Полное руководство по рабочим процессам Qwen-Image ComfyUI: нативный, GGUF, Nunchaku
Qwen-Image - это модель MMDiT (мультимодальный диффузионный трансформер) с 20 миллиардами параметров с открытым исходным кодом по лицензии Apache 2.0.
Qwen-Image - это базовая модель генерации изображений, разработанная командой Tongyi Lab Alibaba, использующая архитектуру MMDiT (мультимодальный диффузионный трансформер) с 20 миллиардами параметров, опубликованная с открытым исходным кодом по лицензии Apache 2.0. Модель демонстрирует уникальные технические преимущества в области генерации изображений, особенно выделяясь в рендеринге текста и редактировании изображений.
Основные характеристики:
- Возможность рендеринга многоязычного текста: модель может точно генерировать изображения, содержащие английский, китайский, корейский, японский и другие языки, с четким и читаемым текстом, который гармонирует со стилем изображения
- Поддержка богатых художественных стилей: от реалистичных стилей до художественного творчества, от аниме-стилей до современного дизайна, модель может гибко переключаться между различными визуальными стилями в зависимости от подсказок
- Точная функция редактирования изображений: поддерживает локальные изменения, преобразования стиля и добавление контента к существующим изображениям, сохраняя общую визуальную согласованность
Связанные ресурсы:
Руководство по нативному рабочему процессу Qwen-Image ComfyUI
В рабочем процессе, приложенном к этому документу, используются три различных модели:
- Оригинальная модель Qwen-Image fp8_e4m3fn
- Ускоренная версия за 8 шагов: оригинальная модель Qwen-Image fp8_e4m3fn с использованием LoRA lightx2v за 8 шагов
- Дистиллированная версия: дистиллированная модель Qwen-Image fp8_e4m3fn
Справка по использованию VRAM GPU: RTX4090D 24GB
