XVerse公開: 複数の被写体のアイデンティティと意味的属性を制御できる高一貫性画像生成モデル
ByteDanceがXVerseモデルをオープンソース化。複数の被写体のアイデンティティと意味的属性(ポーズ、スタイル、照明など)を正確に独立制御することを可能にし、AI画像生成のパーソナライゼーションと複雑なシーン生成能力を向上
XVerseは、ByteDanceのCreative AIチームが2025年にオープンソース化した制御可能な複数被写体画像生成モデルです。AI生成画像における複数のオブジェクト(人物、動物、物体など)の正確な独立制御という課題の解決に焦点を当てています。このモデルは、画像内の複数の被写体のアイデンティティ、ポーズ、スタイル、照明などの属性を細かく干渉なく調整することをサポートし、パーソナライズされた複雑なシーンの生成能力を大幅に向上させています。

I. 主要な機能と革新点
- 独立した複数被写体制御: 複数の被写体のアイデンティティ、アクション、スタイルを同時に正確に制御し、従来の手法で見られる「属性の絡み合い」問題を回避します。
- 高い忠実度と詳細の保持: VAE画像特徴エンコーディングを通じて髪の毛や質感などの詳細を保持し、アーティファクトや歪みを低減します。
- 柔軟な意味的属性編集: 照明やアーティスティックスタイルなどの非アイデンティティ属性の柔軟な調整をサポートし、シーン遷移時に被写体の特徴を維持します。
- 高い一貫性と安定性: 革新的なテキストフロー変調メカニズムとデュアル正則化(領域保護損失、テキスト-画像注意損失)により、生成の安定性と一貫性を確保します。
