NVIDIA Releases LocateAnything-3B - Open-Source Vision-Language Grounding Model with Parallel Box Decoding
NVIDIA open-sources LocateAnything-3B, a vision-language grounding model featuring Parallel Box Decoding (PBD) for fast and precise object localization, supporting object detection, GUI element grounding, OCR localization, and point-based grounding across diverse domains
On June 29, 2026, NVIDIA officially released LocateAnything-3B, an open-source vision-language grounding model that enables fast and high-quality visual localization from natural language instructions. The model introduces Parallel Box Decoding (PBD), a novel decoding paradigm that predicts complete bounding box coordinates in a single parallel step rather than autoregressive token-by-token decoding, achieving up to 2.5× higher throughput compared to prior approaches.
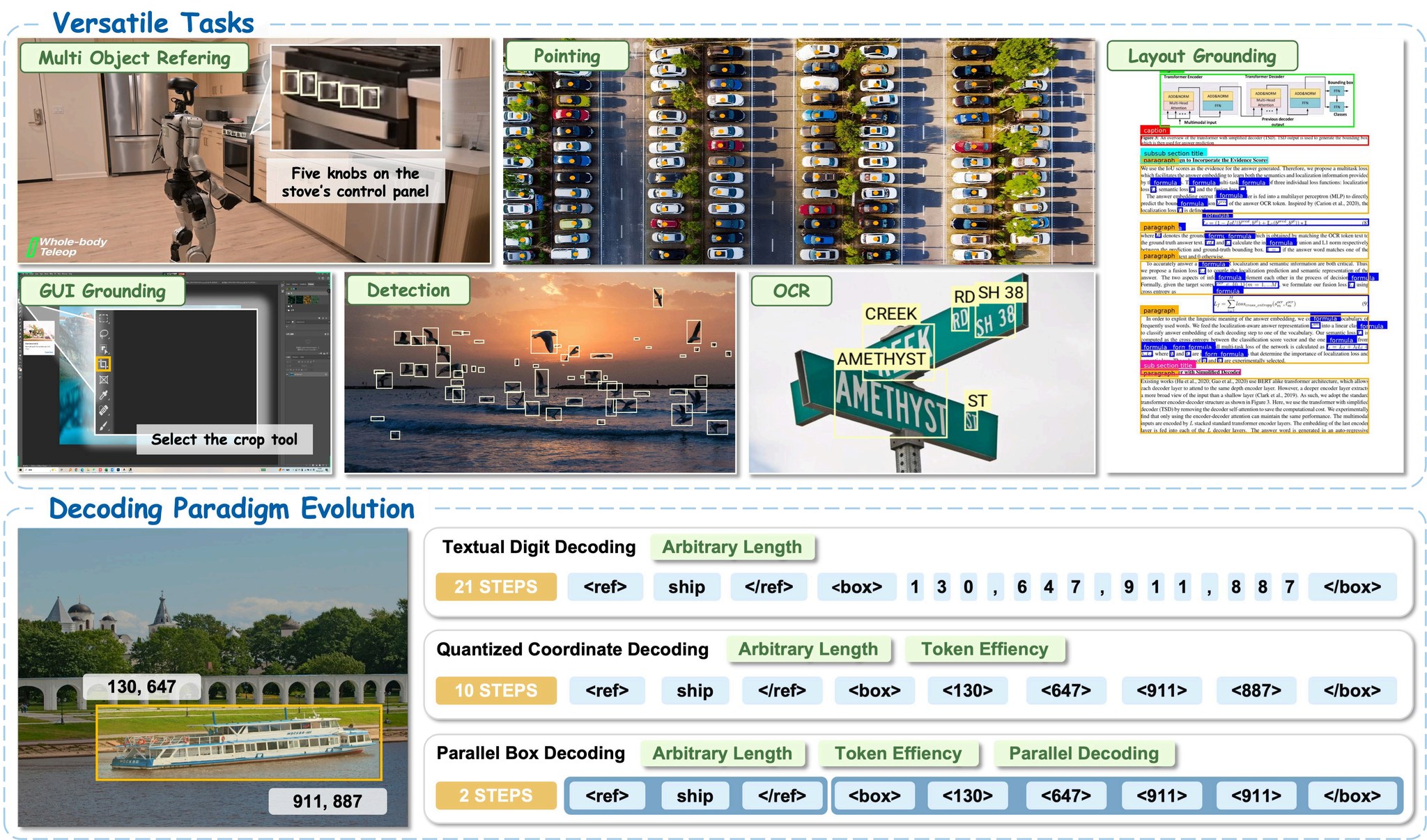 LocateAnything enables precise object localization across diverse domains including natural scenes, robotics, GUI interaction, and document understanding.
