Рабочий процесс и руководство по созданию видео с управлением по аудио Wan2.2-S2V в ComfyUI
Создавайте говорящие аватары с естественной синхронизацией губ с помощью Wan2.2-S2V в ComfyUI. Охватывает настройку модели, пайплайн S2V и примеры рабочих процессов.
Wan2.2-S2V представляет собой значительный прорыв в технологии генерации видео с помощью ИИ, способный создавать динамичный видеоконтент из статических изображений и аудиовходов. Эта инновационная модель отлично справляется с созданием синхронизированных видео с естественной синхронизацией губ, что делает ее особенно ценной для создателей контента, работающих над диалоговыми сценами, музыкальными выступлениями и повествованиями с акцентом на персонажах.
Особенности модели
- Генерация видео с управлением по аудио: Преобразует статические изображения и аудио в синхронизированные видео с естественной синхронизацией губ и выражениями лица
- Кинематографическое качество: Создает видео кинематографического качества с подлинными выражениями лица, движениями тела и языком камеры
- Генерация на уровне минут: Поддерживает создание длинных видео продолжительностью до минуты в одной генерации
- Поддержка нескольких форматов: Работает с реальными людьми, мультяшными персонажами, животными, цифровыми людьми, поддерживает форматы портрета, полтора тела и полного тела
- Улучшенное управление движением: Генерирует действия и окружение из текстовых инструкций с механизмами управления AdaIN и CrossAttention
- Высокие показатели производительности: Достигает FID 15.66, CSIM 0.677 и SSIM 0.734 для превосходного качества видео и согласованности идентичности
Родной рабочий процесс Wan2.2 S2V в ComfyUI
1. Скачать файл рабочего процесса
Скачайте следующий файл рабочего процесса и перетащите его в ComfyUI для загрузки рабочего процесса.
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/wan2.2_s2v/wan2.2-s2v.mp4"
Скачайте следующее изображение и аудио в качестве входных данных:

2. Ссылки на модели
Вы можете найти модели в нашем репозитории
diffusion_models
audio_encoders
vae
text_encoders
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_s2v_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_s2v_14B_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├───📂 audio_encoders/ # Создайте, если не можете найти эту папку
│ │ └─── wav2vec2_large_english_fp16.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors3. Инструкции по рабочему процессу
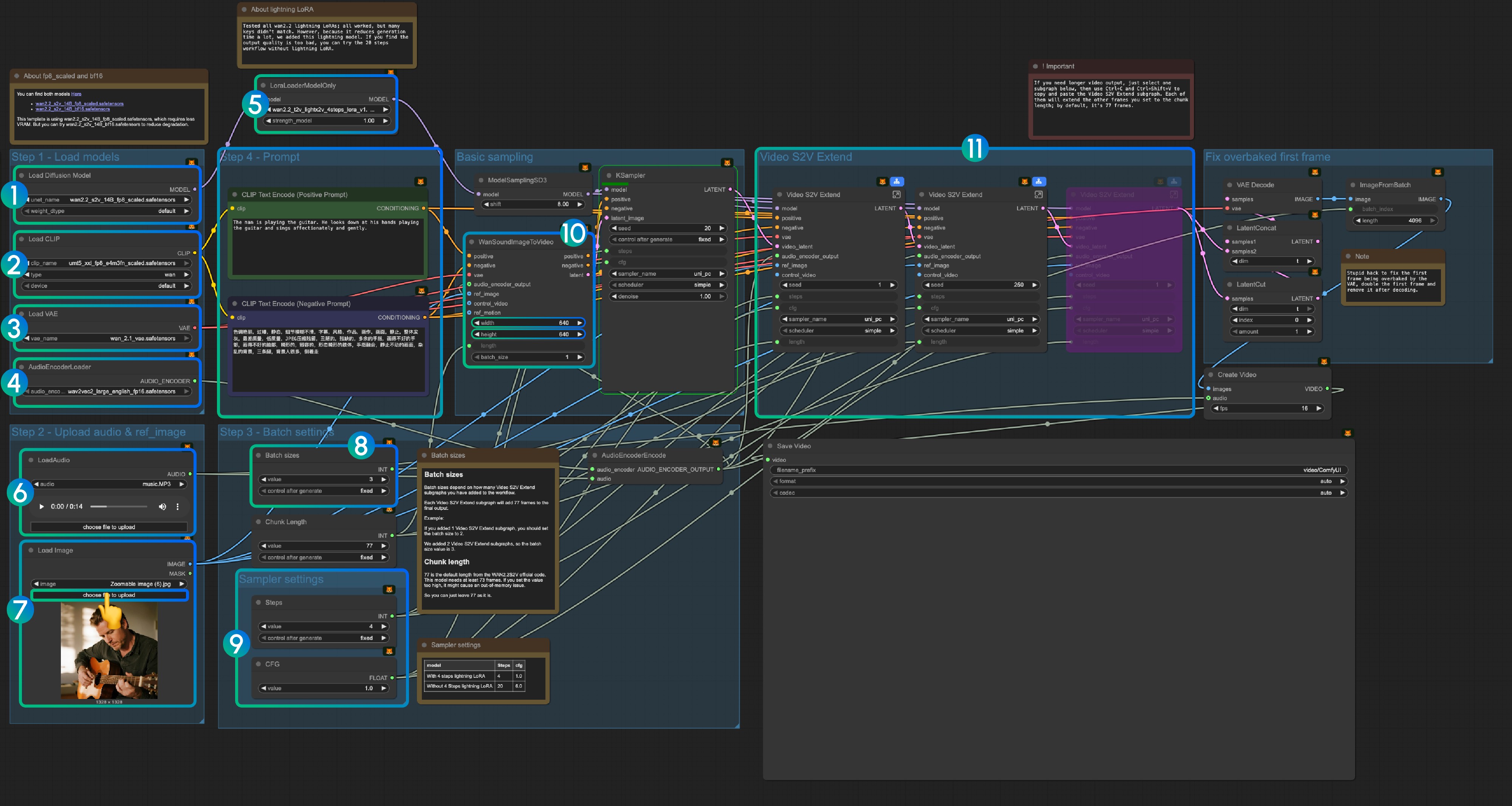
3.1 Lightning LoRA (Опционально, для ускорения)