II. 技術原理の概要
1. テキストフロー変調メカニズム(T-Mod Adapter)
- 参照画像をテキスト埋め込みオフセットに変換し、階層的制御信号(グローバル共有+ブロック変調)を通じて複数の被写体の正確な独立制御を実現します。
- T-Mod adapterはCLIP画像特徴とテキストプロンプトを統合し、特徴の混乱を避けるためのクロス変調信号を生成します。
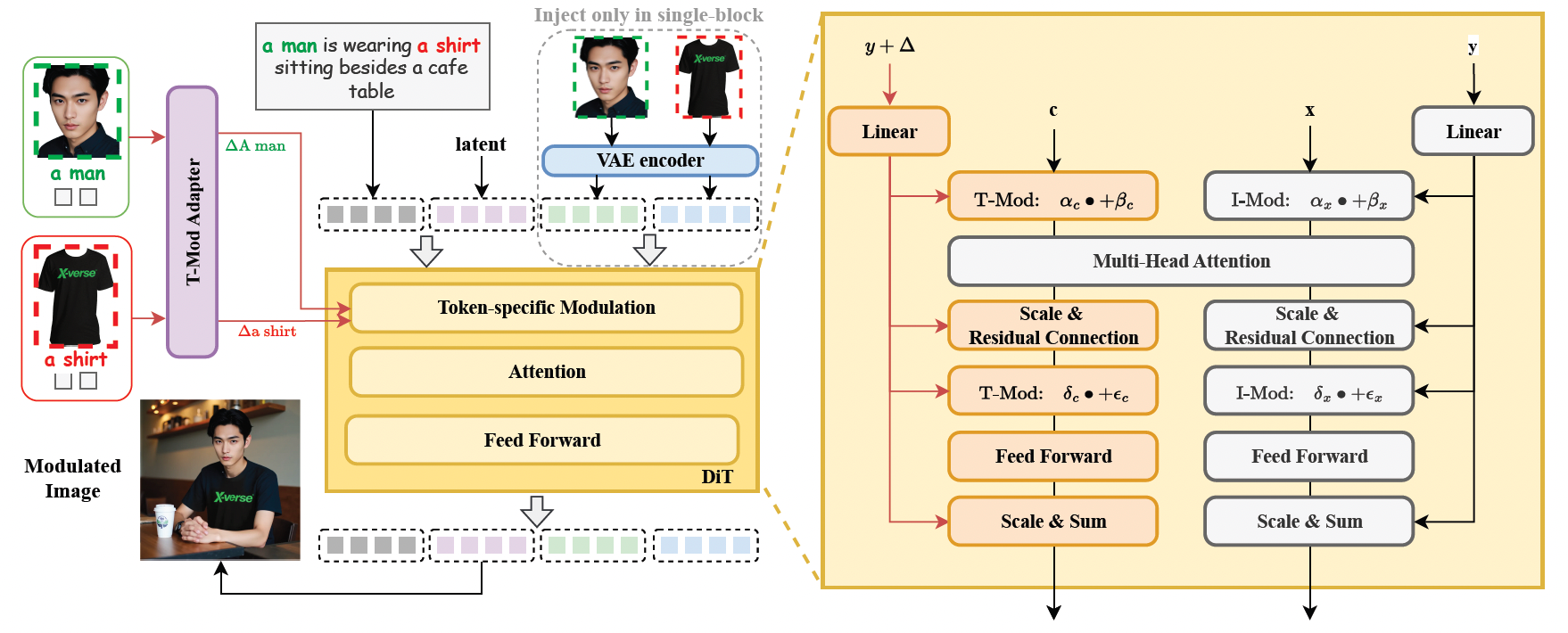
2. VAE画像特徴エンコーディングモジュール
- FLUX構造にVAEエンコード特徴を導入し、詳細の保持を強化して、生成された画像をよりリアルで自然なものにします。
3. デュアル正則化メカニズム
- 領域保護損失: 変調から特定の領域をランダムに保護し、対象外のオブジェクトが影響を受けないようにします。
- テキスト-画像注意損失: 注意の配分を最適化し、意味的アライメントの精度を向上させます。
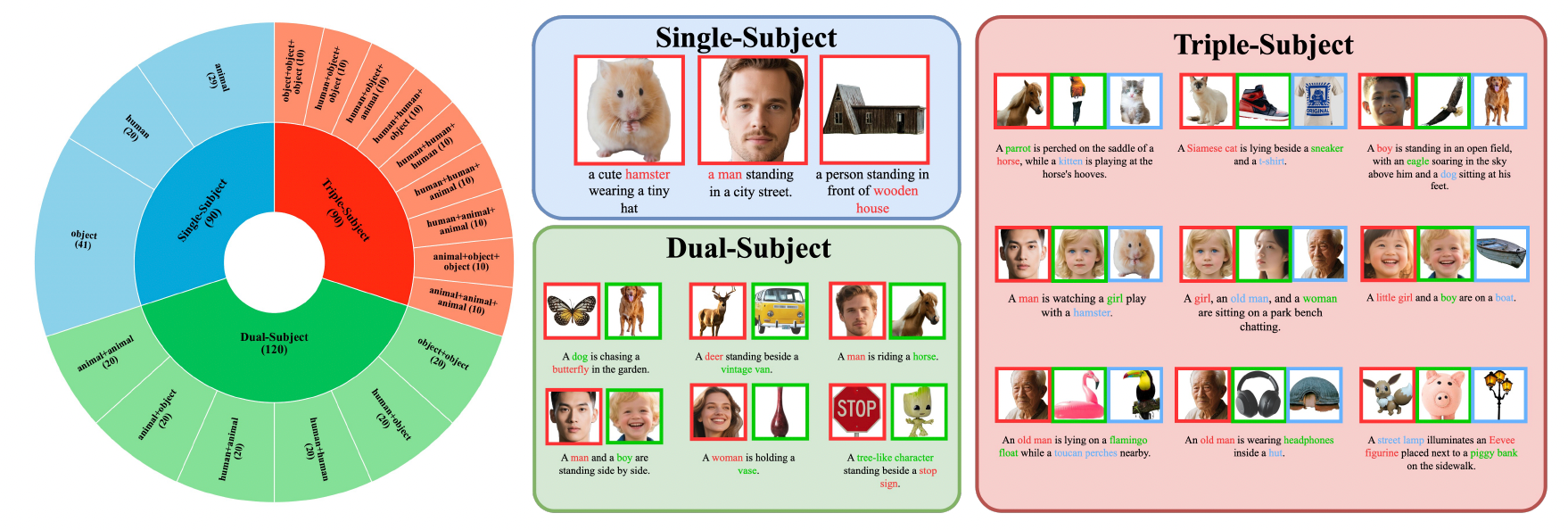
III. 訓練データと評価ベンチマーク
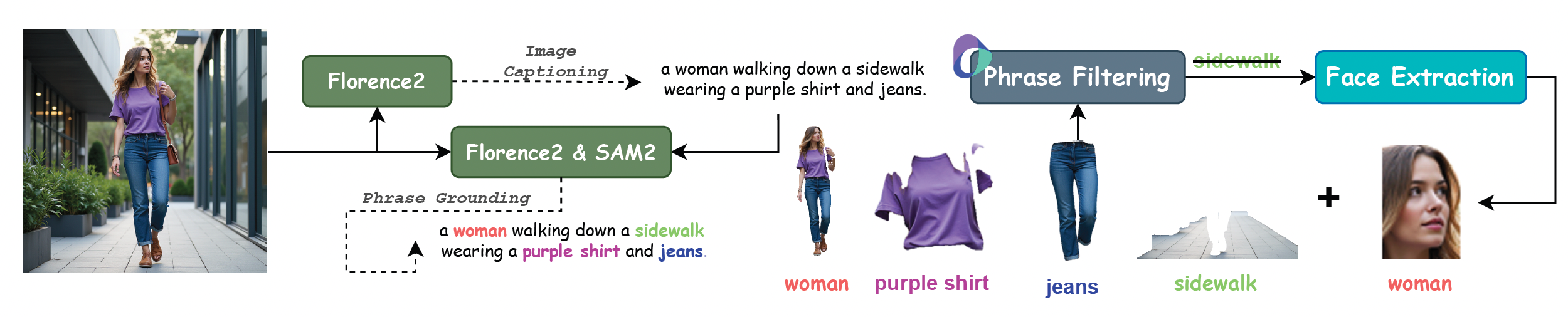
XVerseは、20種類の人物、74種類のアイテム、45種類の動物をカバーする高品質な複数被写体制御データセットを使用し、数百万の高い美的品質を持つ画像を合成しています。
モデルのパフォーマンスは、XVerseBenchベンチマークにおいて類似手法を大きく上回り、単一、二重、三重の被写体を含む様々な制御シナリオをサポートしています。