| Используемая модель | Использование VRAM | Первая генерация | Вторая генерация |
|---|---|---|---|
| fp8_e4m3fn | 86% | ≈ 94s | ≈ 71s |
| fp8_e4m3fn с LoRA lightx2v за 8 шагов | 86% | ≈ 55s | ≈ 34s |
| Дистиллированная версия fp8_e4m3fn | 86% | ≈ 69s | ≈ 36s |
1. Файл рабочего процесса
После обновления ComfyUI вы можете найти файл рабочего процесса в шаблонах или перетащить рабочий процесс ниже в ComfyUI для загрузки

<a className="prose" target='_blank' href="https://raw.githubusercontent.com/Comfy-Org/workflow_templates/refs/heads/main/templates/image_qwen_image.json" style={{ display: 'inline-block', backgroundColor: '#0078D6', color: '#ffffff', padding: '10px 20px', borderRadius: '8px', borderColor: "transparent", textDecoration: 'none', fontWeight: 'bold'}}> <p className="prose" style={{ margin: 0, fontSize: "0.8rem" }}>Скачать официальный рабочий процесс в формате JSON
Дистиллированная версия
2. Скачивание модели
Версии, которые вы можете найти в репозитории ComfyOrg
- Qwen-Image_bf16 (40,9 ГБ)
- Qwen-Image_fp8 (20,4 ГБ)
- Дистиллированная версия (неофициальная, только 15 шагов)
Все модели можно найти на Huggingface или ModelScope
Модель диффузии
Qwen_image_distill
LoRA
Текстовый энкодер
VAE
Расположение хранения моделей
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ ├── qwen_image_fp8_e4m3fn.safetensors
│ │ └── qwen_image_distill_full_fp8_e4m3fn.safetensors ## Дистиллированная версия
│ ├── 📂 loras/
│ │ └── Qwen-Image-Lightning-8steps-V1.0.safetensors ## Модель LoRA ускорения за 8 шагов
│ ├── 📂 vae/
│ │ └── qwen_image_vae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors3. Пошаговое выполнение рабочего процесса
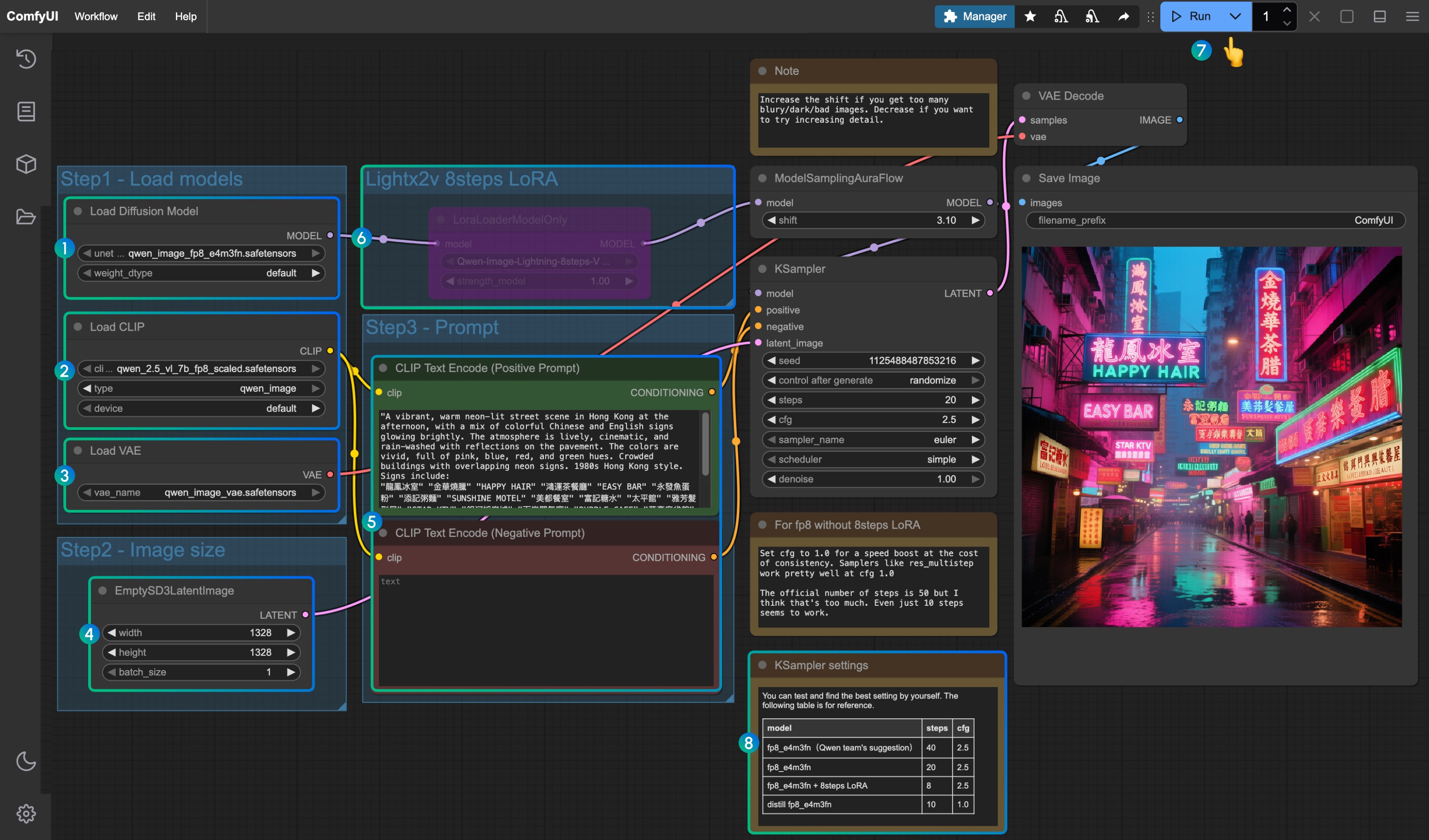
- Убедитесь, что узел
Load Diffusion Modelзагружаетqwen_image_fp8_e4m3fn.safetensors - Убедитесь, что узел
Load CLIPзагружаетqwen_2.5_vl_7b_fp8_scaled.safetensors - Убедитесь, что узел
