Tutoriel Complet Pas à Pas du Flux de Travail Frame Pack dans ComfyUI
Ce tutoriel vous guidera sur l'utilisation du flux de travail Frame Pack dans ComfyUI, en fournissant des instructions détaillées étape par étape.
FramePack est une technologie de génération vidéo par IA développée par l'équipe du Dr. Lvmin Zhang de l'Université de Stanford, l'auteur de ControlNet. Ses caractéristiques principales incluent:
- Compression Dynamique du Contexte: En classifiant les images vidéo selon leur importance, les images clés conservent 1536 marqueurs de caractéristiques, tandis que les images transitionnelles sont simplifiées à 192.
- Échantillonnage Résistant à la Dérive: Utilisation de méthodes de mémoire bidirectionnelle et de techniques de génération inverse pour éviter la dérive d'image et assurer la continuité des actions.
- Exigences Réduites en VRAM: Réduction du seuil de VRAM pour la génération vidéo du matériel professionnel (12GB+) au niveau grand public (seulement 6GB VRAM), permettant aux utilisateurs ordinaires avec un ordinateur portable RTX 3060 de générer des vidéos de haute qualité jusqu'à 60 secondes.
- Open Source et Intégration: FramePack est actuellement en open source et intégré dans le modèle vidéo Hunyuan de Tencent, supportant les entrées multimodales (texte + images + voix) et la génération interactive en temps réel.
Liens Originaux Liés à Frame Pack
- Dépôt Original: https://github.com/lllyasviel/FramePack/
- Package d'intégration en un clic pour Windows sans ComfyUI: https://github.com/lllyasviel/FramePack/releases/tag/windows
Prompt Correspondant
lllyasviel fournit un prompt GPT pour la génération vidéo dans le dépôt correspondant. Si vous n'êtes pas sûr de comment écrire des prompts en utilisant le flux de travail Frame Pack, vous pouvez essayer ce qui suit:
- Copiez le prompt ci-dessous et envoyez-le à GPT.
- Une fois que GPT comprend les exigences, fournissez-lui les images correspondantes, et vous recevrez les prompts appropriés.
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.Implémentation Actuelle de Frame Pack dans ComfyUI
Actuellement, il y a trois auteurs de nœuds personnalisés qui ont implémenté les capacités de Frame Pack dans ComfyUI:
- Kijai: ComfyUI-FramePackWrapper
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
Différences Entre Ces Nœuds Personnalisés
Ci-dessous, nous expliquons les différences dans les flux de travail implémentés par ces nœuds personnalisés.
Plugin Personnalisé de Kijai
Kijai a réemballé les modèles correspondants, et je crois que vous avez utilisé les nœuds personnalisés associés de Kijai, merci à lui pour ces mises à jour si rapides!
Il semble que la version de Kijai ne soit pas enregistrée dans le ComfyUI Manager, donc elle ne peut pas être installée actuellement via le Gestionnaire de Nœuds Personnalisés du Manager. Vous devez l'installer via le Git du Manager ou manuellement.
Caractéristiques:
- Supporte la génération vidéo avec premières et dernières images
- Nécessite une installation via Git ou une installation manuelle
- Les modèles sont réutilisables
Plugins Personnalisés de HM-RunningHub et TTPlanetPig
Ces deux nœuds personnalisés sont des versions modifiées basées sur le même code, créé à l'origine par HM-RunningHub, puis TTPlanetPig a implémenté la génération vidéo avec premières et dernières images basées sur le code source du plugin correspondant. Vous pouvez consulter cette PR.
La structure de dossiers des modèles utilisés par ces deux nœuds personnalisés est cohérente, tous deux utilisant les fichiers modèles du dépôt original qui n'ont pas été réemballés. Par conséquent, ces fichiers modèles ne peuvent pas être utilisés dans d'autres nœuds personnalisés qui ne supportent pas cette structure de dossiers, ce qui entraîne une utilisation plus importante de l'espace disque.
