Exemple de flux de travail ComfyUI HiDream-I1 fp8, gguf, nf4 de texte à image - Guide complet
Ce tutoriel comprend des exemples de flux de travail pour différentes versions de HiDream I1.

HiDream-I1 est un modèle de texte à image officiellement open-source par HiDream-ai depuis le 7 avril 2025, avec une échelle de paramètres de 17B.
Type de licence Publié sous la licence MIT, il prend en charge une utilisation pour des projets personnels, des recherches scientifiques et des fins commerciales. Le modèle a bien performé dans plusieurs tests de référence.
Dans cet article, nous aborderons les points suivants :
- Une brève introduction à HiDream-I1
- Informations sur les différentes versions du modèle HiDream-I1 disponibles dans la communauté et leur support
- Flux de travail pour différentes versions de modèles
Étant donné que la version complète de ce modèle a des exigences élevées en VRAM, vous pouvez choisir une version adaptée à votre appareil dans la section des modèles communautaires et apprendre les flux de travail correspondants. Veuillez vous rappeler de consulter cet article Mettre à jour ComfyUI vers la dernière version pour vous assurer que les nœuds correspondants peuvent fonctionner correctement.
Introduction à HiDream-I1
Caractéristiques du modèle
Conception d'architecture hybride Combinant des modèles de diffusion (DiT) avec une architecture de mélange d'experts (MoE) :
- Le corps principal est basé sur le Diffusion Transformer (DiT), traitant des informations multimodales à travers un module MMDiT à double flux, tandis qu'un module DiT à flux unique optimise la cohérence globale.
- Le mécanisme de routage dynamique alloue de manière flexible les ressources informatiques, améliorant la capacité à gérer des scènes complexes, et performe exceptionnellement bien dans la restauration des couleurs, le traitement des bords et d'autres détails.
Intégration de codeurs de texte multimodaux Intègre quatre codeurs de texte :
- OpenCLIP ViT-bigG, OpenAI CLIP ViT-L (alignement visuel-sémantique)
- T5-XXL (analyse de longs textes)
- Llama-3.1-8B-Instruct (compréhension des instructions) Cette combinaison atteint des performances de pointe dans l'analyse sémantique complexe liée à la couleur, à la quantité, aux relations spatiales, etc., avec un support nettement meilleur pour les invites en chinois par rapport à des modèles open-source similaires.
Référentiel de modèle original
HiDream-ai fournit trois versions du modèle HiDream-I1 pour répondre à différents besoins de scénario. Voici les liens vers les référentiels de modèles originaux :
- Version complète : 🤗 HiDream-I1-Full avec 50 étapes d'inférence
- Version de développement distillée : 🤗 HiDream-I1-Dev avec 28 étapes d'inférence
- Version rapide distillée : 🤗 HiDream-I1-Fast avec 16 étapes d'inférence
Versions de modèle HiDream-I1 de la communauté
Actuellement, il existe de nombreuses versions variantes du modèle HiDream-I1 dans la communauté. Il s'agit d'une collection de versions existantes organisées par ComfyUI-Wiki. Cependant, en raison de certains problèmes rencontrés lors des tests, je ne fournirai que les flux de travail correspondants.
Versions reconditionnées de ComfyOrg
Le référentiel ComfyOrg propose des versions reconditionnées complètes, de développement et rapides, y compris à la fois la version complète et la version fp8. La version complète nécessite environ 20 Go de VRAM, tandis que la version fp8 nécessite environ 16 Go de VRAM. Nous utiliserons l'exemple natif pour compléter le flux de travail.
Modèles de version GGUF
Les modèles de version GGUF sont fournis par city96 :
Le référentiel contient plusieurs versions allant de Q8 à Q2, avec Q4 nécessitant environ 12 Go de VRAM et Q2 nécessitant environ 8 Go de VRAM. Si vous n'êtes pas sûr, vous pouvez commencer à tester avec la plus petite version.
Vous devrez utiliser le nœud Unet loader(GGUF) de ComfyUI-GGUF pour charger les modèles, et nous modifierons légèrement les nœuds officiels pour compléter le flux de travail.
Modèles de version NF4
Cette version utilise la technologie de quantification 4 bits pour réduire l'utilisation de la mémoire et peut fonctionner avec environ 16 Go de VRAM.