LocateAnything enables precise object localization across diverse domains including natural scenes, robotics, GUI interaction, and document understanding.
Model Overview
LocateAnything is a generalist vision-language grounding model developed as part of NVIDIA's Eagle VLM model family. It supports a wide range of localization tasks:
- Referring Expression Grounding: Locate objects described by natural language
- Open-Set Object Detection: Detect common and long-tail object categories
- GUI Element Grounding: Localize UI elements for agentic systems
- Document Layout Grounding: OCR and text localization
- Point-Based Localization: Fine-grained spatial reasoning via pointing
The model has been integrated into NVIDIA's Nemotron and Cosmos product lines, powering computer use and visual grounding features.
Core Innovation: Parallel Box Decoding (PBD)
Traditional visual grounding models generate bounding box coordinates autoregressively, token by token. LocateAnything introduces Parallel Box Decoding:
- Predicts complete bounding boxes (
x1, y1, x2, y2) and points in parallel structured units - Uses a block-wise multi-token prediction framework
- Achieves 2.5× higher throughput without sacrificing geometric consistency
- Supports three inference modes:
- Fast Mode: Parallel decoding for maximum speed
- Slow Mode: Autoregressive decoding for maximum accuracy
- Hybrid Mode: Default; parallel decoding with fallback to autoregressive for format irregularities
Technical Architecture
| Component | Details |
|---|---|
| Architecture | Transformer-based VLM |
| Vision Encoder | MoonViT (native resolution, up to 2.5K) |
| Language Model | Qwen2.5-3B-Instruct |
| Multimodal Projector | MLP projector |
| Total Parameters | 3B |
| Max Image Resolution | 2.5K (production), up to 4K with batch inference |
| Max Sequence Length | 25,600 tokens (training), 8,192 generation tokens (inference) |
| Output Format | Block-based: Semantic, Box, Negative, and End blocks |
Training Data
- 12M unique images, 138M+ queries, 785M bounding boxes
- Multi-domain: natural scenes, robotics, driving, GUI, documents
- Hybrid data sources: human-curated, open-source, model-assisted synthetic annotations
Performance
LocateAnything demonstrates strong performance across multiple grounding benchmarks including COCO/LVIS for open-set detection, ScreenSpot-Pro for GUI grounding, and various document layout understanding benchmarks.
Inference Efficiency
Using the la_flash attention backend with batch hybrid inference:
| Backend | Time (4K probe) | Peak Memory |
|---|---|---|
| SDPA (dense masks) | 8.26s | 35.12 GB |
| la_flash (FlashAttention) | 8.03s | 11.71 GB |
Open Source and Availability
LocateAnything-3B is released under the NVIDIA License for non-commercial research and development use:
- HuggingFace Model: nvidia/LocateAnything-3B
- GitHub Code: NVlabs/Eagle/Embodied
- Online Demo: HuggingFace Spaces
- Technical Report: arXiv:2605.27365
- Project Page: NVIDIA Research
Hardware Requirements
Optimized for NVIDIA GPUs (Ampere, Blackwell, Hopper, Lovelace) with BF16 precision and KV cache. Batch inference via la_flash backend reduces peak memory from 35GB to ~12GB on A100.
Related Links
- GitHub Repository: https://github.com/NVlabs/Eagle/tree/main/Embodied
- HuggingFace Model: https://huggingface.co/nvidia/LocateAnything-3B
- Online Demo: https://huggingface.co/spaces/nvidia/LocateAnything
- Technical Report: https://arxiv.org/abs/2605.27365