OmniAvatar: 음성 제어를 통한 효율적인 가상 인물 동영상 생성 모델 출시
ComfyUI Wikinews
OmniAvatar 모델이 오픈소스로 공개되어, 자연스러운 움직임과 풍부한 표정을 가진 음성 제어 전신 가상 인물 동영상 생성이 가능해짐. 팟캐스트, 상호작용, 다이나믹한 장면 등 다양한 용도에 대응
OmniAvatar는 저장대학교와 알리바바 그룹이 공동 개발한 오픈소스 프로젝트(2025년 6월 출시)입니다. 1장의 참조 이미지, 음성 입력, 텍스트 프롬프트를 통해 자연스럽고 유창한 가상 인물 동영상을 생성하는 음성 제어 전신 가상 인물 동영상 생성 모델입니다. 정확한 립싱크, 전신 모션 제어, 멀티씬 상호작용을 지원하며, 디지털 휴먼 기술에서 큰 진전을 보여주고 있습니다.
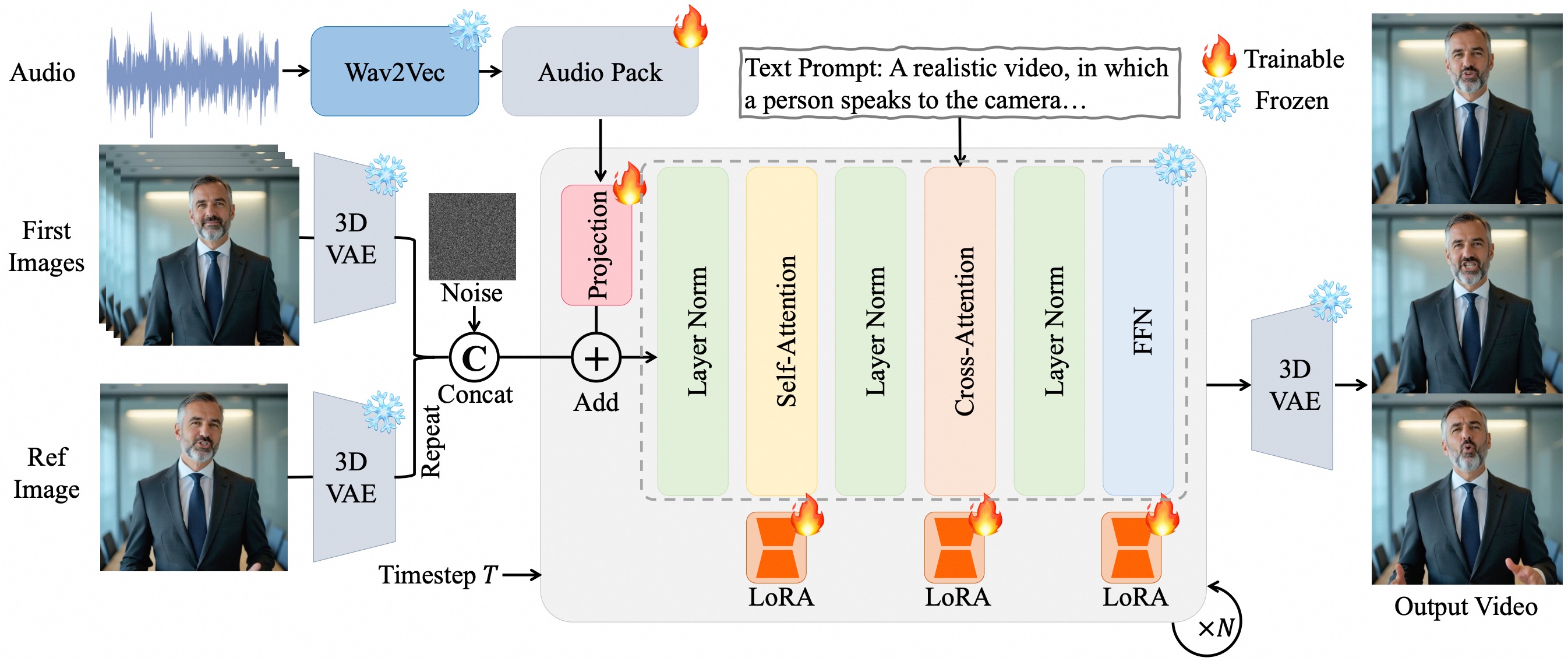
I. 주요 기술 원리
픽셀 레벨의 멀티레이어 음성 임베딩
- Wav2Vec2를 사용하여 음성 특징을 추출하고, Audio Pack 모듈을 통해 음성 특징을 동영상의 잠재 공간에 픽셀 단위로 정렬하여, 확산 모델(DiT)의 여러 시간 레이어에 음성 정보를 임베딩합니다.
