XVerse发布:多主体身份与语义属性可控的高一致性图像生成模型
ComfyUI Wikinews
字节跳动开源XVerse模型,实现多主体身份与语义属性(如姿态、风格、光照等)的高精度独立控制,提升AI图像生成的个性化与复杂场景表现力。
XVerse是字节跳动智能创作团队于2025年开源的多主体可控图像生成模型,专注于解决AI生成图像中多个对象(如人物、动物、物体)的独立精准控制难题。该模型支持对图像中多个主体的身份、姿势、风格、光照等属性进行细粒度、互不干扰的调节,显著提升了个性化和复杂场景的生成能力。

一、核心能力与创新点
- 多主体独立控制:可同时精准控制图像中多个主体的身份、动作、风格等,避免传统方法中常见的"属性纠缠"问题。
- 高保真与细节还原:通过VAE编码图像特征模块,保留发丝、材质等细节,减少伪影和失真。
- 灵活语义属性编辑:支持对光照、艺术风格等非身份属性的灵活调整,场景变换不影响主体特征。
- 高一致性与稳定性:创新的文本流调制机制和双重正则化(区域保护损失、文本-图像注意力损失)保障生成结果的稳定性和一致性。
二、技术原理概览
1. 文本流调制机制(T-Mod Adapter)
- 将参考图像转换为文本嵌入偏移量,通过分层控制信号(全局共享+分块调节)实现多主体的独立精准控制。
- T-Mod适配器整合CLIP图像特征与文本提示,生成交叉调制信号,避免特征混淆。
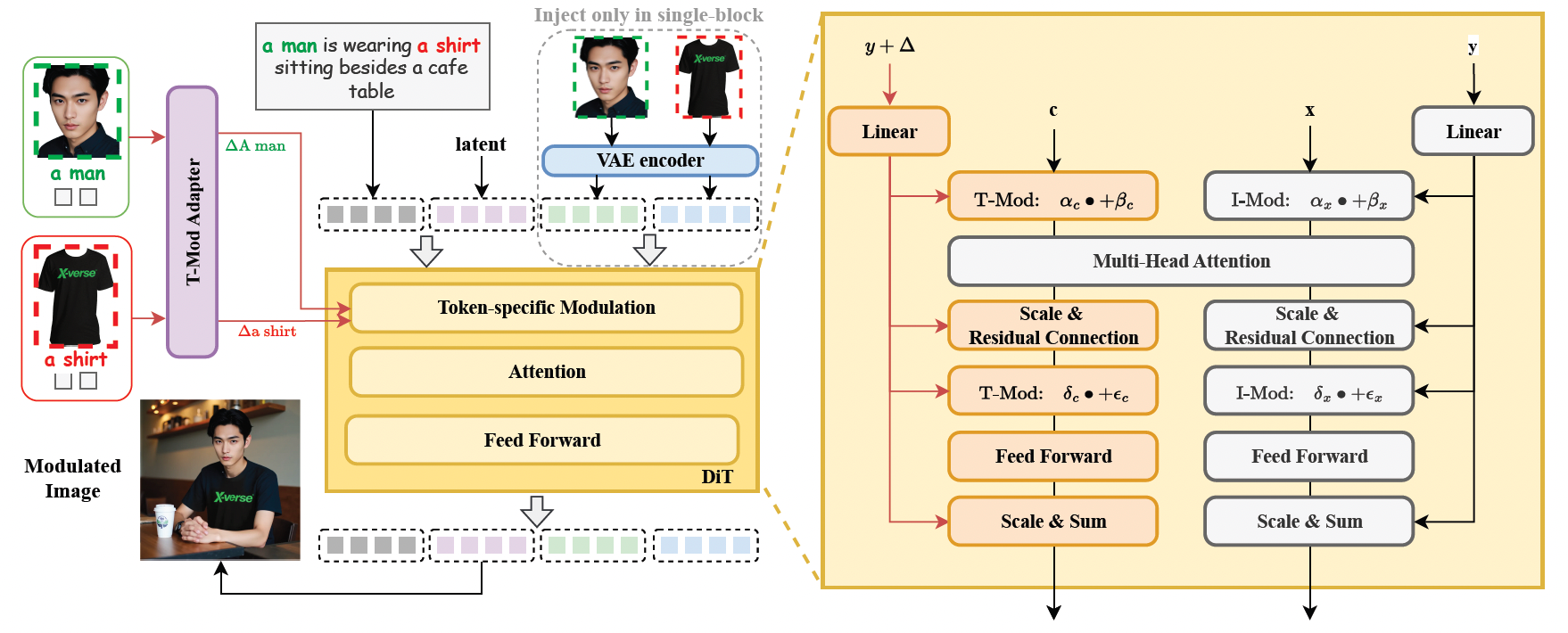
2. VAE编码图像特征模块
- 在FLUX结构中引入VAE编码特征,增强细节还原能力,使生成图像更真实自然。
3. 双重正则化机制
- 区域保护损失:随机保留部分区域不受调制,确保非目标对象不被干扰。
- 文本-图像注意力损失:优化注意力分配,提升语义对齐精度。
