DeepSeek、Janus-Pro-7Bをオープンソース化:マルチモーダルAIモデル
ComfyUI Wikinews
DeepSeek がマルチモーダルAIモデル Janus-Pro-7B をオープンソース化。画像理解と生成が可能。ComfyUIでの使い方を解説。
中国のAI企業DeepSeekは、今日未明に次世代マルチモーダルモデルJanus-Pro-7Bのオープンソース化を発表しました。このモデルは、画像生成や視覚的質問応答などのタスクにおいて、OpenAIのDALL-E 3やStable Diffusion 3を上回り、「理解-生成デュアルパス」アーキテクチャとミニマリストなデプロイメントソリューションにより、AIコミュニティにセンセーションを巻き起こしています。公式発表を確認
性能:小型モデルが業界の巨人を凌駕

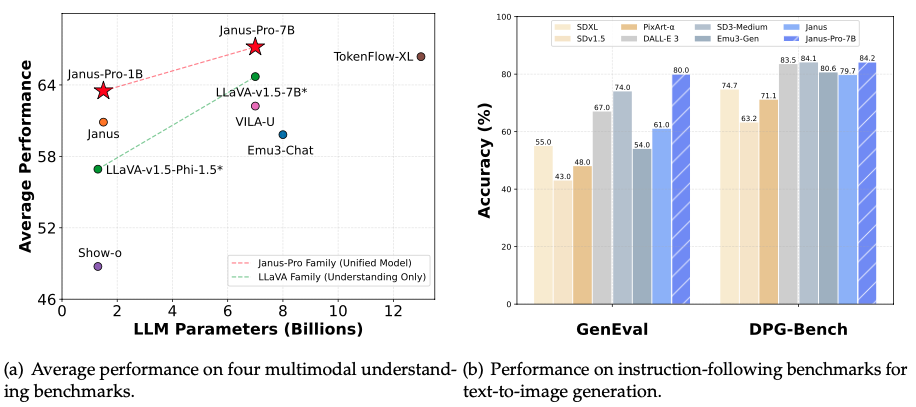
70億パラメータ(GPT-4の約1/25)しか持たないにもかかわらず、Janus-Pro-7Bは主要なテストで競合を上回りました:
- テキストから画像への品質:GenEvalテストで80%の精度を達成し、DALL-E 3(67%)とStable Diffusion 3(74%)を上回りました
- 複雑な指示の理解:DPG-Benchテストで84.19%の精度を記録し、「青い湖を抱えた雪山」などの複雑なシーンを正確に生成しました
- マルチモーダル質問応答:視覚的質問応答の精度がGPT-4Vを上回り、MMBenchテストスコアは79.2で、専門的な分析モデルに近い結果を示しました
技術的ブレークスルー:「Janus」のようなデュアルパス協調
従来のモデルは、理解と生成の両方に同じ視覚エンコーダを使用していましたが、これはシェフにメニューをデザインさせながら同時に料理をさせるようなものです。Janus-Pro-7Bは、視覚処理を2つの独立したパスに分割する革新的なアプローチを採用しています:
- 理解パス:SigLIP-L視覚エンコーダを使用して、画像から核心情報を迅速に抽出します(例:「これはソファの上のオレンジ色の猫です」)
- 生成パス:VQトークナイザーを介して画像をピクセル配列に分解し、レゴブロックを組み立てるように詳細を描画します(例:毛並みの質感、照明効果) この「分割統治」設計により、従来のモデルにおける役割の衝突を解決し、7200万枚の合成画像と実データを混合してトレーニングすることで生成の安定性を向上させました。
オープンソースと商用利用
- 商用利用無料:MITライセンスの下でリリースされ、無制限の商用利用が可能です
- ミニマリストなデプロイメント:1.5B(16GB VRAM必要)と7B(24GB VRAM必要)のバージョンを提供し、標準的なGPUで実行可能です
- ワンクリック生成:公式のGradioインターフェースを提供;
generate_image(prompt="夕日の雪山", num_images=4)を入力して画像をバッチ生成できます
公式リソース:
- GitHubリポジトリ:https://github.com/deepseek-ai/Janus
- モデルダウンロード:HuggingFace Janus-Pro-7B
応用シナリオ:アートからプライバシー保護まで
- クリエイティブ産業:デザイナーがテキストを入力してポスターのプロトタイプを生成;ゲーム開発者がシーンアセットを迅速に構築
- 教育ツール:教師が地理の授業で火山噴火の動的イラストを生成
- 企業のプライバシー:病院や銀行がローカルにデプロイし、患者記録や財務データをクラウドにアップロードする必要がありません
- 文化の普及:世界的なランドマーク(例:杭州の西湖)を認識し、文化的シンボルを持つ画像を生成
DeepSeek Janus公式リソース**
- コードリポジトリ:GitHub Janus-Pro-7B
- モデルダウンロード:HuggingFaceモデルページ
コメント
GitHubでサインインしてディスカッションに参加しましょう。