- HiDream-I1-Full-nf4
- HiDream-I1-Dev-nf4
- HiDream-I1-Fast-nf4
- Utilisez le nœud ComfyUI-HiDream-Sampler pour utiliser les modèles de version NF4. Ce nœud a été initialement fourni par lum3on.
Le ComfyUI-HiDream-Sampler téléchargera les modèles lors de la première exécution et mettra en œuvre une fonctionnalité d'image à image non officielle. Nous compléterons également les exemples correspondants dans ce document.
Installation de modèles partagés
Les fichiers de modèle ci-dessous seront utilisés dans plusieurs flux de travail, nous pouvons donc commencer à les télécharger et à nous référer aux emplacements de stockage des fichiers de modèle. Nous fournirons des liens de téléchargement pour les modèles de diffusion correspondants dans les flux de travail pertinents.
Codeurs de texte :
- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors C'est une version légère de T5XXL, que vous avez peut-être déjà.
- llama_3.1_8b_instruct_fp8_scaled.safetensors
VAE
- ae.safetensors C'est le modèle VAE de Flux. Si vous avez utilisé le flux de travail de Flux, vous avez déjà ce fichier.
Modèles de diffusion Nous vous guiderons pour télécharger les fichiers de modèle correspondants dans les flux de travail pertinents.
Emplacements de stockage des fichiers de modèle
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 text_encoders/
│ │ ├─── clip_l_hidream.safetensors
│ │ ├─── clip_g_hidream.safetensors
│ │ ├─── t5xxl_fp8_e4m3fn_scaled.safetensors
│ │ └─── llama_3.1_8b_instruct_fp8_scaled.safetensors
│ └── 📂 vae/
│ │ └── ae.safetensors
│ └── 📂 diffusion_models/
│ └── ... # Vous serez guidé pour installer dans la version correspondante du flux de travailWorkflow ComfyUI Native HiDream-I1
Le flux de travail natif a été détaillé dans la documentation officielle que j'ai écrite pour Comfy, intitulée Exemple de flux de travail ComfyUI Native HiDream-I1. Cependant, comme la documentation officielle ne prend actuellement en charge que le chinois et l'anglais, je fournirai également des exemples correspondants dans ce guide, en tenant compte du support multilingue de ComfyUI Wiki.
Dans la documentation officielle, j'ai écrit des flux de travail complets pour les versions complète, dev et rapide. Ces trois flux de travail utilisent généralement les mêmes modèles et workflows, avec seulement quelques paramètres et modèles différents. Par conséquent, nous n'utiliserons qu'une seule version du flux de travail ici et compléterons les paramètres pertinents pour les deux autres versions afin d'éviter une répétition excessive dans ce document.
1. Téléchargement du fichier de flux de travail
Veuillez télécharger l'image ci-dessous et la faire glisser dans ComfyUI pour charger le flux de travail correspondant. Le fichier contient des informations intégrées sur le téléchargement des modèles, et ComfyUI vérifiera si les fichiers de modèle correspondants existent dans les sous-répertoires de premier niveau. Cependant, il ne peut pas vérifier si les fichiers de modèle existent dans des sous-répertoires de deuxième niveau comme ComfyUI/models/text_encoders/hidream/.
Si vous avez déjà téléchargé les modèles correspondants, vous pouvez ignorer les invites. Le flux de travail ci-dessous utilise le modèle hidream_i1_dev_fp8.safetensors. Si vous devez utiliser d'autres versions, veuillez vous référer à la section de téléchargement manuel des modèles pour télécharger les modèles correspondants.

Téléchargez le flux de travail au format JSON
2. Téléchargement manuel des modèles
Voici les fichiers de modèle pour différentes versions de HiDream-I1. Vous pouvez choisir la version appropriée en fonction de votre capacité VRAM et l'enregistrer dans le dossier ComfyUI/models/diffusion_models/.