Load VAEзагружаетqwen_image_vae.safetensors - Убедитесь, что размеры изображения установлены в узле
EmptySD3LatentImage - Установите подсказки в узле
CLIP Text Encoder; на данный момент протестирована поддержка как минимум следующих языков: английский, китайский, корейский, японский, итальянский и т.д. - Чтобы включить LoRA ускорения lightx2v за 8 шагов, выберите его и используйте
Ctrl + Bдля включения узла, а также измените настройки Ksampler в соответствии с параметрами в позиции8 - Нажмите кнопку
Queueили используйте сочетание клавишCtrl(cmd) + Enter, чтобы запустить рабочий процесс - Параметры настройки KSampler, соответствующие различным версиям моделей и рабочих процессов
Рабочий процесс Qwen-Image версии GGUF ComfyUI
Версия GGUF более дружелюбна для пользователей с низким объемом VRAM, и в некоторых конфигурациях весов вам потребуется около 8 ГБ VRAM для запуска Qwen-Image
Справка по использованию VRAM:
| Рабочий процесс | Использование VRAM | Первая генерация | Последующие генерации |
|---|---|---|---|
| qwen-image-Q4_K_S.gguf | 56% | ≈ 135s | ≈ 77s |
| С LoRA за 8 шагов | 56% | ≈ 100s | ≈ 45s |
Адрес модели: Qwen-Image-gguf
1. Обновление или установка пользовательских узлов
Для использования версии GGUF необходимо установить или обновить плагин ComfyUI-GGUF
Пожалуйста, обратитесь к Как установить пользовательские узлы ComfyUI или выполните поиск и установку через Manager
2. Скачивание рабочего процесса

3. Скачивание модели
Версия GGUF использует только модель диффузии, отличную от других
Пожалуйста, посетите https://huggingface.co/city96/Qwen-Image-gguf, чтобы скачать любой вес; как правило, больший размер файла означает лучшее качество, но также требует больше VRAM. В этом руководстве я буду использовать следующую версию:
