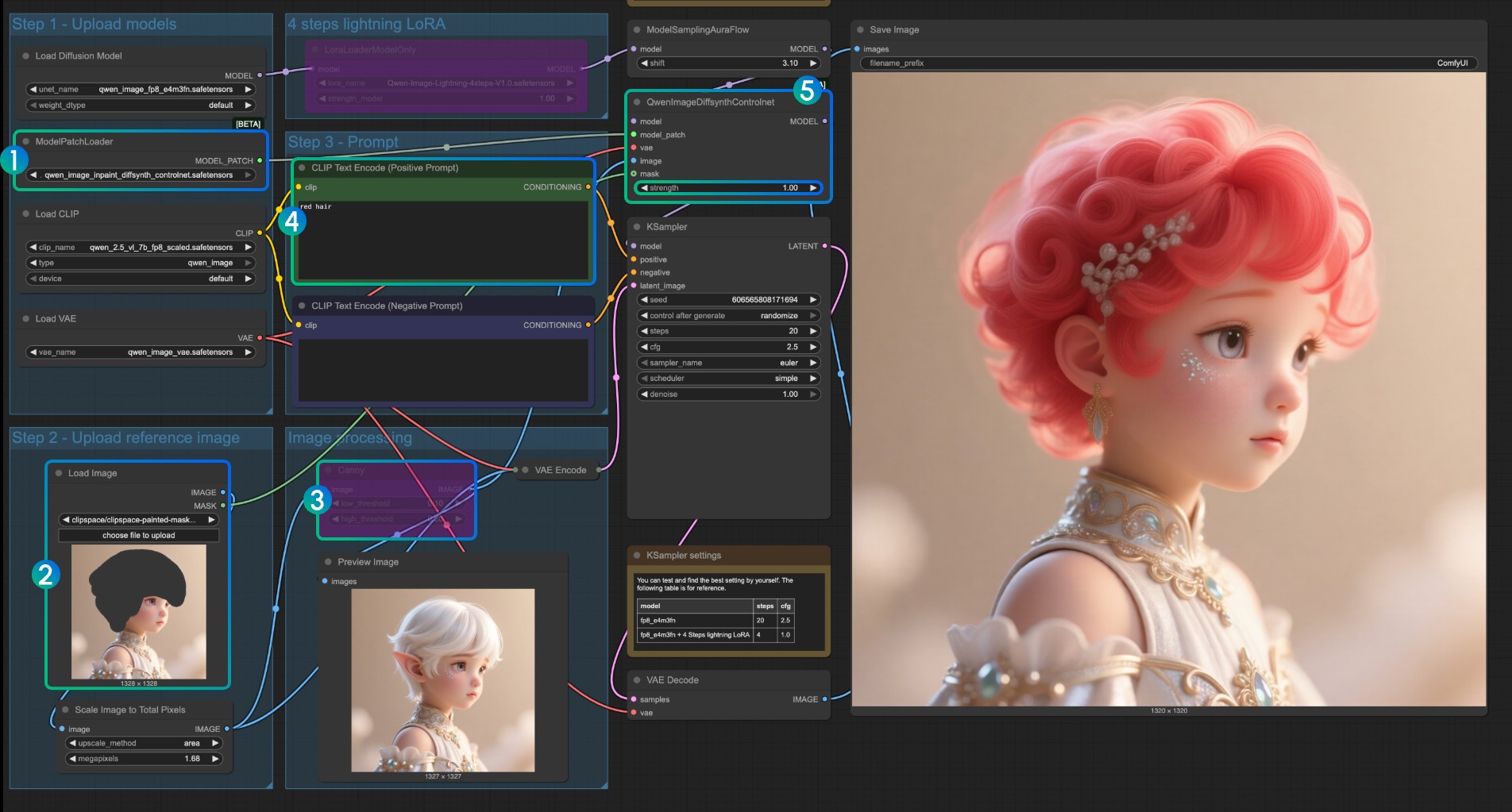
Pour le modèle Inpaint, il nécessite l'utilisation de l'éditeur de masque pour dessiner un masque et l'utiliser comme condition de contrôle d'entrée.
- Assurez-vous que
ModelPatchLoadercharge le modèleqwen_image_inpaint_diffsynth_controlnet.safetensors - Téléchargez une image et utilisez l'éditeur de masque pour dessiner un masque. Vous devez connecter la sortie
maskdu nœudLoad Imagecorrespondant à l'entréemaskdeQwenImageDiffsynthControlnetpour vous assurer que le masque correspondant est chargé - Utilisez le raccourci
Ctrl-Bpour définir le Canny original dans le flux de travail en mode contournement, afin que le traitement du nœud Canny correspondant ne prenne pas effet - Dans l'
encodeur de texte CLIP, saisissez le style que vous voulez changer pour la partie masquée - Si nécessaire, vous pouvez modifier le paramètre
strengthdu nœudQwenImageDiffsynthControlnetpour contrôler la force de contrôle correspondante - Cliquez sur le bouton
Run, ou utilisez le raccourciCtrl(cmd) + Enterpour exécuter le flux de travail
Flux de travail Qwen Image Union ControlNet LoRA
Adresse du modèle original : DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Adresse de rehost Comfy Org : qwen_image_union_diffsynth_lora.safetensors : LoRA de contrôle de structure d'image prenant en charge canny, depth, pose, lineart, softedge, normal, openpose
1. Flux de travail et images d'entrée
Téléchargez l'image ci-dessous et faites-la glisser dans ComfyUI pour charger le flux de travail

Téléchargez l'image ci-dessous comme image d'entrée :

2. Liens des modèles
Téléchargez le modèle suivant. Comme il s'agit d'un modèle LoRA, il doit être sauvegardé dans le dossier ComfyUI/models/loras/ :
- qwen_image_union_diffsynth_lora.safetensors : LoRA de contrôle de structure d'image prenant en charge canny, depth, pose, lineart, softedge, normal, openpose
3. Instructions du flux de travail
Ce modèle est un LoRA de contrôle unifié qui prend en charge canny, depth, pose, lineart, softedge, normal, openpose et d'autres contrôles. Comme de nombreux nœuds de prétraitement d'image natifs ne sont pas entièrement pris en charge, vous pourriez avoir besoin de quelque chose comme comfyui_controlnet_aux pour compléter d'autres prétraitements d'image.
