OmniAvatar: выпуск эффективной модели генерации видео виртуальных людей, управляемой аудио
Модель OmniAvatar теперь с открытым исходным кодом, поддерживает генерацию видео виртуальных людей в полный рост, управляемую аудио, с естественными движениями и богатыми выражениями, подходит для подкастов, взаимодействий, динамических сцен и различных применений.
OmniAvatar - это проект с открытым исходным кодом, совместно разработанный Чжэцзянским университетом и группой Alibaba (выпущен в июне 2025 года). Это модель генерации видео цифровых людей в полный рост, управляемая аудио, которая создает естественные и плавные видео виртуальных людей через одно эталонное изображение, аудиовход и текстовые подсказки. Она поддерживает точную синхронизацию губ, контроль движений всего тела и многосценное взаимодействие, что знаменует значительный прогресс в технологии цифровых людей.
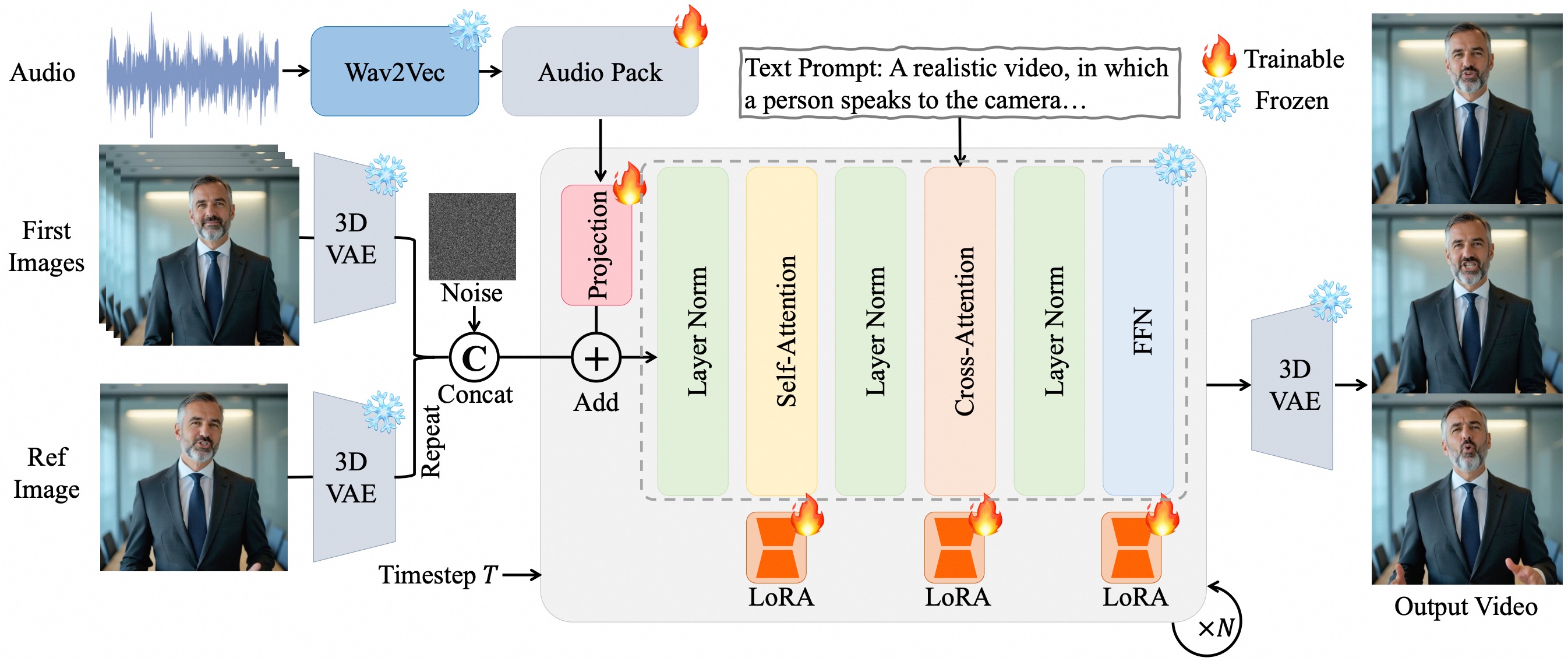
I. Основные технические принципы
Пиксельное многослойное аудиовстраивание
- Использует Wav2Vec2 для извлечения аудио-особенностей, выравнивая голосовые характеристики в скрытое пространство видео пиксель за пикселем через модуль Audio Pack, встраивая аудиоинформацию на нескольких временных слоях в диффузионной модели (DiT).
- Преимущества: Достигает синхронизации губ на уровне кадров (таких как тонкие выражения, вызванные придыхательными словами) и координации движений всего тела (как движения плеч и ритмы жестов), с более высокой точностью синхронизации, чем основные модели.
Стратегия тонкой настройки LoRA
- Вставляет матрицы низкоранговой адаптации (LoRA) в слои внимания Transformer и слои прямой сети, тонко настраивая только дополнительные параметры, сохраняя при этом возможности базовой модели.
- Эффекты: Предотвращает переобучение, улучшает стабильность аудио-видео выравнивания и поддерживает детальный контроль через текстовые подсказки (такие как амплитуда жестов и эмоциональное выражение).
Механизм генерации длинных видео
- Включает скрытое кодирование эталонного изображения как якоря идентичности, в сочетании со стратегией перекрытия кадров и прогрессивными алгоритмами генерации для смягчения проблем дрейфа цвета и несогласованности идентичности в длинных видео.
II. Основные особенности и инновации
Генерация движений всего тела
- Прорывает традиционное ограничение "движения только головы", генерируя естественные и скоординированные движения тела (такие как махание, тост, танцы).
Возможности многомодального контроля
- Контроль текстовых подсказок: Точная настройка действий (как "праздничный тост"), фонов (как "звездная живая студия") и эмоций (как "радость/гнев") через описания.
- Взаимодействие с объектами: Поддерживает взаимодействие виртуальных людей с объектами сцены (как демонстрации продуктов), улучшая реализм в электронной коммерции и маркетинге.
Поддержка многоязычности и длинных видео
- Поддерживает адаптацию синхронизации губ для 31 языка, включая китайский, английский и японский, способна генерировать связные видео более 10 секунд (требует устройства с высоким VRAM).
III. Богатые видео-демонстрации
Официальный веб-сайт OmniAvatar предоставляет многочисленные реальные демонстрации, охватывающие различные сценарии и возможности контроля. Вот избранные видео:
1. Движения и выражения говорящего в полный рост
2. Разнообразные действия и эмоциональные выражения
3. Взаимодействие человека с объектами
4. Контроль фона и сцены
5. Эмоциональное выражение
6. Сценарии подкастов и пения
Для большего количества демонстраций посетите Официальный веб-сайт OmniAvatar
IV. Открытый исходный код и экосистема
- Репозиторий с открытым исходным кодом: GitHub - OmniAvatar
- Загрузка модели: HuggingFace - OmniAvatar-14B
- Исследовательская статья: arXiv:2506.18866
Контент взят с Официального веб-сайта OmniAvatar, GitHub и связанных материалов с открытым исходным кодом.
Комментарии
Войдите через GitHub, чтобы участвовать в обсуждении.