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen-image-Q4_K_S.gguf # Или любую другую версию, которую вы выберете3. Пошаговое выполнение рабочего процесса GGUF
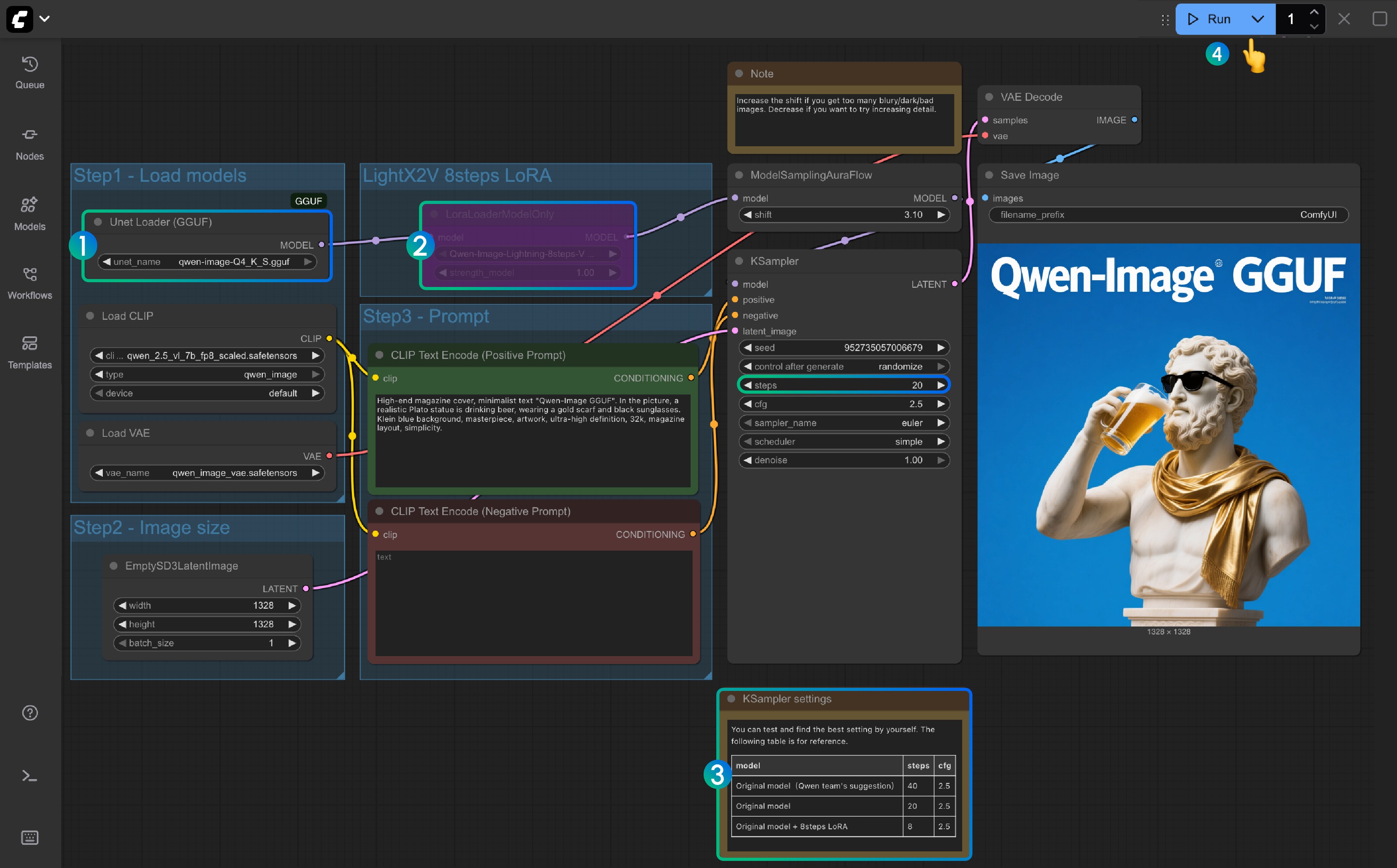
- Убедитесь, что узел
Unet Loader(GGUF)загружаетqwen-image-Q4_K_S.ggufили любую другую версию, которую вы скачали- Убедитесь, что ComfyUI-GGUF установлен и обновлен
- Для
LightX2V 8Steps LoRAпо умолчанию не включено, вы можете выбрать его и использовать Ctrl+B для включения узла - Если LoRA за 8 шагов не включено, количество шагов по умолчанию равно 20; если вы включите LoRA за 8 шагов, установите его на 8
- Здесь приведена справка по установке соответствующего количества шагов
- Нажмите кнопку
Queueили используйте сочетание клавишCtrl(cmd) + Enter, чтобы запустить рабочий процесс
Рабочий процесс версии Nunchaku Qwen-Image
Адрес модели: nunchaku-qwen-image Адрес пользовательского узла: https://github.com/nunchaku-tech/ComfyUI-nunchaku
Qwen Image ControlNet
Рабочий процесс Qwen Image ControlNet DiffSynth-ControlNets Model Patches
Эта модель на самом деле не является controlnet, а представляет собой Model patch, который поддерживает три различных режима управления: canny, depth и inpaint.
Оригинальный адрес модели: DiffSynth-Studio/Qwen-Image ControlNet Адрес рехостинга Comfy Org: Qwen-Image-DiffSynth-ControlNets/model_patches
1. Рабочий процесс и входные изображения
Скачайте изображение ниже и перетащите его в ComfyUI для загрузки соответствующего рабочего процесса

Скачайте изображение ниже как входное:

2. Ссылки на модели
Другие модели соответствуют базовому рабочему процессу Qwen-Image. Вам нужно только скачать следующие модели и сохранить их в папке ComfyUI/models/model_patches:
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. Инструкции по использованию рабочего процесса
В настоящее время diffsynth имеет три модели патчей: модели Canny, Depth и Inpaint.
