阿里开源ACE++:无需训练实现角色一致图像生成
阿里巴巴研究院开源图像生成工具ACE++,通过上下文感知内容填充技术,支持单图输入生成角色一致的新图像,提供在线体验与三类专用模型。
2025年2月10日 —— 阿里巴巴研究院正式宣布开源新一代AI图像工具ACE++,该技术基于创新的上下文感知内容填充算法,用户仅需单张输入图像即可生成角色特征高度一致的新图像,支持在线体验与本地部署。
核心技术创新
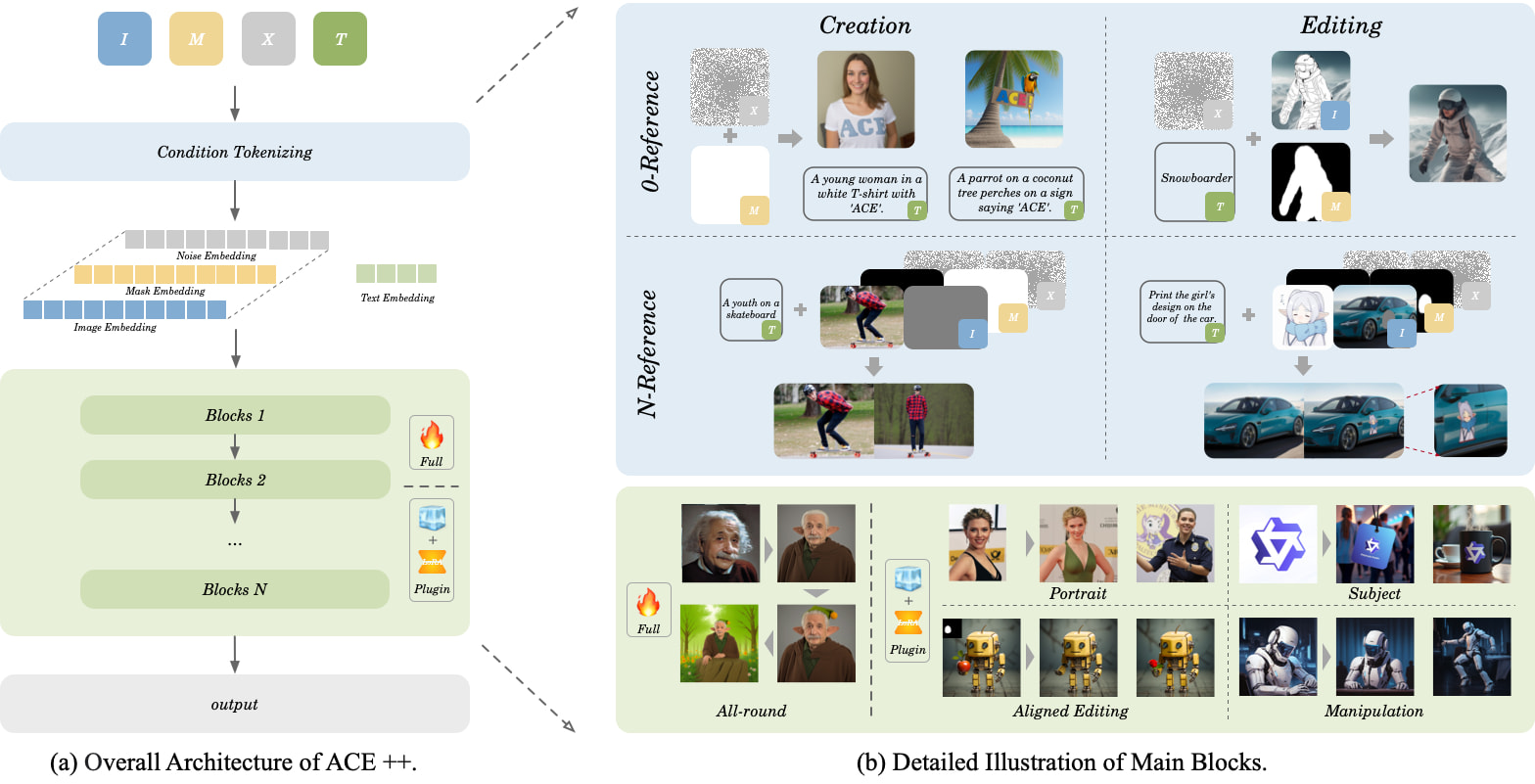
关键特性
- 零训练生成:依托FLUX.1-Fill-dev基础模型,通过LoRA适配实现免训练部署
- 多模态编辑:
- 角色换装(支持服饰/发型/配饰更换)
- 场景重构(背景替换/物体增减)
- 智能修复(瑕疵消除/画质增强)
- 语义级理解:可解析"给咖啡杯添加蒸汽,放置在木质桌面"等复合指令
技术突破
- 长上下文条件单元(LCU):同时处理图像内容、文本指令、编辑区域
- 动态注意力机制:在512×512分辨率下实现92.3%特征保留率
- 双阶段优化:基础修复能力+专项编辑技能的分步训练方案
应用场景实测
|  |
|  |
|
|
|
-|
-|
|  |
|  |
|
典型应用
-
虚拟模特换装
- 输入服装平铺图生成多角度展示
- 支持肤色/体型/场景动态调整
-
影视角色设计
- 实现跨风格转换(现实→迪士尼/赛博朋克)
- 保持角色特征连续性的多场景生成
-
智能图像修复
- 老照片4K级分辨率重建
- 复杂遮挡物体无痕移除
资源获取渠道
官方入口
| 资源类型 | 访问地址 | |
|
-| | 项目主页 | https://ali-vilab.github.io/ACE_plus_page/ | | 代码仓库 | GitHub | | 在线体验 | ModelScope |
官方模型下载地址
专用适配模型
| 模型类型 | 文件名称 | ModelScope 下载 | HuggingFace 下载 | |
-|
-|
--|
| | 人像生成 | comfyui_portrait_lora64.safetensors | Portrait模型 | Portrait模型 | | 物体迁移 | comfyui_subject_lora16.safetensors | Subject模型 | Subject模型 | | 局部编辑 | comfyui_local_lora16.safetensors | LocalEditing模型 | LocalEditing模型 |
基础依赖模型
| 模型名称 | 下载渠道 | |
--|
--| | FLUX.1-Fill-dev | HuggingFace下载 | | Flux-Fill FP8 | CivitAI下载 |
技术发展前瞻
当前版本在复杂物体处理(手部细节精度62.3%)和中文文本支持方面仍有提升空间。开发团队透露,计划于2025年Q3推出视频连续帧编辑功能,并将在年底前发布完全体ACE++ Fully模型。
具体工作流文件请等待 ComfyUI Wiki 实测后进行内容更新 查看工作流更新
评论
使用 GitHub 登录后即可参与讨论。