| Nom du modèle | Version | Précision | Taille du fichier | Exigence VRAM | Lien de téléchargement |
|---|---|---|---|---|---|
| hidream_i1_full_fp16.safetensors | full | fp16 | 34,2 Go | 20 Go | Lien de téléchargement |
| hidream_i1_dev_bf16.safetensors | dev | bf16 | 34,2 Go | 20 Go | Lien de téléchargement |
| hidream_i1_fast_bf16.safetensors | fast | bf16 | 34,2 Go | 20 Go | Lien de téléchargement |
| hidream_i1_full_fp8.safetensors | full | fp8 | 17,1 Go | 16 Go | Lien de téléchargement |
| hidream_i1_dev_fp8.safetensors | dev | fp8 | 17,1 Go | 16 Go | Lien de téléchargement |
| hidream_i1_fast_fp8.safetensors | fast | fp8 | 17,1 Go | 16 Go | Lien de téléchargement |
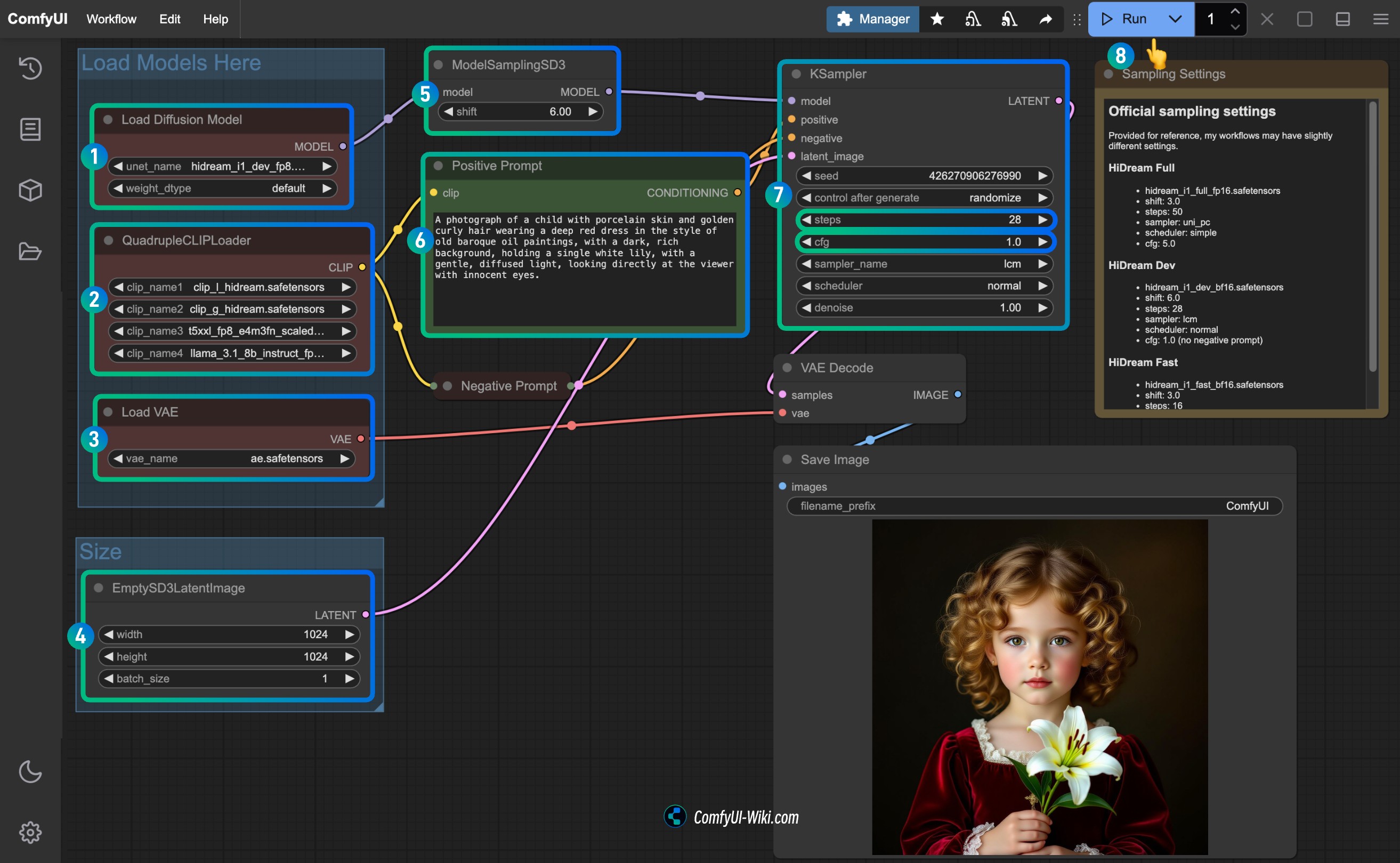
Suivez les étapes pour exécuter le flux de travail
- Assurez-vous que le nœud
Load Diffusion Modelutilise le fichierhidream_i1_dev_fp8.safetensorsou la version que vous avez téléchargée. - Assurez-vous que les quatre encodeurs de texte correspondants dans le
QuadrupleCLIPLoadersont chargés correctement :- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- Assurez-vous que le nœud
Load VAEutilise le fichierae.safetensors. - Pour la version dev, vous devez définir le paramètre
shiftdansModelSamplingSD3à3.0pour la version complète,6.0pour la version dev, et3.0pour la version rapide. - Pour le nœud
Ksampler, vous devez le configurer en fonction de la version du modèle que vous avez téléchargée :steps:50pour la version complète,28pour la version dev,16pour la version rapide.cfg: défini à5.0pour la version complète,1.0pour la version dev, et1.0pour la version rapide (les versions dev et rapide n'ont pas de prompts négatifs).- (Optionnel) Définissez
samplersurlcm. - (Optionnel) Définissez
schedulersurnormal.