Если вы впервые используете рабочие процессы, связанные с ControlNet, вам нужно понимать, что изображения, используемые для управления, должны быть предварительно обработаны в поддерживаемых форматах изображений, прежде чем они могут быть использованы и распознаны моделью.

- Canny: Обработанный canny, контуры линейного рисунка
- Depth: Предварительно обработанная карта глубины, показывающая пространственные отношения
- Inpaint: Требуется использование маски для отметки областей, которые нужно перерисовать
Поскольку эта модель патча разделена на три различные модели, вам нужно выбрать правильный тип предварительной обработки при вводе, чтобы обеспечить правильную предварительную обработку изображения.
Инструкции по использованию модели Canny ControlNet
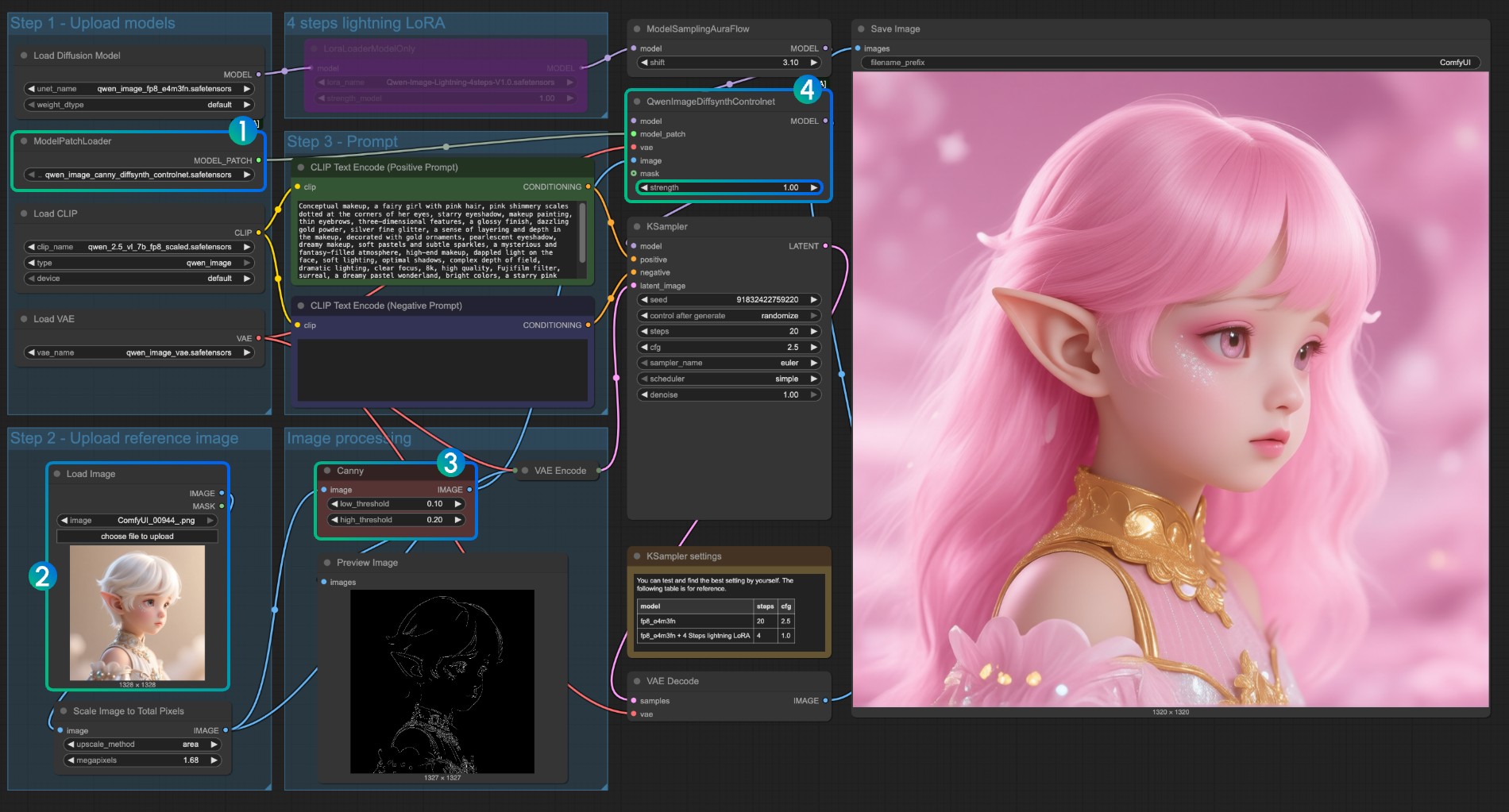
- Убедитесь, что загружен
qwen_image_canny_diffsynth_controlnet.safetensors - Загрузите входное изображение для последующей обработки
- Узел Canny является нативным узлом предварительной обработки, который будет предварительно обрабатывать входное изображение в соответствии с вашими установленными параметрами для управления генерацией
- При необходимости вы можете изменить параметр
strengthузлаQwenImageDiffsynthControlnetдля управления силой управления линейным рисунком - Нажмите кнопку