Lightning LoRA сокращает время генерации с 20 шагов до 4 шагов, но может повлиять на качество. Используйте для быстрого предварительного просмотра, отключите для финального вывода.
3.1.1 Советы по предварительной обработке аудио
Разделение вокала для лучшего результата: Поскольку ядро ComfyUI не включает узлы разделения вокала, мы рекомендуем использовать внешние инструменты для разделения вокала от фоновой музыки перед обработкой. Это особенно важно для генерации диалогов и синхронизации губ, так как чистые вокальные дорожки дают значительно лучшие результаты по сравнению со смешанным аудио с фоновой музыкой или шумом.
3.2 О моделях fp8_scaled и bf16
Вы можете найти обе модели здесь:
Шаблон использует wan2.2_s2v_14B_fp8_scaled.safetensors для снижения использования VRAM. Попробуйте wan2.2_s2v_14B_bf16.safetensors для лучшего качества.
3.3 Пошаговые инструкции по работе
Шаг 1: Загрузка моделей
- Загрузка модели диффузии: Загрузите
wan2.2_s2v_14B_fp8_scaled.safetensorsилиwan2.2_s2v_14B_bf16.safetensors- Рабочий процесс использует
wan2.2_s2v_14B_fp8_scaled.safetensorsдля снижения требований к VRAM - Используйте
wan2.2_s2v_14B_bf16.safetensorsдля лучшего качества вывода
- Рабочий процесс использует
- Загрузка CLIP: Загрузите
umt5_xxl_fp8_e4m3fn_scaled.safetensors - Загрузка VAE: Загрузите
wan_2.1_vae.safetensors - AudioEncoderLoader: Загрузите
wav2vec2_large_english_fp16.safetensors - LoraLoaderModelOnly: Загрузите
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA)- Этот LoRA сокращает время генерации, но может повлиять на качество
- Отключите, если качество вывода недостаточно
- LoadAudio: Загрузите предоставленный аудиофайл или свое собственное аудио
- Load Image: Загрузите эталонное изображение
- Размеры пакета: Установите в соответствии с количеством узлов подграфа Video S2V Extend
- Каждый подграф Video S2V Extend добавляет 77 кадров к выводу
- Пример: 2 подграфа Video S2V Extend = размер пакета 3
- Длина блока: Сохраните значение по умолчанию 77
- Настройки сэмплера: Выберите в зависимости от использования Lightning LoRA
- С 4-ступенчатым Lightning LoRA: steps: 4, cfg: 1.0
- Без Lightning LoRA: steps: 20, cfg: 6.0
- Настройки размера: Установите размеры выходного видео
- Video S2V Extend: Узлы подграфа расширения видео
- Каждое расширение генерирует 77 / 16 = 4,8125 секунд видео
- Расчет необходимых узлов: длина аудио (секунды) × 16 ÷ 77
- Пример: 14 секунд аудио = 224 кадра ÷ 77 = 3 узла расширения
- Используйте Ctrl-Enter или нажмите кнопку запуска для выполнения рабочего процесса
Связанные ссылки
- Код Wan2.2 S2V: GitHub
- Модель Wan2.2 S2V: Hugging Face
Комментарии
Войдите через GitHub, чтобы участвовать в обсуждении.