- Cliquez sur le bouton
Run, ou utilisez le raccourciCtrl(cmd) + Enterpour exécuter la génération d'images.
4. Paramètres pour les différents modèles de version HiDream-I1
HiDream Complet
- Fichier modèle : hidream_i1_full_fp16.safetensors
- Paramètre
shiftdu nœudModelSamplingSD3: 3.0 - Nœud
Ksampler:- steps : 50
- sampler : uni_pc
- scheduler : simple
- cfg : 5.0
HiDream Dev
- Fichier modèle : hidream_i1_dev_bf16.safetensors
- Paramètre
shiftdu nœudModelSamplingSD3: 6.0 - Nœud
Ksampler:- steps : 28
- sampler : lcm
- scheduler : normal
- cfg : 1.0 (pas de prompts négatifs)
HiDream Rapide
- Fichier modèle : hidream_i1_fast_bf16.safetensors
- Paramètre
shiftdu nœudModelSamplingSD3: 3.0 - Nœud
Ksampler:- steps : 16
- sampler : lcm
- scheduler : normal
- cfg : 1.0 (pas de prompts négatifs)
Flux de travail de la version HiDream-I1 GGUF
La version GGUF utilise le modèle de version GGUF fourni par city96. Nous allons légèrement modifier les nœuds officiels pour compléter le flux de travail.
Vous devez installer le plugin ComfyUI-GGUF ou mettre à jour la version précédemment installée, et utiliser le nœud Unet loader(GGUF) pour charger le modèle. Vous pouvez ensuite charger mon flux de travail et utiliser la fonction de vérification des nœuds manquants de ComfyUI-Manager pour installer les nœuds correspondants, ou vous référer à l'installation de nœuds personnalisés pour une installation manuelle.
1. Téléchargement manuel du modèle
Le fichier de flux de travail ComfyUI n'intègre que les informations sur les modèles pour les fichiers .sft et .safetensors, donc pour le modèle de version GGUF, nous devons d'abord télécharger le modèle manuellement.
Les dépôts correspondants full, dev, et fast fournissent plusieurs versions de fichiers modèles allant de Q8 à Q2 pour chaque version, et vous pouvez choisir la version appropriée en fonction de votre situation VRAM et la télécharger dans le dossier ComfyUI/models/diffusion_models/.
Pour d'autres modèles requis, veuillez vous référer à la section installation de modèles partagés.
2. Fichier de flux de travail
Veuillez télécharger l'image ci-dessous et la faire glisser dans ComfyUI pour charger le flux de travail correspondant.

Téléchargez le flux de travail au format JSON.