Runили используйте сочетание клавишCtrl(cmd) + Enterдля запуска рабочего процесса
Для использования qwen_image_depth_diffsynth_controlnet.safetensors вам нужно предварительно обработать изображение в карту глубины, заменив часть
image processing. Для этого использования, пожалуйста, обратитесь к методу обработки InstantX в этом документе. Другие части аналогичны использованию модели Canny.
Инструкции по использованию модели Inpaint ControlNet
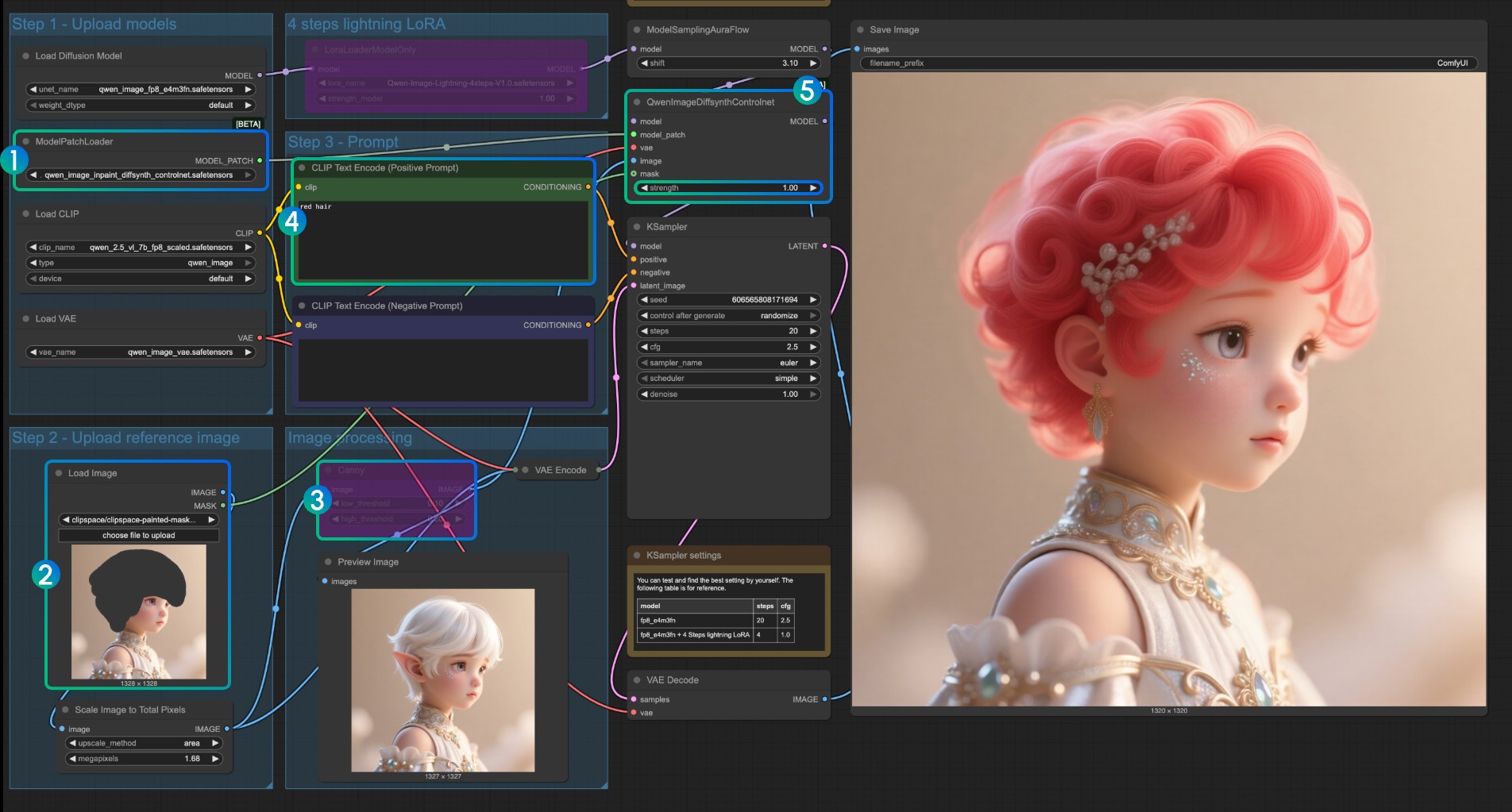
Для модели Inpaint требуется использование редактора масок для рисования маски и использования ее в качестве входного условия управления.
- Убедитесь, что
ModelPatchLoaderзагружает модельqwen_image_inpaint_diffsynth_controlnet.safetensors - Загрузите изображение и используйте редактор масок для рисования маски. Вам нужно подключить выход
maskсоответствующего узлаLoad Imageк входуmaskQwenImageDiffsynthControlnet, чтобы обеспечить загрузку соответствующей маски - Используйте сочетание клавиш
Ctrl-Bдля установки оригинального Canny в рабочем процессе в режим обхода, чтобы соответствующая обработка узла Canny не вступила в силу - В
кодировщике текста CLIPвведите стиль, который вы хотите изменить для замаскированной части - При необходимости вы можете изменить параметр
strengthузлаQwenImageDiffsynthControlnetдля управления соответствующей силой управления - Нажмите кнопку
Runили используйте сочетание клавишCtrl(cmd) + Enterдля запуска рабочего процесса
Рабочий процесс Qwen Image Union ControlNet LoRA
Оригинальный адрес модели: DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Адрес рехостинга Comfy Org: qwen_image_union_diffsynth_lora.safetensors: LoRA управления структурой изображения, поддерживающий canny, depth, pose, lineart, softedge, normal, openpose
1. Рабочий процесс и входные изображения
Скачайте изображение ниже и перетащите его в ComfyUI для загрузки рабочего процесса

Скачайте изображение ниже как входное:

2. Ссылки на модели
Скачайте следующую модель. Поскольку это модель LoRA, она должна быть сохранена в папке ComfyUI/models/loras/:
- qwen_image_union_diffsynth_lora.safetensors: LoRA управления структурой изображения, поддерживающий canny, depth, pose, lineart, softedge, normal, openpose
3. Инструкции рабочего процесса
Эта модель представляет собой унифицированный LoRA управления, который поддерживает canny, depth, pose, lineart, softedge, normal, openpose и другие элементы управления. Поскольку многие нативные узлы предварительной обработки изображений не полностью поддерживаются, вам может понадобиться что-то вроде comfyui_controlnet_aux для завершения другой предварительной обработки изображений.