| メトリック | 意味 | | | | | DPGスコア | 編集能力 | | 顔IDの類似度 | 人物アイデンティティの一貫性 | | DINOv2類似度 | オブジェクト特徴の一貫性 | | 美的スコア | 画像の美的品質 |
IV. 実験結果とケーススタディ
1. 単一被写体のアイデンティティと属性の正確な制御
XVerseは、多様なシナリオにおいて被写体のアイデンティティの一貫性を維持しながら、ポーズ、衣装、環境などの属性を柔軟に調整します。





2. 複数被写体の一貫性と独立制御
XVerseは、同一画像内で複数の被写体のアイデンティティと属性を独立して制御しながら、自然な相互作用とシーンの一貫性を維持します。





3. 柔軟な意味的属性制御
XVerseは、照明、ポーズ、スタイルなどの意味的属性の詳細な調整をサポートし、多様なクリエイティブニーズに対応します。

V. オープンソースと関連リソース
- プロジェクトホームページ: https://bytedance.github.io/XVerse/
- GitHubリポジトリ: https://github.com/bytedance/XVerse
- モデルダウンロード: https://huggingface.co/ByteDance/XVerse
- 技術論文: https://arxiv.org/abs/2506.21416
コンテンツはXVerse公式ホームページ、GitHub、および関連オープンソース資料を参照しています。
コメント
GitHubでサインインしてディスカッションに参加しましょう。