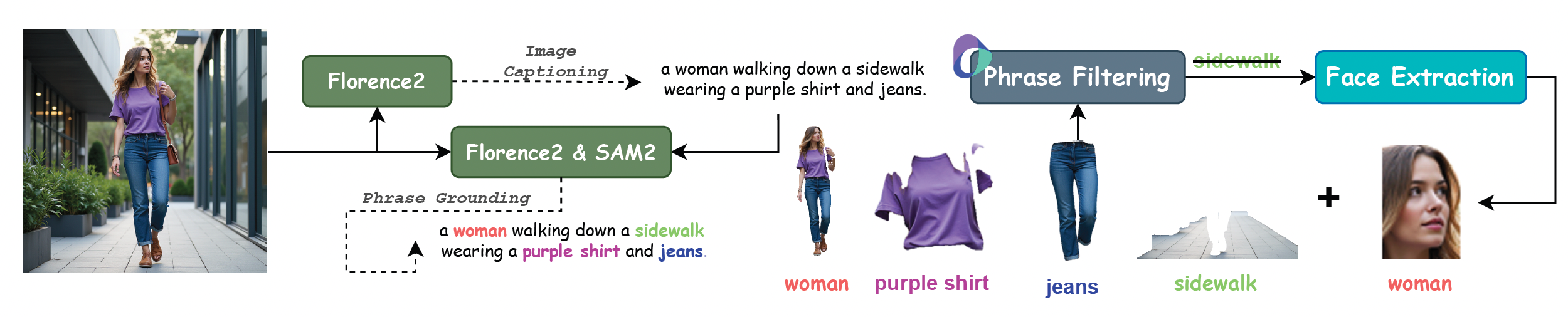
三、训练数据与评测基准
XVerse采用高质量多主体控制数据集,涵盖20类人物、74类物品、45类动物,合成百万级高美学质量图像。
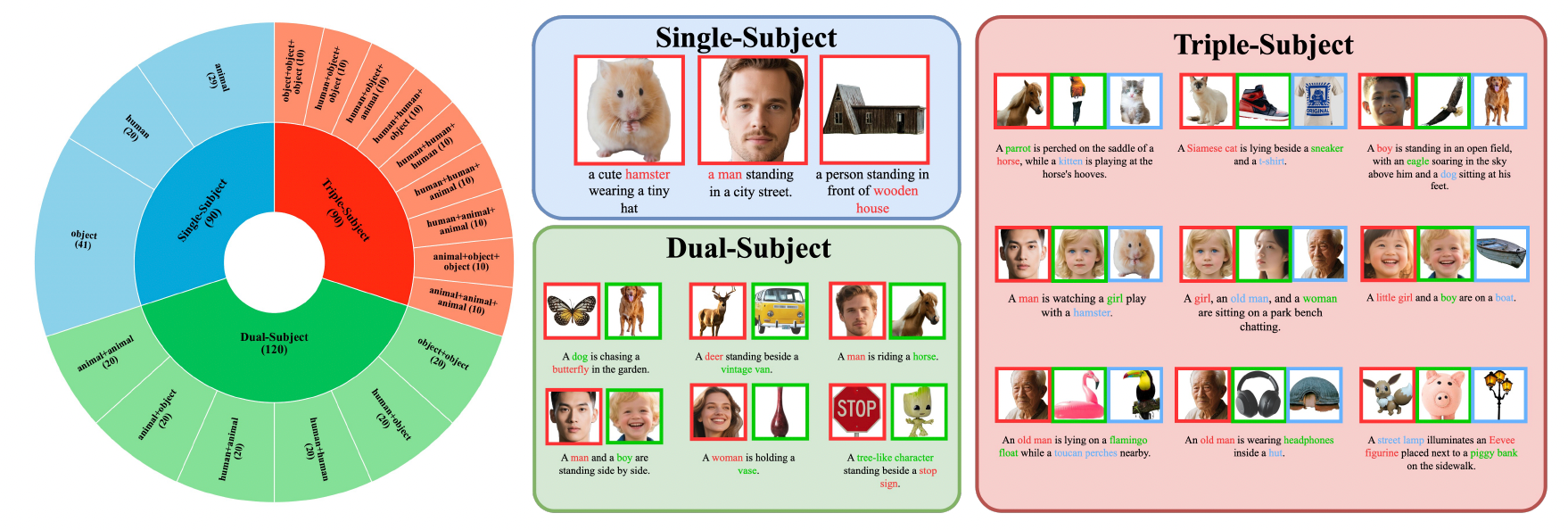
模型性能在XVerseBench基准上显著优于同类方法,支持单主体、双主体、三主体等多种控制场景。
| 评测指标 | 含义 | | | | | DPG Score | 编辑能力 | | Face ID Similarity | 人物身份一致性 | | DINOv2 Similarity | 物体特征一致性 | | Aesthetic Score | 图像美学质量 |
四、实验结果与案例展示
1. 单主体身份与属性精准控制
XVerse可在多样场景下保持主体身份一致性,并灵活调整姿态、服饰、环境等属性。





2. 多主体一致性与独立控制
XVerse可在同一图像中实现多主体身份和属性的独立控制,保持自然交互和场景一致性。





3. 语义属性灵活控制
XVerse支持对光照、姿态、风格等语义属性的细致调节,满足多样创意需求。

五、开源与相关资源
- 项目主页:https://bytedance.github.io/XVerse/
- GitHub仓库:https://github.com/bytedance/XVerse
- 模型下载:https://huggingface.co/ByteDance/XVerse
- 技术论文:https://arxiv.org/abs/2506.21416
本文内容参考自 XVerse官方主页、GitHub 及相关开源资料。
评论
使用 GitHub 登录后即可参与讨论。