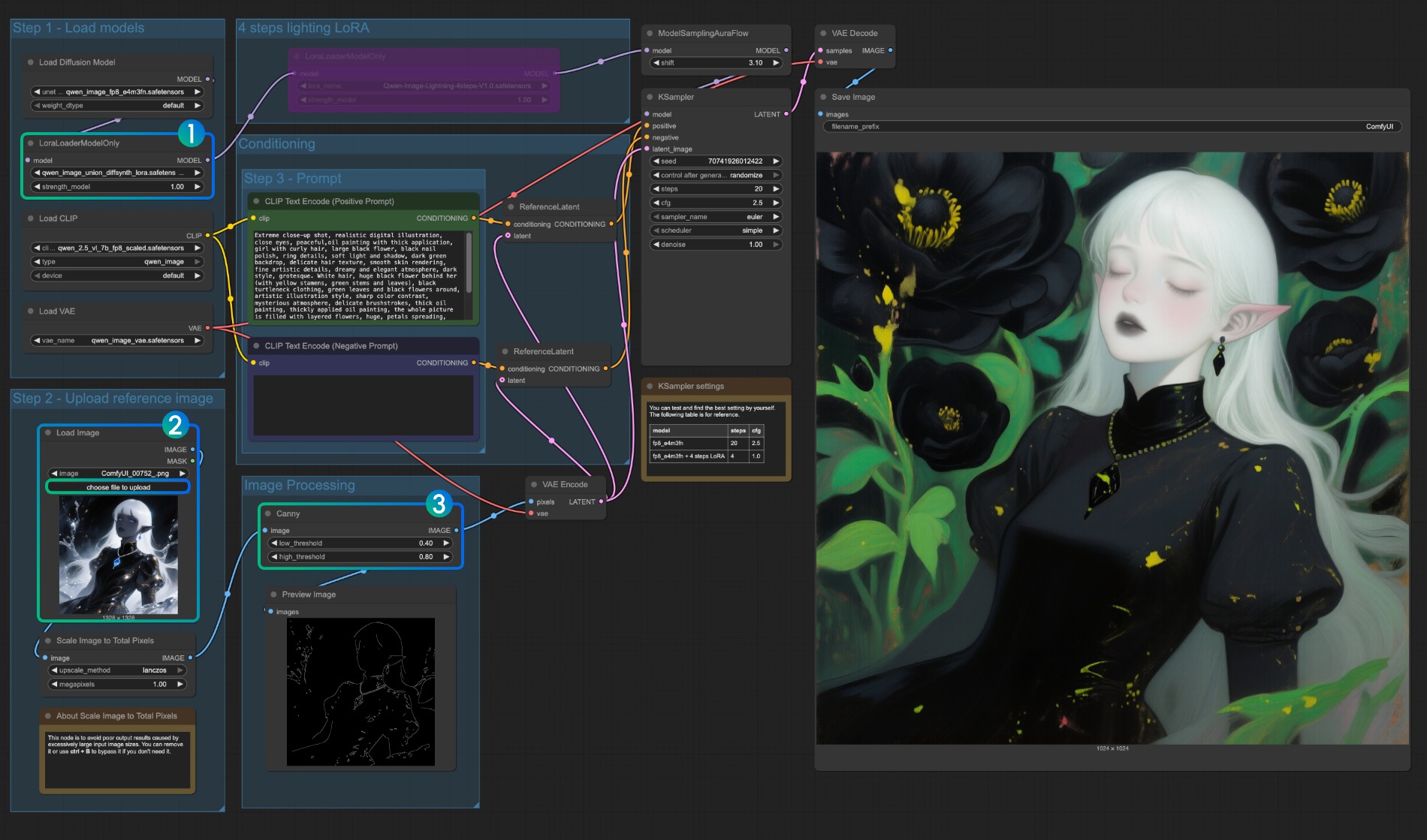
- Убедитесь, что
LoraLoaderModelOnlyправильно загружает модельqwen_image_union_diffsynth_lora.safetensors - Загрузите входное изображение
- При необходимости вы можете настроить параметры узла
Canny. Поскольку различные входные изображения требуют различных настроек параметров для получения лучших результатов предварительной обработки изображений, вы можете попробовать настроить соответствующие значения параметров для получения большего/меньшего количества деталей - Нажмите кнопку
Runили используйте сочетание клавишCtrl(cmd) + Enterдля запуска рабочего процесса
Для других типов управления вам также нужно заменить часть обработки изображения.
Комментарии
Войдите через GitHub, чтобы участвовать в обсуждении.