Insert Anything: 开源图像无缝插入编辑框架
Insert Anything是一个开源的统一框架,能够将参考图像中的人物、物体和服装等元素无缝插入到目标场景中,支持多种场景应用

Insert Anything是一个全新开源的图像编辑框架,由浙江大学、哈佛大学和南洋理工大学的研究团队(Wensong Song、Hong Jiang、Zongxing Yang、Ruijie Quan、Yi Yang)共同开发。该框架能够在用户指定的控制指导下,将参考图像中的对象无缝地集成到目标场景中。
这个统一的图像插入框架支持多种实际应用场景,包括艺术创作、真实人脸替换、电影场景合成、虚拟服装试穿、配饰定制和数字道具替换,充分展示了其在各种图像编辑任务中的多功能性和有效性。
主要功能与特点
- 统一的插入框架:不需要为不同任务训练单独的模型,一个模型支持多种插入场景
- 多种控制方式:支持基于掩码和文本的编辑指导
- 保留身份特征:能够准确捕捉身份特征和精细细节,同时允许在风格、颜色和纹理上进行多样化的局部调整
- 上下文编辑机制:将参考图像视为上下文信息,使用两种提示策略使插入元素与目标场景和谐融合
- 低显存版本支持:提供基于Nunchaku的10GB显存版本,方便普通用户使用
应用效果展示
表情包创作
表情包创作是Insert Anything的一个重要应用场景,以下是一些效果对比图:






商业广告设计
商业广告设计是Insert Anything的另一个重要应用场景,以下是一些效果对比图:






流行文化创作
流行文化创作展示了Insert Anything在创意内容生成方面的潜力:








技术亮点
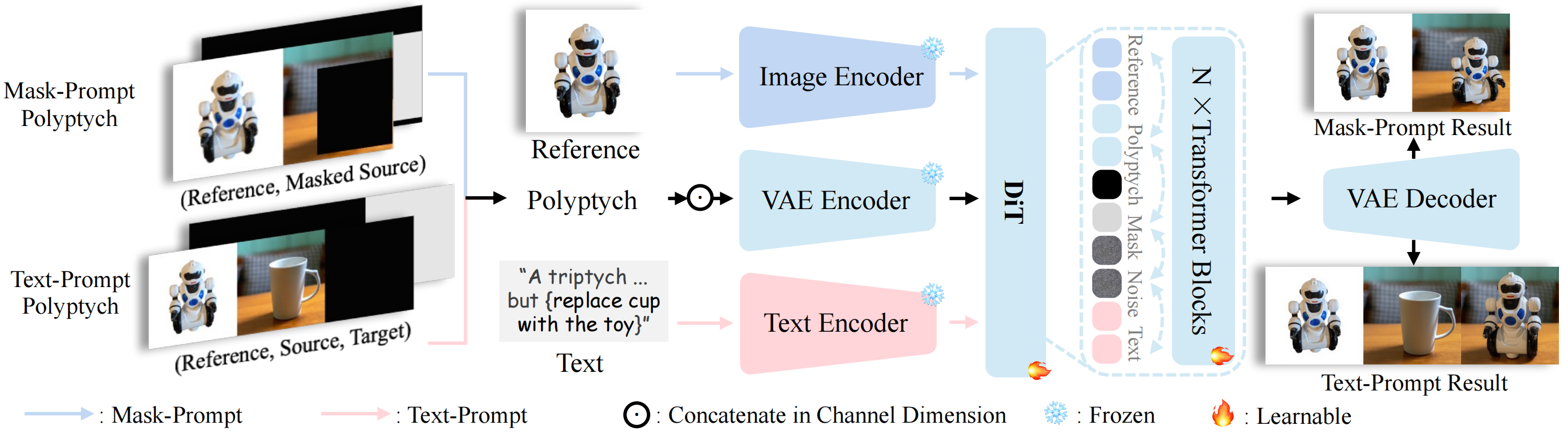
Insert Anything利用Diffusion Transformer (DiT)的多模态注意力机制,同时支持基于掩码和文本的编辑。根据不同类型的提示,该统一框架通过冻结的VAE编码器处理多幅输入图像(参考图像、源图像和遮罩的组合),以保留高频细节,并从图像和文本编码器中提取语义指导。这些嵌入被组合并输入到可学习的DiT变换器块中进行上下文学习,从而能够根据掩码或文本提示实现精确灵活的图像插入。
AnyInsertion数据集


为了训练这一统一框架,研究团队创建了AnyInsertion数据集,该数据集包含约12万对提示-图像对,涵盖多种插入任务,如人物、物体和服装插入。数据集分为基于掩码和基于文本的两种类别,每种类别又进一步细分为配饰、物体和人物子类别。
数据集的图像对来自互联网资源、人物视频和多视角图像。数据集涵盖了多种插入场景:
- 家具和室内装饰
- 日常必需品
- 服装和配饰
- 交通工具
- 人物
开源与使用
Insert Anything项目已在GitHub上开源,任何人都可以自由下载并使用:
- GitHub仓库:song-wensong/insert-anything
- 数据集:WensongSong/AnyInsertion
项目提供了多种使用方式:
- 命令行推理脚本
- Gradio界面
- ComfyUI集成节点
硬件需求
Insert Anything提供两种版本:
- 标准版本:需要26GB或40GB显存
- 轻量版本:基于Nunchaku的优化版本,仅需10GB显存
未来计划
根据官方GitHub仓库的信息,团队计划:
- 发布训练代码
- 在HuggingFace上发布AnyInsertion文本提示数据集
相关链接
这一开源框架的发布,将为创意工作者、设计师和内容创作者提供一个强大的工具,帮助他们实现更加灵活和精确的图像编辑效果。
评论
使用 GitHub 登录后即可参与讨论。