OmniAvatar:高效音频驱动的虚拟人视频生成模型发布
ComfyUI Wikinews
OmniAvatar模型正式开源,支持音频驱动的全身虚拟人视频生成,具备自然动作与丰富表情,适用于播客、互动、动态场景等多种应用。
OmniAvatar 是由浙江大学与阿里巴巴集团联合研发的开源项目(2025年6月发布),是一种基于音频驱动的全身数字人视频生成模型。它通过单张参考图像、一段音频和文本提示,生成自然流畅的虚拟人视频,支持精准口型同步、全身动作控制及多场景交互,被认为是数字人技术的重要进展。
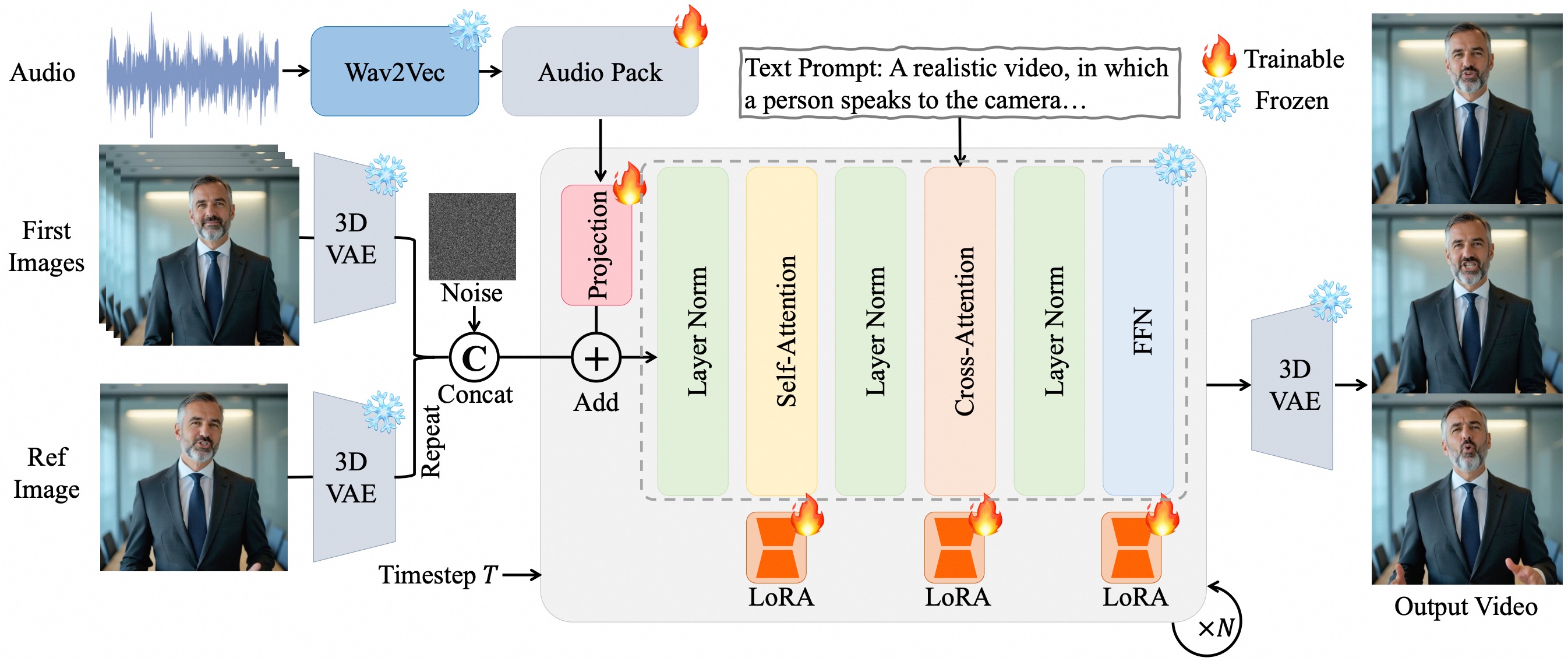
一、核心技术原理
像素级多层次音频嵌入
- 采用 Wav2Vec2 提取音频特征,通过 Audio Pack模块将声纹特征逐像素对齐到视频潜在空间,在扩散模型(DiT)的多个时序层中嵌入音频信息。
- 优势:实现帧级唇形同步(如气声词触发微妙表情)和全身动作协调(如肩部摆动、手势节奏),同步精度高于主流模型。
LoRA微调训练策略
- 在Transformer的注意力层和前馈网络层插入低秩自适应矩阵(LoRA),仅微调新增参数,兼顾训练效率与基础模型能力保留。
- 效果:避免过拟合,提升音频-视频对齐稳定性,同时支持文本提示的精细化控制(如手势幅度、情绪表达)。
长视频生成机制
- 引入参考图像潜在编码作为身份锚点,结合帧重叠策略和递进式生成算法,缓解长视频中的颜色漂移、身份不一致问题。
二、核心功能与创新
全身动作生成
- 突破传统"只有头能动"的限制,生成自然协调的肢体动作(如挥手、举杯、舞蹈)。
多模态控制能力
- 文本提示控制:通过描述精准调整动作(如"举杯庆祝")、背景(如"星空直播间")、情绪(如"喜悦/愤怒")。
- 物体交互:支持虚拟人与场景物体互动(如手持商品讲解),增强电商营销的真实感。
多语言与长视频支持
- 支持中英日等31种语言的嘴型适配,可生成10秒以上连贯视频(需高显存设备)。
三、丰富视频演示
OmniAvatar 官方主页提供了大量真实演示,涵盖多种场景和控制能力。以下为部分精选视频:
1. 说话人全身动作与表情
2. 多样化动作与情感表达
3. 人物与物体交互
4. 背景与场景控制
5. 情感表达
6. 播客与歌唱场景
更多演示请访问 OmniAvatar 官方主页
四、开源与生态
- 开源地址:GitHub - OmniAvatar
- 模型下载:HuggingFace - OmniAvatar-14B
- 论文地址:arXiv:2506.18866
本文内容参考自 OmniAvatar 官方网站、GitHub 及相关开源资料。
评论
使用 GitHub 登录后即可参与讨论。