Команда Tencent Hunyuan открыла исходный код фреймворка MixGRPO для повышения эффективности обучения с выравниванием человеческих предпочтений
Команда Tencent Hunyuan выпустила фреймворк MixGRPO с открытым исходным кодом, первый, который интегрирует скользящее окно смешанного ODE-SDE сэмплинга для GRPO, достигая до 71% ускорения обучения для выравнивания человеческих предпочтений в диффузионных и поточных моделях.
Команда Tencent Hunyuan официально выпустила фреймворк MixGRPO с открытым исходным кодом! Это первый фреймворк, который интегрирует скользящее окно смешанного ODE-SDE сэмплинга для GRPO (Generalized Reward-based Policy Optimization), специально разработанный для повышения эффективности выравнивания человеческих предпочтений в моделях ИИ.
Фреймворк значительно снижает накладные расходы на обучение, сохраняя при этом отличную производительность. Вариант MixGRPO-Flash достигает до 71% ускорения обучения, превосходя предыдущие методы, такие как DanceGRPO.
 Сравнение производительности для различного количества оптимизированных шагов удаления шума. Улучшение производительности DanceGRPO зависит от большего количества оптимизированных шагов, в то время как MixGRPO достигает оптимальной производительности всего за 4 шага
Сравнение производительности для различного количества оптимизированных шагов удаления шума. Улучшение производительности DanceGRPO зависит от большего количества оптимизированных шагов, в то время как MixGRPO достигает оптимальной производительности всего за 4 шага
Особенности фреймворка MixGRPO
Основные технические инновации
- Смешанное сэмплирование со скользящим окном: Первый фреймворк, интегрирующий смешанное ODE-SDE сэмплирование со скользящим окном для GRPO
- Значительное повышение эффективности: MixGRPO-Flash достигает до 71% ускорения обучения
- Поддержка решателей высокого порядка: Поддерживает решатели ODE высокого порядка для дополнительного ускорения
- Универсальная совместимость: Применим как к диффузионным, так и к поточным моделям
 Диаграмма технической архитектуры MixGRPO, иллюстрирующая принцип работы механизма скользящего окна
Диаграмма технической архитектуры MixGRPO, иллюстрирующая принцип работы механизма скользящего окна
Преимущества производительности
- Кардинальное снижение накладных расходов на обучение: Значительно снижает потребление вычислительных ресурсов по сравнению с традиционными методами
- Превосходство над предыдущими методами: Превосходит DanceGRPO и другие предыдущие методы как по эффективности, так и по результативности
- Быстрая сходимость: Достигает потенциала модели всего за несколько итераций
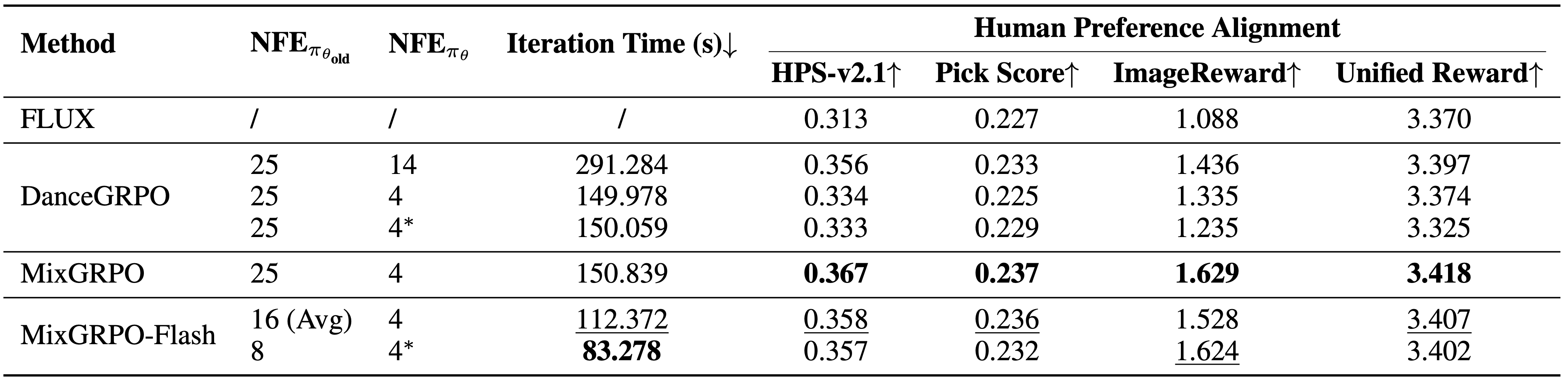 Результаты сравнения накладных расходов и производительности. MixGRPO достигает лучшей производительности по множественным метрикам, в то время как MixGRPO-Flash значительно сокращает время сэмплирования, превосходя DanceGRPO
Результаты сравнения накладных расходов и производительности. MixGRPO достигает лучшей производительности по множественным метрикам, в то время как MixGRPO-Flash значительно сокращает время сэмплирования, превосходя DanceGRPO
Сценарии технического применения
Фреймворк MixGRPO в основном используется для задач выравнивания человеческих предпочтений — важного направления исследований в области ИИ. Благодаря этому фреймворку исследователи могут:
- Более эффективно обучать модели генерации изображений, которые лучше соответствуют человеческим предпочтениям
- Снижать вычислительные затраты на обучение крупномасштабных моделей
- Ускорять экспериментальные итерации, сохраняя качество модели
Эта технология имеет важное значение для улучшения качества контента, генерируемого ИИ, и удовлетворенности пользователей, особенно в приложениях генерации изображений и создания контента.
Экспериментальные результаты
 Результаты качественного сравнения. MixGRPO достигает превосходной производительности как в семантике, так и в эстетике
Результаты качественного сравнения. MixGRPO достигает превосходной производительности как в семантике, так и в эстетике
 Качественное сравнение с различными шагами сэмплирования во время обучения. Производительность MixGRPO не снижается значительно при уменьшении накладных расходов
Качественное сравнение с различными шагами сэмплирования во время обучения. Производительность MixGRPO не снижается значительно при уменьшении накладных расходов
 Визуализация t-SNE для изображений, полученных с различными стратегиями. Применение SDE сэмплирования на ранних стадиях процесса удаления шума приводит к более дискретному распределению данных
Визуализация t-SNE для изображений, полученных с различными стратегиями. Применение SDE сэмплирования на ранних стадиях процесса удаления шума приводит к более дискретному распределению данных
Ресурсы с открытым исходным кодом
Фреймворк MixGRPO теперь полностью открыт. Исследователи и разработчики могут получить доступ к связанным ресурсам через следующие каналы:
Связанные ссылки
- Страница проекта: https://tulvgengenr.github.io/MixGRPO-Project-Page/
- Репозиторий кода: https://github.com/Tencent-Hunyuan/MixGRPO
- Исследовательская статья: https://arxiv.org/abs/2507.21802
Открытие исходного кода MixGRPO обеспечит мощную поддержку инструментов для исследовательского сообщества ИИ, продвигая дальнейшее развитие и применение технологии выравнивания человеческих предпочтений.
Комментарии
Войдите через GitHub, чтобы участвовать в обсуждении.