Caractéristiques:
- Supporte la génération vidéo avec premières et dernières images
- Les fichiers modèles téléchargés peuvent ne pas être réutilisables dans d'autres nœuds ou flux de travail
- Occupe plus d'espace disque car les fichiers modèles ne sont pas réemballés
- Quelques problèmes de compatibilité avec les dépendances
Flux de Travail ComfyUI de Kijai ComfyUI-FramePackWrapper FLF2V
1. Installation du Plugin
Pour ComfyUI-FramePackWrapper, vous devrez peut-être l'installer en utilisant le Git du Manager:
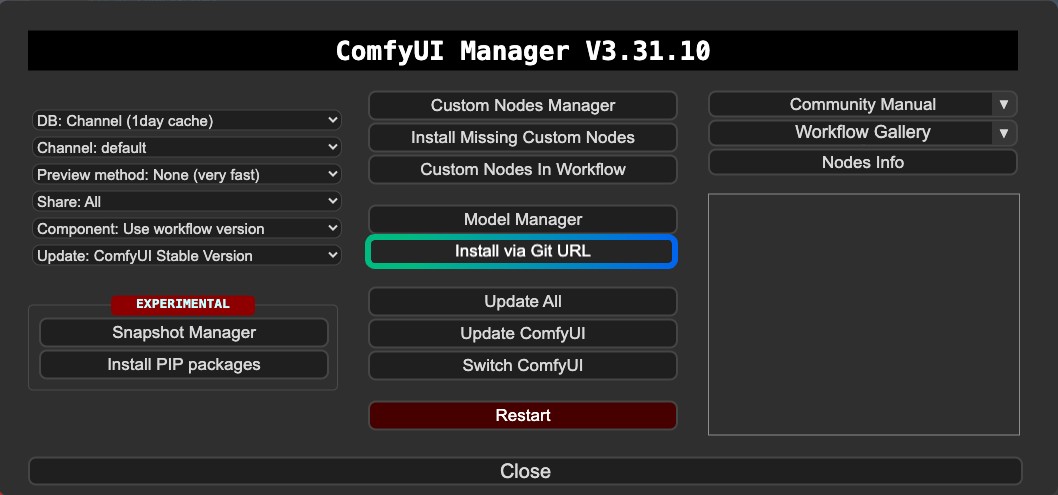
Voici quelques articles qui pourraient vous être utiles:
- Comment installer des nœuds personnalisés
- Résolution du problème "Cette action n'est pas autorisée avec ce niveau de configuration de sécurité"
2. Téléchargement du Fichier de Flux de Travail
Téléchargez le fichier vidéo ci-dessous et faites-le glisser dans ComfyUI pour charger le flux de travail correspondant. J'ai ajouté les informations du modèle dans le fichier, qui vous invitera à télécharger le modèle.
Aperçu Vidéo
Téléchargez les images ci-dessous, que nous utiliserons comme entrées d'image.


3. Installation Manuelle du Modèle
Si vous ne parvenez pas à télécharger avec succès les modèles dans le flux de travail, veuillez télécharger les modèles ci-dessous et les enregistrer à l'emplacement correspondant.
CLIP Vision
VAE
Encodeur de Texte
Modèle de Diffusion Kijai fournit deux versions avec différentes précisions. Vous pouvez en choisir une à télécharger en fonction des performances de votre carte graphique.
| Nom du Fichier | Précision | Taille | Lien de Téléchargement | Exigence de Carte Graphique |
|---|---|---|---|---|
| FramePackI2V_HY_bf16.safetensors | bf16 | 25.7GB | Lien de Téléchargement | Élevée |
