Полное пошаговое руководство по workflow Frame Pack в ComfyUI
В этом руководстве вы узнаете, как использовать workflow Frame Pack в ComfyUI, с подробными пошаговыми инструкциями.
FramePack — это технология генерации видео с помощью искусственного интеллекта, разработанная командой доктора Люминя Чжана из Стэнфордского университета, автора ControlNet. Основные особенности FramePack:
- Динамическое сжатие контекста: Кадры видео классифицируются по важности — ключевые кадры сохраняют 1536 признаков, а переходные упрощаются до 192.
- Устойчивое к дрейфу семплирование: Используются методы двунаправленной памяти и обратной генерации, чтобы избежать дрейфа изображения и обеспечить непрерывность действий.
- Сниженные требования к видеопамяти: Порог VRAM для генерации видео снижен с профессионального уровня (12ГБ+) до пользовательского (достаточно 6ГБ VRAM), что позволяет даже владельцам ноутбуков RTX 3060 создавать качественные видео до 60 секунд.
- Открытый исходный код и интеграция: FramePack открыт и интегрирован в видеомодель Tencent Hunyuan, поддерживает мультимодальные входные данные (текст + изображения + голос) и интерактивную генерацию в реальном времени.
Оригинальные ссылки, связанные с Frame Pack
- Официальный репозиторий: https://github.com/lllyasviel/FramePack/
- Интеграционный пакет для Windows (без ComfyUI): https://github.com/lllyasviel/FramePack/releases/tag/windows
Пример промпта
lllyasviel предоставляет GPT-промпт для генерации видео в соответствующем репозитории. Если вы не знаете, как составлять промпты для workflow Frame Pack, попробуйте следующее:
- Скопируйте промпт ниже и отправьте его в GPT.
- После того как GPT поймёт задачу, предоставьте ему нужные изображения — вы получите подходящие промпты.
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.Текущее внедрение Frame Pack в ComfyUI
В настоящее время существует три автора пользовательских узлов, которые реализовали поддержку Frame Pack в ComfyUI:
- Kijai: ComfyUI-FramePackWrapper
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
Отличия между этими пользовательскими узлами
Ниже приведено объяснение различий в workflow, реализованных этими узлами.
Пользовательский плагин Kijai
Kijai перепаковал соответствующие модели, и, скорее всего, вы уже использовали связанные с ним пользовательские узлы. Спасибо ему за столь быстрые обновления!
Похоже, версия Kijai пока не зарегистрирована в ComfyUI Manager, поэтому её нельзя установить через Менеджер пользовательских узлов. Необходимо установить через Git в Менеджере или вручную.
Особенности:
- Поддержка генерации видео по первому и последнему кадру
- Требуется установка через Git или вручную
- Модели можно использовать повторно
Пользовательские плагины HM-RunningHub и TTPlanetPig
Эти два пользовательских узла — модифицированные версии на основе одного и того же кода, изначально созданного HM-RunningHub. Затем TTPlanetPig реализовал генерацию видео по первому и последнему кадру на основе исходного кода плагина. Подробнее можно посмотреть этот PR.
Структура папок моделей, используемых этими двумя узлами, совпадает: используются оригинальные файлы моделей из репозитория без перепаковки. Поэтому эти файлы моделей нельзя использовать в других пользовательских узлах, которые не поддерживают такую структуру, что приводит к большему расходу дискового пространства.
Особенности:
- Поддержка генерации видео по первому и последнему кадру
- Загруженные файлы моделей могут быть непригодны для использования в других узлах или workflow
- Требуется больше места на диске, так как модели не перепакованы
- Возможны проблемы совместимости с зависимостями
Workflow Kijai ComfyUI-FramePackWrapper FLF2V для ComfyUI
1. Установка плагинов
Для установки ComfyUI-FramePackWrapper может понадобиться использовать установку через Git в Менеджере:
Вот несколько полезных статей:
- Как установить пользовательские узлы
- Решение проблемы "This action is not allowed with this security level configuration"
2. Загрузка файла workflow
Скачайте видеофайл ниже и перетащите его в ComfyUI для загрузки соответствующего workflow. Я добавил информацию о моделях в файл, поэтому появится подсказка о необходимости загрузки модели.
Превью видео
Скачайте изображения ниже, которые будут использоваться в качестве входных данных.


3. Ручная установка моделей
Если не удалось автоматически скачать модели при загрузке workflow, скачайте их по ссылкам ниже и сохраните в соответствующие папки.