3. Complétez l'exécution du flux de travail étape par étape
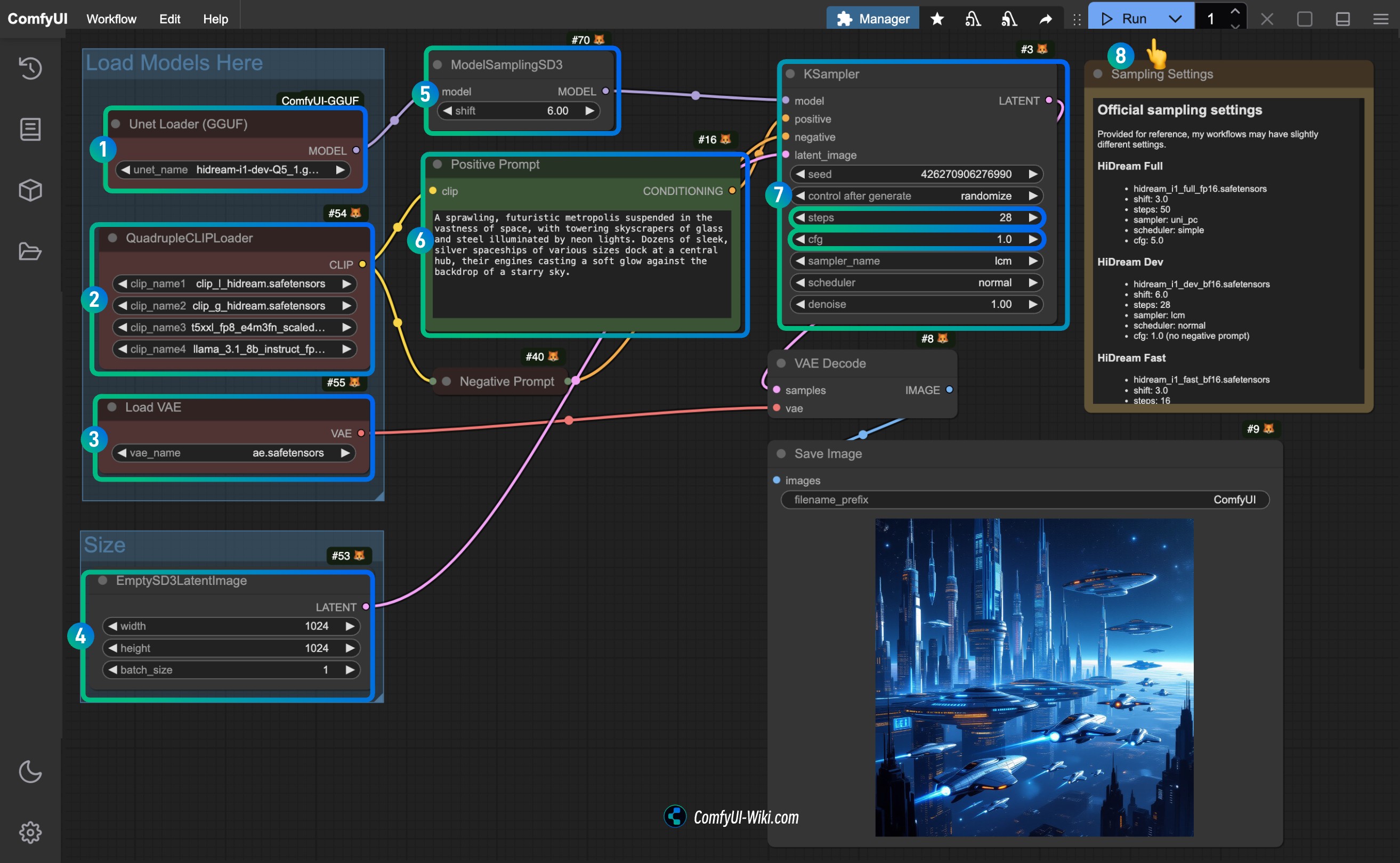
Puisque nous avons seulement remplacé le nœud Load Diffusion Model par le nœud Unet loader(GGUF), tout le reste est complètement cohérent avec le flux de travail original.
Suivez les étapes pour compléter l'exécution du flux de travail :
- Assurez-vous que le nœud
Unet loader(GGUF)utilise le fichier modèle de version GGUF que vous avez téléchargé. - Assurez-vous que les quatre encodeurs de texte correspondants dans le
QuadrupleCLIPLoadersont chargés correctement :- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- Assurez-vous que le nœud
Load VAEutilise le fichierae.safetensors. - Pour la version dev, vous devez définir le paramètre
shiftdansModelSamplingSD3à3.0pour la version complète,6.0pour la version dev, et3.0pour la version rapide. - Pour le nœud
Ksampler, vous devez le configurer en fonction de la version du modèle que vous avez téléchargée :steps:50pour la version complète,28pour la version dev,16pour la version rapide.cfg: défini à5.0pour la version complète,1.0pour la version dev, et1.0pour la version rapide (les versions dev et rapide n'ont pas de prompts négatifs).- (Optionnel) Définissez
samplersurlcm. - (Optionnel) Définissez
schedulersurnormal.
