OmniAvatar: 音声制御による効率的な仮想人物動画生成モデルのリリース
news
OmniAvatarモデルがオープンソース化され、自然な動きと豊かな表情を持つ音声制御のフルボディ仮想人物動画の生成が可能に。ポッドキャスト、インタラクション、ダイナミックなシーンなど、様々な用途に対応
OmniAvatarは浙江大学とアリババグループが共同開発したオープンソースプロジェクト(2025年6月リリース)です。1枚の参照画像、音声入力、テキストプロンプトを通じて、自然で流暢な仮想人物動画を生成する音声制御のフルボディ仮想人物動画生成モデルです。正確なリップシンク、フルボディモーション制御、マルチシーンインタラクションをサポートし、デジタルヒューマン技術において大きな進歩を示しています。
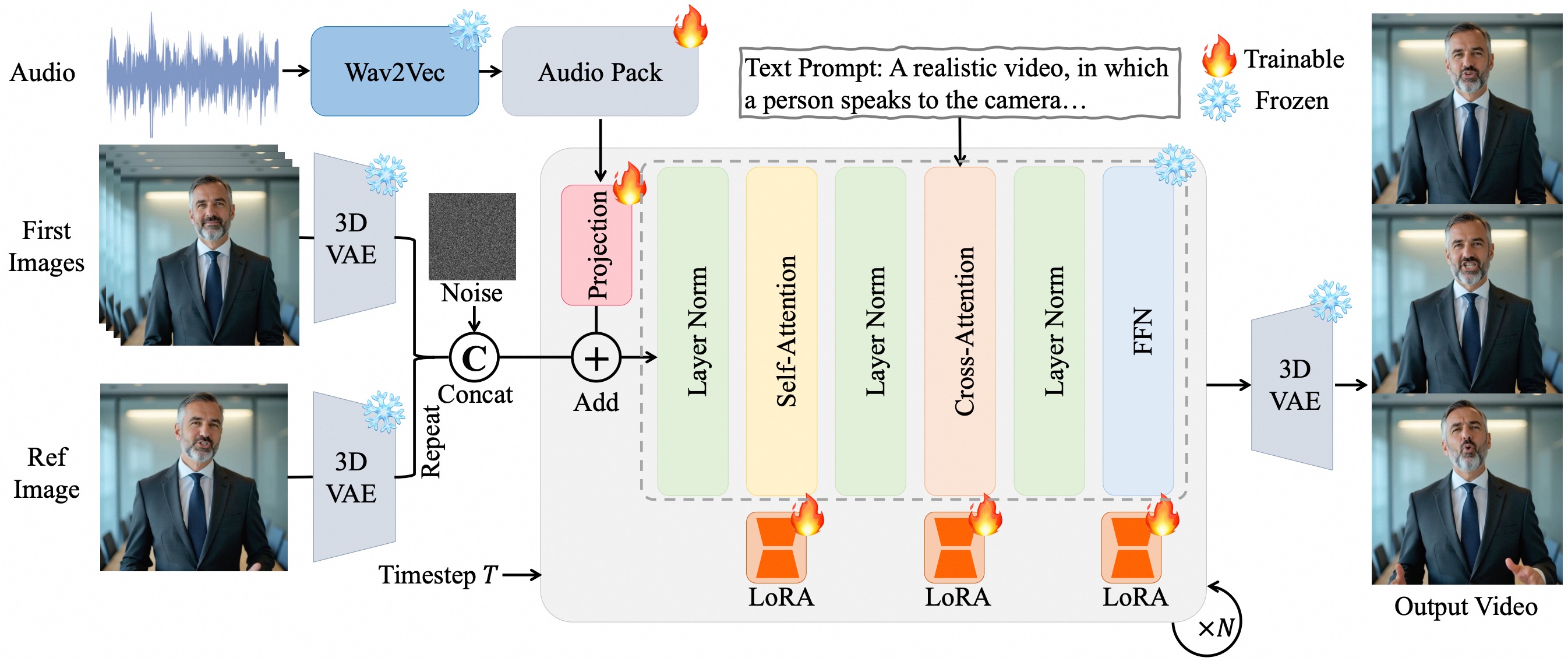
I. 主要な技術原理
ピクセルレベルのマルチレイヤー音声埋め込み
- Wav2Vec2を使用して音声特徴を抽出し、Audio Packモジュールを通じて音声特徴を動画の潜在空間にピクセル単位でアライメントし、拡散モデル(DiT)の複数の時間レイヤーに音声情報を埋め込みます。
- 利点: 従来のモデルよりも高精度な同期を実現し、フレームレベルのリップシンク(気息音による微細な表情など)とフルボディモーションの協調(肩の動きやジェスチャーのリズムなど)を達成します。
LoRA微調整戦略
- Transformerの注意層とフィードフォワードネットワーク層に低ランク適応行列(LoRA)を挿入し、ベースモデルの能力を維持しながら追加パラメータのみを調整します。
- 効果: オーバーフィッティングを防ぎ、音声-動画アライメントの安定性を向上させ、テキストプロンプトを通じた詳細な制御(ジェスチャーの振幅や感情表現など)をサポートします。
長時間動画生成メカニズム
- 参照画像の潜在エンコーディングをアイデンティティアンカーとして組み込み、フレームオーバーラップ戦略と段階的生成アルゴリズムを組み合わせて、長時間動画における色の劣化やアイデンティティの不一致の問題を軽減します。
II. 主要な特徴とイノベーション
フルボディモーション生成
- 従来の「頭部のみの動き」という制限を超え、自然で協調的な身体動作(挨拶、乾杯、ダンスなど)を生成します。
マルチモーダル制御機能
- テキストプロンプトによる制御: アクション(「乾杯して祝う」など)、背景(「星空のライブスタジオ」など)、感情(「喜び/怒り」など)を説明文を通じて正確に調整します。
- オブジェクトとのインタラクション: 仮想人物がシーン内のオブジェクトとインタラクションする機能(商品デモンストレーションなど)をサポートし、eコマースマーケティングにおけるリアリズムを向上させます。
多言語対応と長時間動画
- 中国語、英語、日本語を含む31言語のリップシンク適応をサポートし、10秒以上の一貫性のある動画生成が可能です(高VRAMデバイスが必要)。
III. 豊富な動画デモンストレーション
OmniAvatarの公式ウェブサイトでは、様々なシナリオと制御機能をカバーする多数の実際のデモンストレーションを提供しています。以下は選択された動画です:
1. スピーカーのフルボディモーションと表情
2. 多様なアクションと感情表現
3. 人物-オブジェクトインタラクション
4. 背景とシーン制御
5. 感情表現
6. ポッドキャストと歌唱シナリオ
より多くのデモンストレーションについては、OmniAvatar公式ウェブサイトをご覧ください
IV. オープンソースとエコシステム
- オープンソースリポジトリ: GitHub - OmniAvatar
- モデルダウンロード: HuggingFace - OmniAvatar-14B
- 研究論文: arXiv:2506.18866
コンテンツはOmniAvatar公式ウェブサイト、GitHub、および関連オープンソース資料を参照しています。
コメント
GitHubでサインインしてディスカッションに参加しましょう。