CLIP Vision
VAE
Текстовые энкодеры
Диффузионная модель
Kijai предоставляет две версии с разной точностью. Выберите подходящую в зависимости от производительности вашей видеокарты.
| Имя файла | Точность | Размер | Ссылка для скачивания | Требования к видеокарте |
|---|---|---|---|---|
| FramePackI2V_HY_bf16.safetensors | bf16 | 25.7GB | Скачать | Высокие |
| FramePackI2V_HY_fp8_e4m3fn.safetensors | fp8 | 16.3GB | Скачать | Низкие |
Путь для сохранения файлов
📂 ComfyUI/
├──📂 models/
│ ├──📂 diffusion_models/
│ │ └── FramePackI2V_HY_fp8_e4m3fn.safetensors # or bf16 precision
│ ├──📂 text_encoders/
│ │ ├─── clip_l.safetensors
│ │ └─── llava_llama3_fp16.safetensors
│ ├──📂 clip_vision/
│ │ └── sigclip_vision_patch14_384.safetensors
│ └──📂 vae/
│ └── hunyuan_video_vae_bf16.safetensors4. Завершение соответствующего шага workflow по шагам
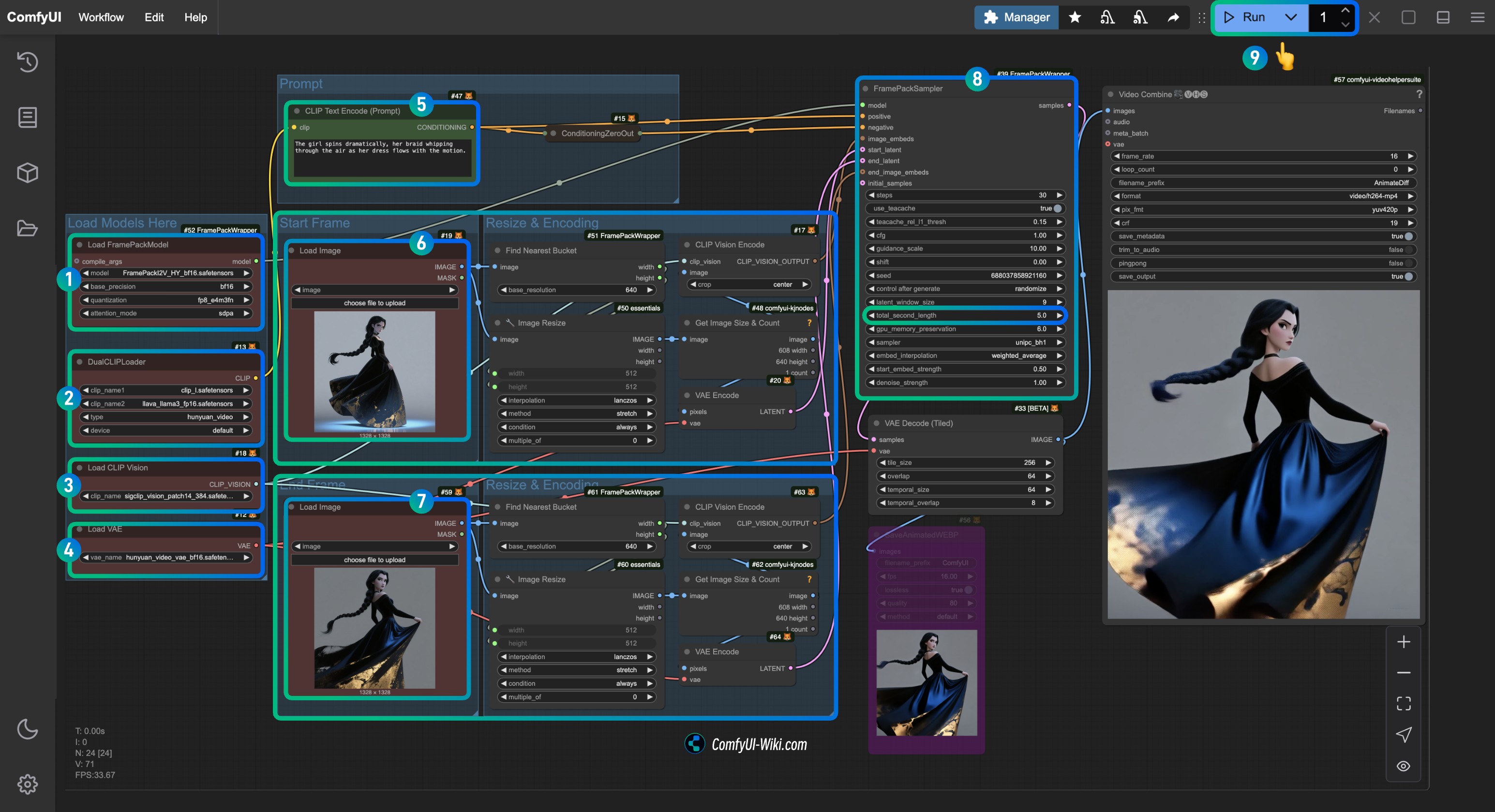
- Убедитесь, что узел
Load FramePackModelзагрузил модельFramePackI2V_HY_fp8_e4m3fn.safetensors. - Убедитесь, что узел
DualCLIPLoaderзагрузил:- модель
clip_l.safetensors - модель
llava_llama3_fp16.safetensors
- модель
- Убедитесь, что узел
Load CLIP Visionзагрузил модельsigclip_vision_patch14_384.safetensors. - В узле
Load VAEвы можете загрузить модельhunyuan_video_vae_bf16.safetensors. - (Необязательно, если вы используете мои входные изображения) Измените параметр
Promptв узлеCLIP Text Encoder, чтобы ввести описание видео, которое вы хотите сгенерировать. - В узле
Load Imageзагрузитеfirst_frame.jpg, который относится к обработке входного кадраfirst_frame. - В узле
Load Imageзагрузитеlast_frame.jpg, который относится к обработке входного кадраlast_frame(если последний кадр не нужен, вы можете удалить его или использовать Bypass для его отключения). - В узле
FramePackSamplerвы можете изменить параметрtotal_second_length, чтобы задать продолжительность видео; в моём workflow он установлен на 5 секунд, вы можете настроить это значение по своему усмотрению. - Нажмите кнопку
Runили используйте сочетание клавишCtrl(cmd) + Enterдля запуска генерации видео.