- Cliquez sur le bouton
Run, ou utilisez le raccourciCtrl(cmd) + Enterpour exécuter la génération d'images.
4. Paramètres pour les différents modèles de version HiDream-I1 GGUF
Veuillez vous référer à la section originale du flux de travail pour les paramètres.
Flux de travail de la version HiDream-I1 NF4
Cette version nécessite l'installation du plugin ComfyUI-HiDream-Sampler, initialement créé par lum3on.
Les nœuds devraient automatiquement télécharger le modèle, mais j'ai constaté qu'il n'y avait pas de journal de téléchargement correspondant après l'installation, car vous ne pouvez pas installer manuellement le modèle ou choisir l'emplacement du modèle vous-même, ce qui m'a fait sentir un peu hors de contrôle. Cependant, leurs exemples de flux de travail ont déjà mis en œuvre la fonctionnalité image à image. Après l'installation, vous devriez pouvoir trouver un dossier de flux de travail d'exemple dans le répertoire correspondant ou visiter sample-workflow pour l'obtenir. Les images ci-dessous incluent également les flux de travail correspondants. Si vous réussissez à le tester, veuillez me faire savoir dans les commentaires comment procéder. :)
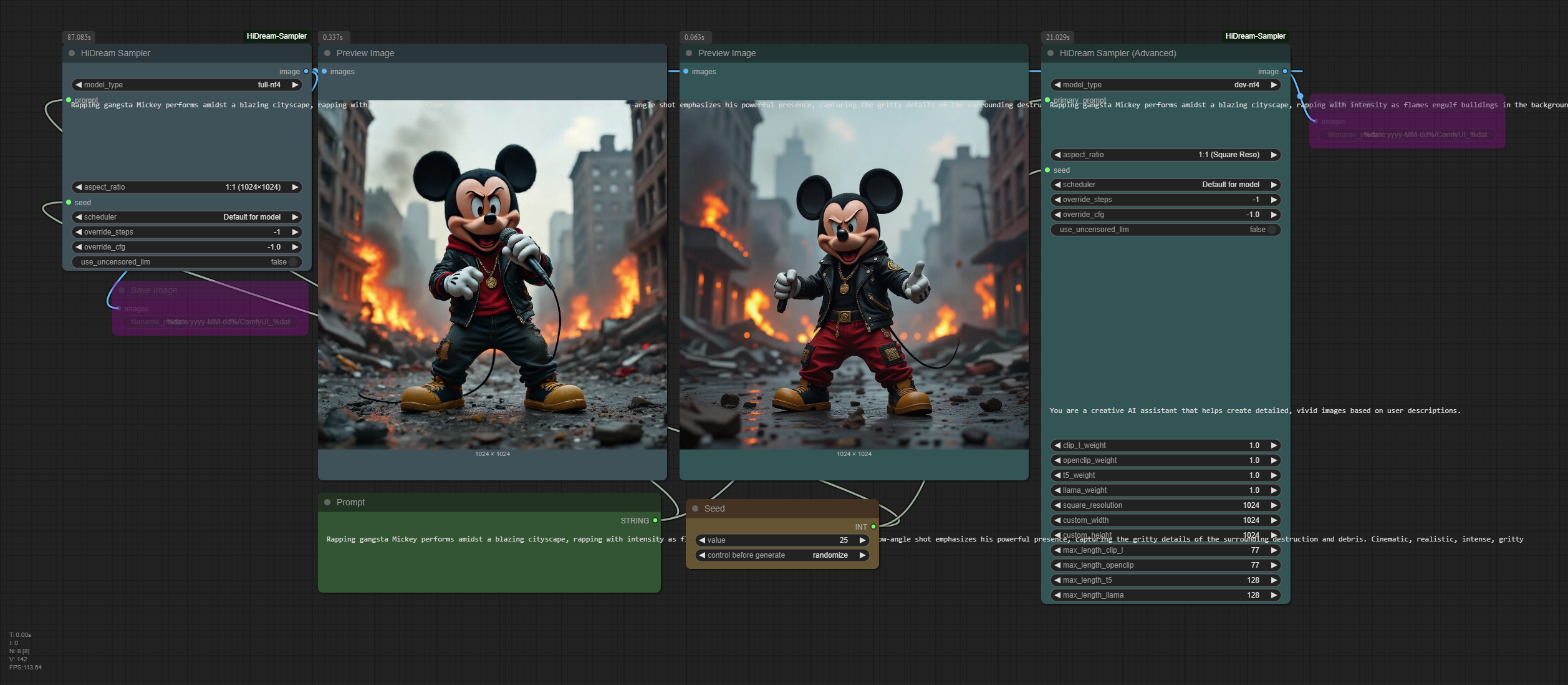
Flux de travail Texte à Image
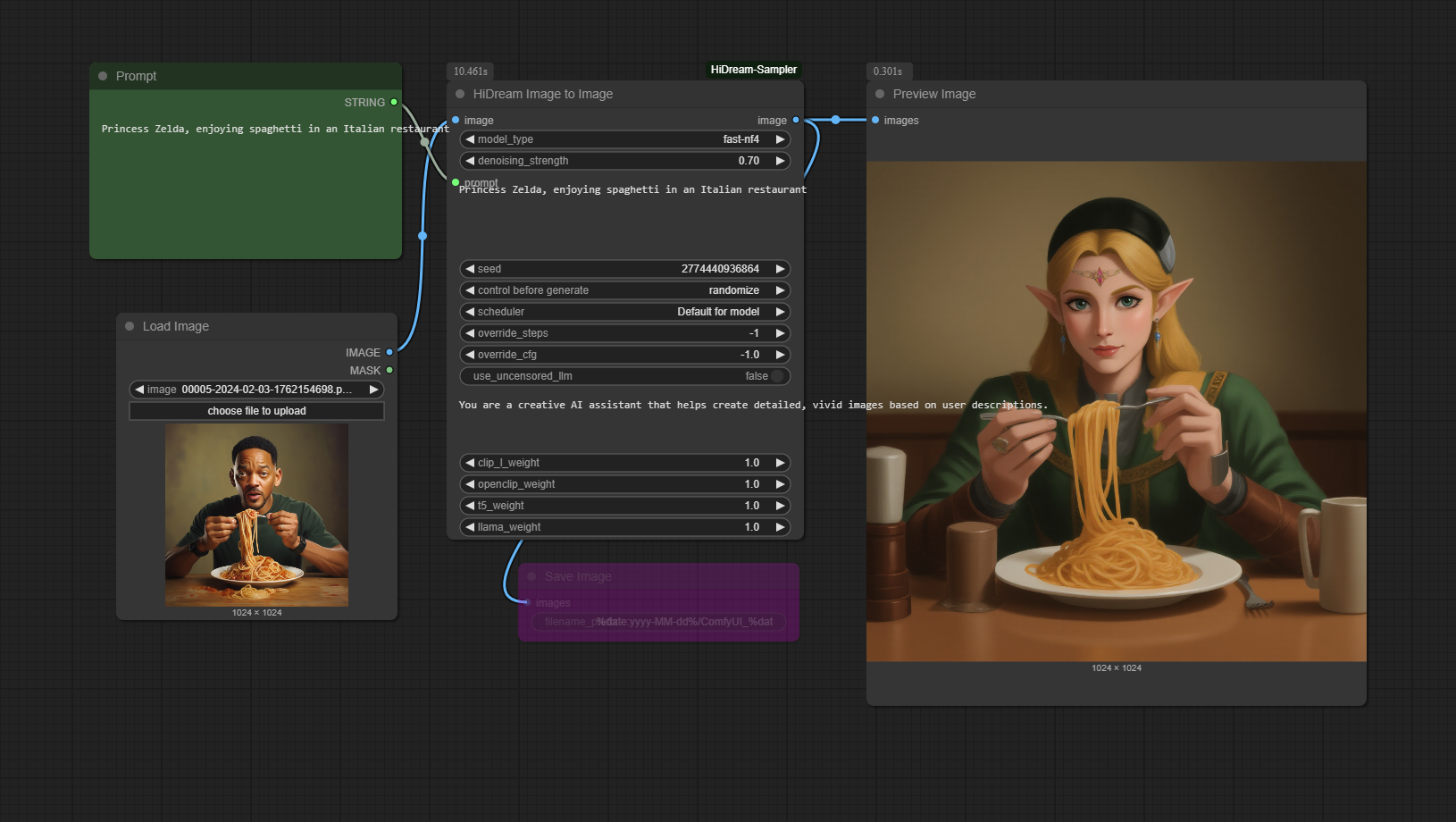
Flux de travail Image à Image
Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.