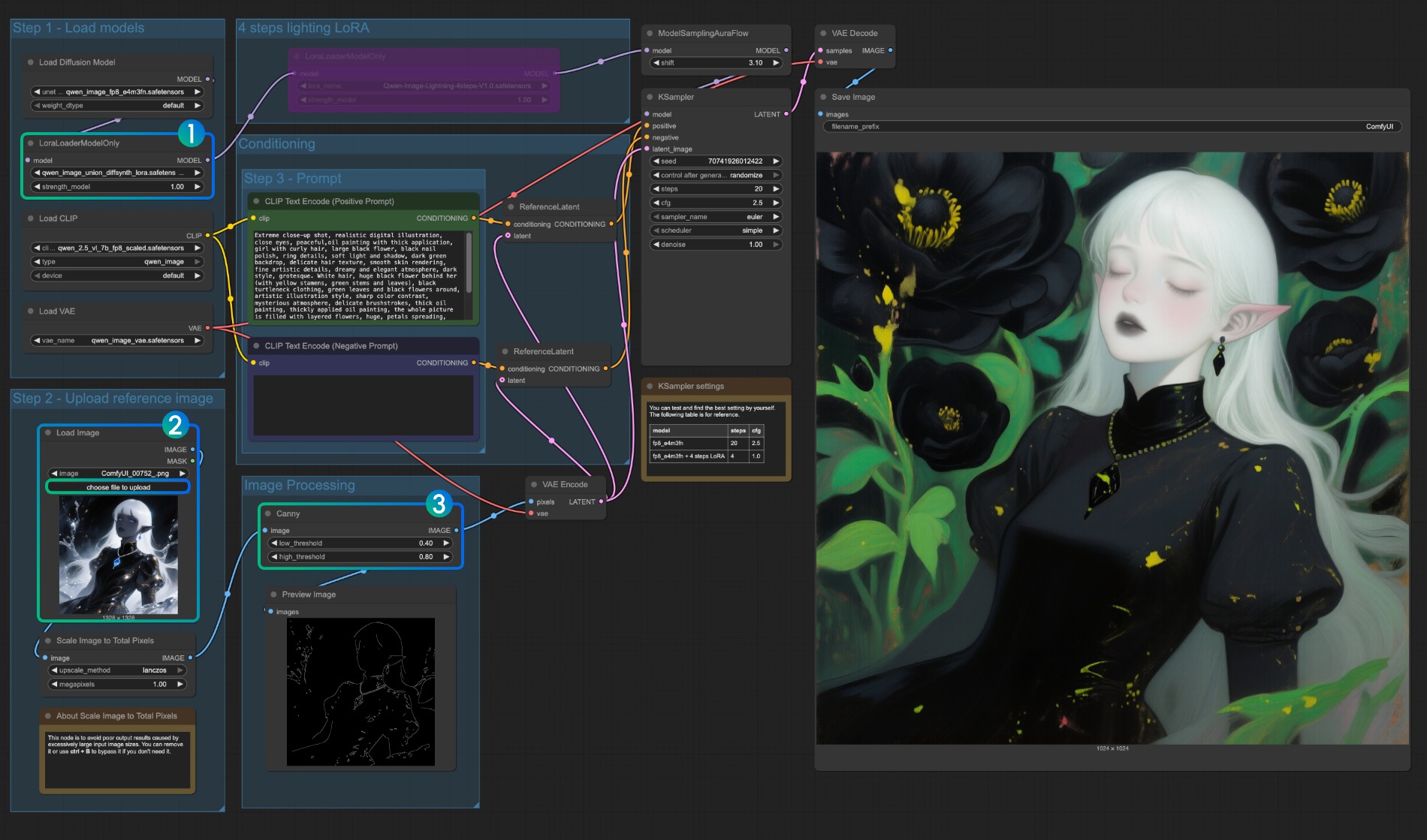
- Assurez-vous que
LoraLoaderModelOnlycharge correctement le modèleqwen_image_union_diffsynth_lora.safetensors - Téléchargez l'image d'entrée
- Si nécessaire, vous pouvez ajuster les paramètres du nœud
Canny. Comme différentes images d'entrée nécessitent différents paramètres pour obtenir de meilleurs résultats de prétraitement d'image, vous pouvez essayer d'ajuster les valeurs de paramètres correspondantes pour obtenir plus/moins de détails - Cliquez sur le bouton
Run, ou utilisez le raccourciCtrl(cmd) + Enterpour exécuter le flux de travail
Pour d'autres types de contrôle, vous devez également remplacer la partie de traitement d'image.
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.