Sesame、CSM音声モデルで自然な対話を実現
ComfyUI Wikinews
SesameがデュアルTransformerアーキテクチャの会話型音声モデルCSMを公開、リアルタイム音声インタラクションとオープンソースコアを提供
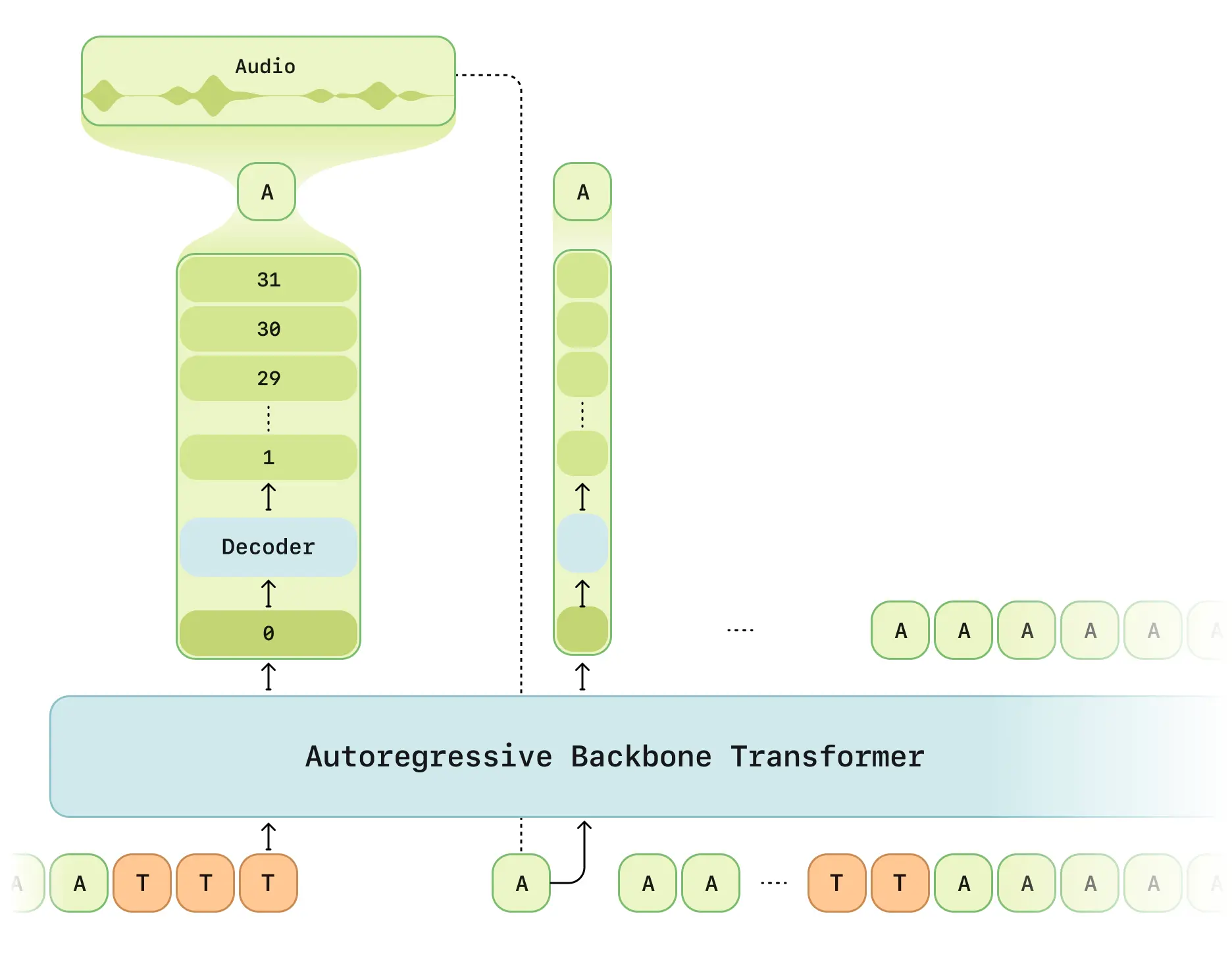
Sesame研究所が発表した会話型音声モデルCSMが公式デモで画期的な対話能力を披露しました。デュアルTransformerアーキテクチャにより、人間に近い自然な音声対話を実現しています。
技術アーキテクチャ
CSMのコア設計要素:
- 二段階処理: マルチモーダルバックボーン(テキスト/音声処理)+オーディオデコーダ
- RVQトークナイザ: Mimi分離型量子化エンコーダ採用(12.5Hzフレームレート)
- 遅延最適化モード: 従来のRVQ生成の時間遅延問題を解決
- 計算分散方式: 1/16フレームサンプリングで学習効率向上
- Llama構造: LLaMAモデルベースの改良バックボーン
主要機能
- 文脈認識: 最大2分間の対話記憶(2048トークン)
- 感情認識: 6層感情分類器による対話感情分析
- リアルタイム処理: エンドツーエンド遅延 < 500ms(平均380ms)
- 複数話者対応: 単一生成で複数話者の音声処理
技術仕様
| 項目 | 内容 | |
|
-| | 学習データ | 100万時間英語対話音声 | | モデル規模 | 8Bバックボーン+300Mデコーダ | | シーケンス長 | 2048トークン(約2分) | | 対応デバイス | RTX 4090以上 |
オープンソース状況
GitHubリポジトリ提供内容:
- 完全なアーキテクチャ白書
- REST API呼び出し例
- 音声前処理ツールキット
- モデル量子化デプロイガイド
⚠️ 利用制限:
- コア学習コード未公開(2025年Q3予定)
- APIキー申請が必要
- 英語環境優先対応
評価結果
公式テストレポートより:
- 自然性評価: CMOSスコアが実音声と同等
- 文脈理解: 状況認識精度37%向上
- 発音一貫性: 95%の発音安定性維持
- 遅延性能: 初フレーム生成時間68%改善
コメント
GitHubでサインインしてディスカッションに参加しましょう。