Если последний кадр не нужен, пожалуйста, обойдите всю обработку входных данных, связанную с last_frame.
Кастомные плагины HM-RunningHub и TTPlanetPig
Эти два плагина используют одну и ту же папку для хранения моделей, но, как я упоминал ранее, они скачивают весь оригинальный репозиторий, который нужно сохранить в определённом месте. Это мешает другим плагинам использовать эти модели повторно, что приводит к некоторой потере дискового пространства. Однако они реализуют генерацию первого и последнего кадров, так что вы можете попробовать их, если хотите.
list index out of range. Вы можете ознакомиться с этим issue. На данный момент обсуждается, что возможная причина:
"Версия torchvision, которую вы используете, вероятно, несовместима с установленной у вас версией PyAV."
Однако после попыток методов, описанных в issue, мне не удалось решить проблему. Поэтому я могу только предоставить соответствующую информацию по использованию. Если вам удастся решить эту ошибку, пожалуйста, дайте обратную связь. Рекомендую проверить этот issue, чтобы узнать, предлагал ли кто-то похожие решения.
Установка плагинов
- Вы можете установить один из следующих плагинов или оба; узлы отличаются, но оба просты в использовании и требуют только одного узла:
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
- Для улучшения работы с видео в ComfyUI:
Если вы уже использовали VideoHelperSuite для работы с видео, этот плагин по-прежнему важен для расширения возможностей ComfyUI по работе с видео.
1. Загрузка моделей
HM-RunningHub предоставляет Python-скрипт для скачивания всех моделей. Вам нужно просто запустить этот скрипт и следовать инструкциям. Я сохраняю код ниже как download_models.py и помещаю его в корневую папку ComfyUI/models, затем запускаю в терминале команду python download_models.py из этой папки.
cd <your installation path>/ComfyUI/models/Затем запустите скрипт:
python download_models.pyЭто требует установки пакета huggingface_hub в вашей независимой среде Python / системной среде.
from huggingface_hub import snapshot_download
# Download HunyuanVideo model
snapshot_download(
repo_id="hunyuanvideo-community/HunyuanVideo",
local_dir="HunyuanVideo",
ignore_patterns=["transformer/*", "*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download flux_redux_bfl model
snapshot_download(
repo_id="lllyasviel/flux_redux_bfl",
local_dir="flux_redux_bfl",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download FramePackI2V_HY model
snapshot_download(
repo_id="lllyasviel/FramePackI2V_HY",
local_dir="FramePackI2V_HY",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)Вы также можете вручную скачать модели ниже и сохранить их в соответствующем месте, что означает загрузку всех файлов из соответствующего репозитория.
- HunyuanVideo: HuggingFace Link
- Flux Redux BFL: HuggingFace Link
- FramePackI2V: HuggingFace Link
Путь для сохранения файлов
comfyui/models/
flux_redux_bfl
├── feature_extractor
│ └── preprocessor_config.json
├── image_embedder
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── image_encoder
│ ├── config.json
│ └── model.safetensors
├── model_index.json
└── README.md
FramePackI2V_HY
├── config.json
├── diffusion_pytorch_model-00001-of-00003.safetensors
├── diffusion_pytorch_model-00002-of-00003.safetensors
├── diffusion_pytorch_model-00003-of-00003.safetensors
├── diffusion_pytorch_model.safetensors.index.json
└── README.md
HunyuanVideo
├── config.json
├── model_index.json
├── README.md
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ ├── model-00001-of-00004.safetensors
│ ├── model-00002-of-00004.safetensors
│ ├── model-00003-of-00004.safetensors
│ ├── model-00004-of-00004.safetensors
│ └── model.safetensors.index.json
├── text_encoder_2
│ ├── config.json
│ └── model.safetensors
├── tokenizer
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.json
├── tokenizer_2
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── vae
├── config.json
└── diffusion_pytorch_model.safetensors2. Загрузка workflow
HM-RunningHub
TTPlanetPig

Комментарии
Войдите через GitHub, чтобы участвовать в обсуждении.