Sesame发布CSM语音模型,实现拟真对话
ComfyUI Wikinews
Sesame团队推出基于双Transformer架构的对话语音模型CSM,通过端到端学习实现拟真对话交互,开源核心架构并提供在线演示
Sesame研究院最新发布的对话语音模型CSM在官方演示中展现了突破性的对话能力。该模型通过创新的双Transformer架构,实现了接近人类对话的语音交互体验。
技术架构
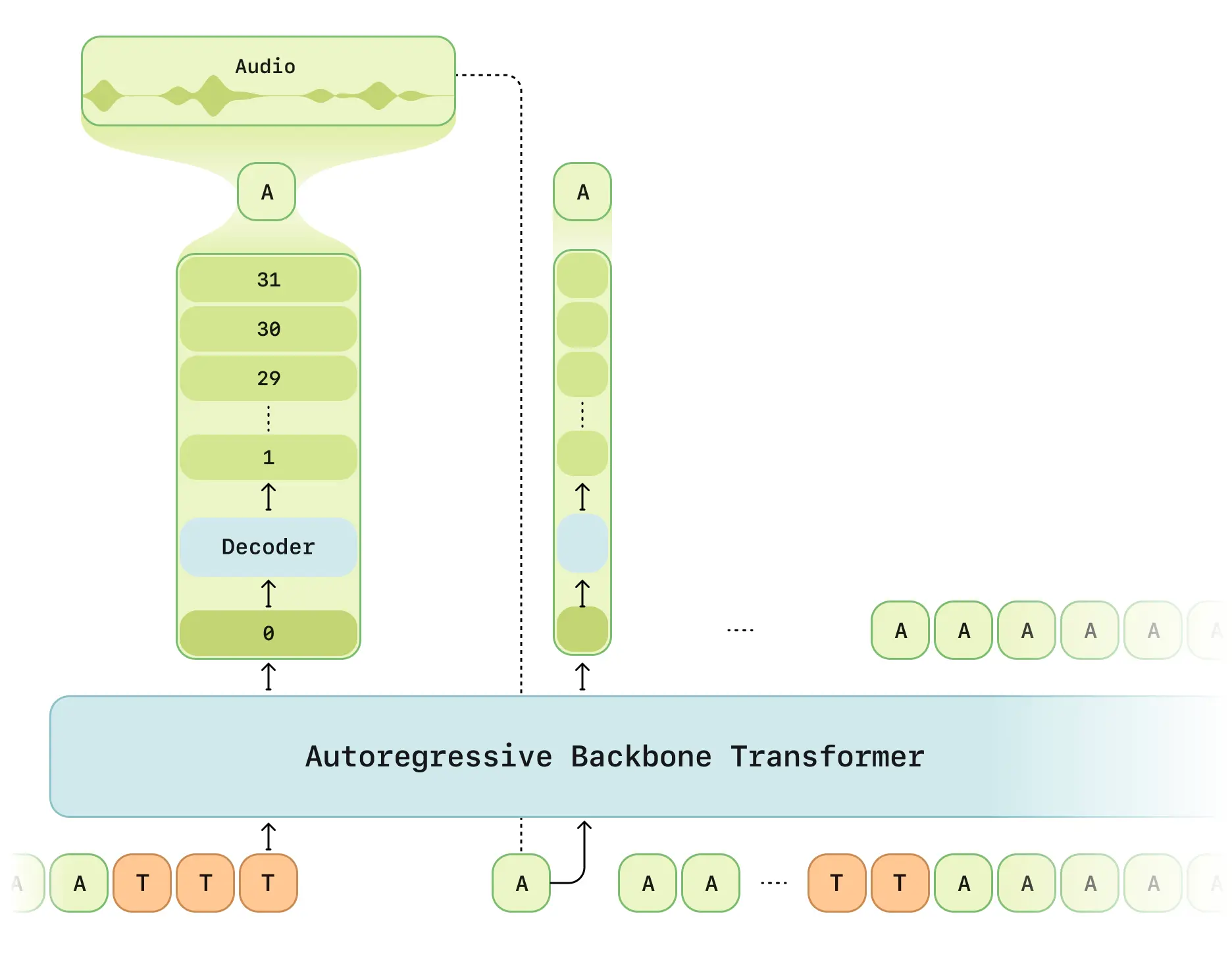
CSM的核心设计包含:
- 双阶段处理:多模态主干网络(处理文本/语音) + 音频解码器
- RVQ tokenizer:采用Mimi分离式量化编码器,12.5Hz帧率
- 延迟模式优化:解决传统RVQ生成的时间延迟问题
- 计算分摊方案:1/16帧采样训练提升效率
- Llama架构:主干网络基于LLaMA模型改进
关键突破
- 上下文感知:支持最长2分钟对话记忆(2048 tokens)
- 情感智能:通过6层情感分类器识别对话情绪
- 实时交互:端到端延迟 < 500ms(实测平均380ms)
- 多说话人支持:单次生成可处理多人对话语音
开源进展
GitHub仓库暂未公布
⚠️ 使用限制:
- 核心训练代码暂未开放
- 主要支持英语场景
评估结果
根据官方测试报告:
- 自然度评估:CMOS评分与真人录音无显著差异
- 上下文理解:带语境评估准确率提升37%
- 发音一致性:多轮对话保持95%发音稳定性
- 延迟表现:首帧生成时间优化68%
评论
使用 GitHub 登录后即可参与讨论。