- 장점: 기존 모델보다 높은 정밀도의 동기화를 실현하고, 프레임 레벨의 립싱크(숨소리에 의한 미세한 표정 등)와 전신 모션의 협조(어깨 움직임과 제스처의 리듬 등)를 달성합니다.
LoRA 미세조정 전략
- Transformer의 주의 층과 피드포워드 네트워크 층에 저랭크 적응 행렬(LoRA)을 삽입하여, 기본 모델의 능력을 유지하면서 추가 파라미터만을 조정합니다.
- 효과: 과적합을 방지하고, 음성-동영상 정렬의 안정성을 향상시키며, 텍스트 프롬프트를 통한 상세한 제어(제스처의 진폭이나 감정 표현 등)를 지원합니다.
장시간 동영상 생성 메커니즘
- 참조 이미지의 잠재 인코딩을 아이덴티티 앵커로 통합하고, 프레임 오버랩 전략과 단계적 생성 알고리즘을 결합하여, 장시간 동영상에서의 색상 열화나 아이덴티티 불일치 문제를 완화합니다.
II. 주요 특징과 혁신
전신 모션 생성
- 기존의 "머리만 움직이는" 제한을 넘어, 자연스럽고 협조적인 신체 동작(인사, 건배, 댄스 등)을 생성합니다.
멀티모달 제어 기능
- 텍스트 프롬프트를 통한 제어: 액션("건배하며 축하하기" 등), 배경("별이 빛나는 라이브 스튜디오" 등), 감정("기쁨/분노" 등)을 설명문을 통해 정확하게 조정합니다.
- 오브젝트와의 상호작용: 가상 인물이 장면 내의 오브젝트와 상호작용하는 기능(상품 시연 등)을 지원하여, e커머스 마케팅에서의 리얼리즘을 향상시킵니다.
다국어 지원과 장시간 동영상
- 중국어, 영어, 일본어를 포함한 31개 언어의 립싱크 적응을 지원하며, 10초 이상의 일관성 있는 동영상 생성이 가능합니다(고사양 VRAM 장치 필요).
III. 풍부한 동영상 데모
OmniAvatar의 공식 웹사이트에서는 다양한 시나리오와 제어 기능을 커버하는 다수의 실제 데모를 제공하고 있습니다. 다음은 선택된 동영상입니다:
1. 스피커의 전신 모션과 표정
2. 다양한 액션과 감정 표현
3. 인물-오브젝트 상호작용
4. 배경과 장면 제어
5. 감정 표현
6. 팟캐스트와 노래 시나리오
더 많은 데모는 OmniAvatar 공식 웹사이트를 참조하세요
IV. 오픈소스와 에코시스템
- 오픈소스 저장소: GitHub - OmniAvatar
- 모델 다운로드: HuggingFace - OmniAvatar-14B
- 연구 논문: arXiv:2506.18866
콘텐츠는 OmniAvatar 공식 웹사이트, GitHub, 및 관련 오픈소스 자료를 참조하였습니다.
댓글
GitHub로 로그인하고 토론에 참여하세요.