| FramePackI2V_HY_fp8_e4m3fn.safetensors | fp8 | 16.3GB | Lien de Téléchargement | Faible |
Emplacement de Sauvegarde des Fichiers
📂 ComfyUI/
├──📂 models/
│ ├──📂 diffusion_models/
│ │ └── FramePackI2V_HY_fp8_e4m3fn.safetensors # ou précision bf16
│ ├──📂 text_encoders/
│ │ ├─── clip_l.safetensors
│ │ └─── llava_llama3_fp16.safetensors
│ ├──📂 clip_vision/
│ │ └── sigclip_vision_patch14_384.safetensors
│ └──📂 vae/
│ └── hunyuan_video_vae_bf16.safetensors4. Complétez le flux de travail correspondant étape par étape
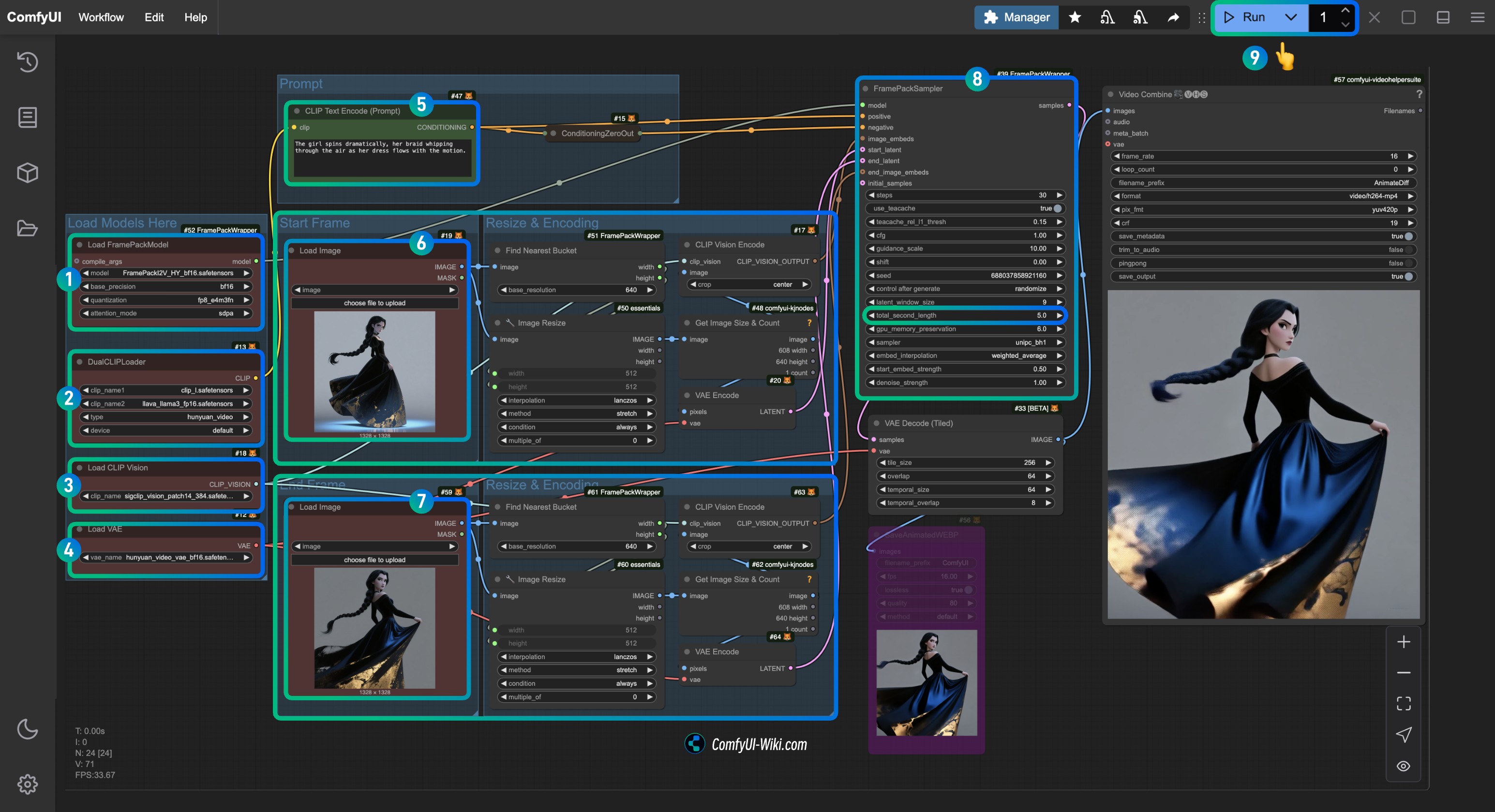
- Assurez-vous que le nœud
Load FramePackModela chargé le modèleFramePackI2V_HY_fp8_e4m3fn.safetensors. - Assurez-vous que le nœud
DualCLIPLoadera chargé:- Le modèle
clip_l.safetensors - Le modèle
llava_llama3_fp16.safetensors
- Le modèle
- Assurez-vous que le nœud
Load CLIP Visiona chargé le modèlesigclip_vision_patch14_384.safetensors. - Vous pouvez charger le modèle
hunyuan_video_vae_bf16.safetensorsdans le nœudLoad VAE. - (Optionnel, si vous utilisez mes images d'entrée) Modifiez le paramètre
Promptdans le nœudCLIP Text Encoderpour saisir la description vidéo que vous souhaitez générer. - Dans le nœud
Load Image, chargezfirst_frame.jpg, qui est lié au traitement d'entrée defirst_frame. - Dans le nœud
Load Image, chargezlast_frame.jpg, qui est lié au traitement d'entrée delast_frame(si vous n'avez pas besoin de la dernière image, vous pouvez la supprimer ou utiliser Bypass pour la désactiver). - Dans le nœud
FramePackSampler, vous pouvez modifier le paramètretotal_second_lengthpour changer la durée de la vidéo; dans mon flux de travail, il est réglé sur5secondes, et vous pouvez l'ajuster selon vos besoins. - Cliquez sur le bouton
Runou utilisez le raccourciCtrl(cmd) + Enterpour exécuter la génération vidéo.
Si vous n'avez pas besoin de la dernière image, veuillez contourner tout le traitement d'entrée lié à last_frame.
Détails des plugins HM-RunningHub et TTPlanetPig
Ces deux plugins utilisent le même emplacement de stockage de modèle, mais comme je l'ai mentionné précédemment, ils téléchargent l'intégralité du dépôt original, qui doit être sauvegardé à un emplacement spécifié. Cela empêche d'autres plugins de réutiliser ces modèles, ce qui entraîne un certain gaspillage d'espace disque. Cependant, ils implémentent la génération des premières et dernières images, donc vous pouvez les essayer si vous le souhaitez.
list index out of range. Vous pouvez consulter ce problème. Actuellement, il a été discuté que la situation possible est:
"La version de torchvision que vous utilisez est probablement incompatible avec la version de PyAV que vous avez installée."
Cependant, après avoir essayé les méthodes mentionnées dans le problème, je n'ai toujours pas pu résoudre le problème. Par conséquent, je ne peux fournir que les informations de tutoriel pertinentes ici. Si vous parvenez à résoudre le problème, n'hésitez pas à fournir des commentaires. Je recommande de vérifier ce problème pour voir si quelqu'un a proposé des solutions similaires.
Installation du Plugin
- Vous pouvez choisir d'installer l'un des suivants ou les deux; les nœuds diffèrent, mais ils sont tous deux simples à utiliser avec un seul nœud:
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
- Améliorez l'expérience d'édition vidéo dans ComfyUI:
Si vous avez utilisé VideoHelperSuite pour des flux de travail liés à la vidéo, il est toujours crucial pour étendre les capacités vidéo de ComfyUI.
1. Téléchargement de Modèle
HM-RunningHub fournit un script Python pour télécharger tous les modèles. Vous devez simplement exécuter ce script et suivre les invites. Mon approche consiste à enregistrer le code ci-dessous en tant que download_models.py et à le placer dans le répertoire racine de ComfyUI/models, puis à exécuter python download_models.py dans le terminal à partir du répertoire correspondant.
cd <votre chemin d'installation>/ComfyUI/models/Ensuite, exécutez le script:
python download_models.pyCela nécessite que votre environnement Python indépendant / environnement système ait installé le package huggingface_hub.
from huggingface_hub import snapshot_download
# Télécharger le modèle HunyuanVideo
snapshot_download(
repo_id="hunyuanvideo-community/HunyuanVideo",
local_dir="HunyuanVideo",
ignore_patterns=["transformer/*", "*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Télécharger le modèle flux_redux_bfl
snapshot_download(
repo_id="lllyasviel/flux_redux_bfl",
local_dir="flux_redux_bfl",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Télécharger le modèle FramePackI2V_HY
snapshot_download(
repo_id="lllyasviel/FramePackI2V_HY",
local_dir="FramePackI2V_HY",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)Vous pouvez également télécharger manuellement les modèles ci-dessous et les enregistrer à l'emplacement correspondant, ce qui signifie télécharger tous les fichiers du dépôt correspondant.
- HunyuanVideo: Lien HuggingFace
- Flux Redux BFL: Lien HuggingFace
- FramePackI2V: Lien HuggingFace
Emplacement de Sauvegarde des Fichiers
comfyui/models/
flux_redux_bfl
├── feature_extractor
│ └── preprocessor_config.json
├── image_embedder
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── image_encoder
│ ├── config.json
│ └── model.safetensors
├── model_index.json
└── README.md
FramePackI2V_HY
├── config.json
├── diffusion_pytorch_model-00001-of-00003.safetensors
├── diffusion_pytorch_model-00002-of-00003.safetensors
├── diffusion_pytorch_model-00003-of-00003.safetensors
├── diffusion_pytorch_model.safetensors.index.json
└── README.md
HunyuanVideo
├── config.json
├── model_index.json
├── README.md
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ ├── model-00001-of-00004.safetensors
│ ├── model-00002-of-00004.safetensors
│ ├── model-00003-of-00004.safetensors
│ ├── model-00004-of-00004.safetensors
│ └── model.safetensors.index.json
├── text_encoder_2
│ ├── config.json
│ └── model.safetensors
├── tokenizer
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.json
├── tokenizer_2
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── vae
├── config.json
└── diffusion_pytorch_model.safetensors2. Téléchargement du Flux de Travail
HM-RunningHub
TTPlanetPig

Commentaires
Connectez-vous avec GitHub pour rejoindre la discussion.