Sand AI выпускает MAGI-1: авторегрессивная генерация видео в масштабе
Sand AI открыл исходный код MAGI-1, авторегрессивной модели, которая генерирует видео по частям, предлагая версии с 24B и 4.5B параметрами и поддерживая множественные режимы генерации видео
Команда Sand AI официально открыла исходный код модели генерации видео MAGI-1 21 апреля, с планами выпустить версию с 4.5B параметрами к концу апреля. Это мировая модель, способная предсказывать последовательности видео-чанков авторегрессивно, поддерживающая методы генерации Текст-в-Видео (T2V), Изображение-в-Видео (I2V) и Видео-в-Видео (V2V).
Технические инновации
MAGI-1 использует множественные технические инновации, которые дают ему уникальные преимущества в области генерации видео:
VAE на основе Transformer
- Использует вариационный автоэнкодер на основе Transformer с 8x пространственным и 4x временным сжатием
- Имеет самое быстрое среднее время декодирования при поддержании высококачественной реконструкции
Авторегрессивный алгоритм деноизинга
MAGI-1 генерирует видео авторегрессивно, по частям, а не все сразу. Каждый чанк (24 кадра) деноизируется целостно, и генерация следующего чанка начинается, как только текущий достигает определенного уровня деноизинга. Этот дизайн позволяет одновременную обработку до четырех чанков для эффективной генерации видео.

Архитектура диффузионной модели
MAGI-1 построена на основе Diffusion Transformer, включая несколько ключевых инноваций для улучшения эффективности обучения и стабильности в масштабе. Эти продвижения включают Block-Causal Attention, Parallel Attention Block, QK-Norm и GQA, Sandwich Normalization в FFN, SwiGLU и Softcap Modulation.
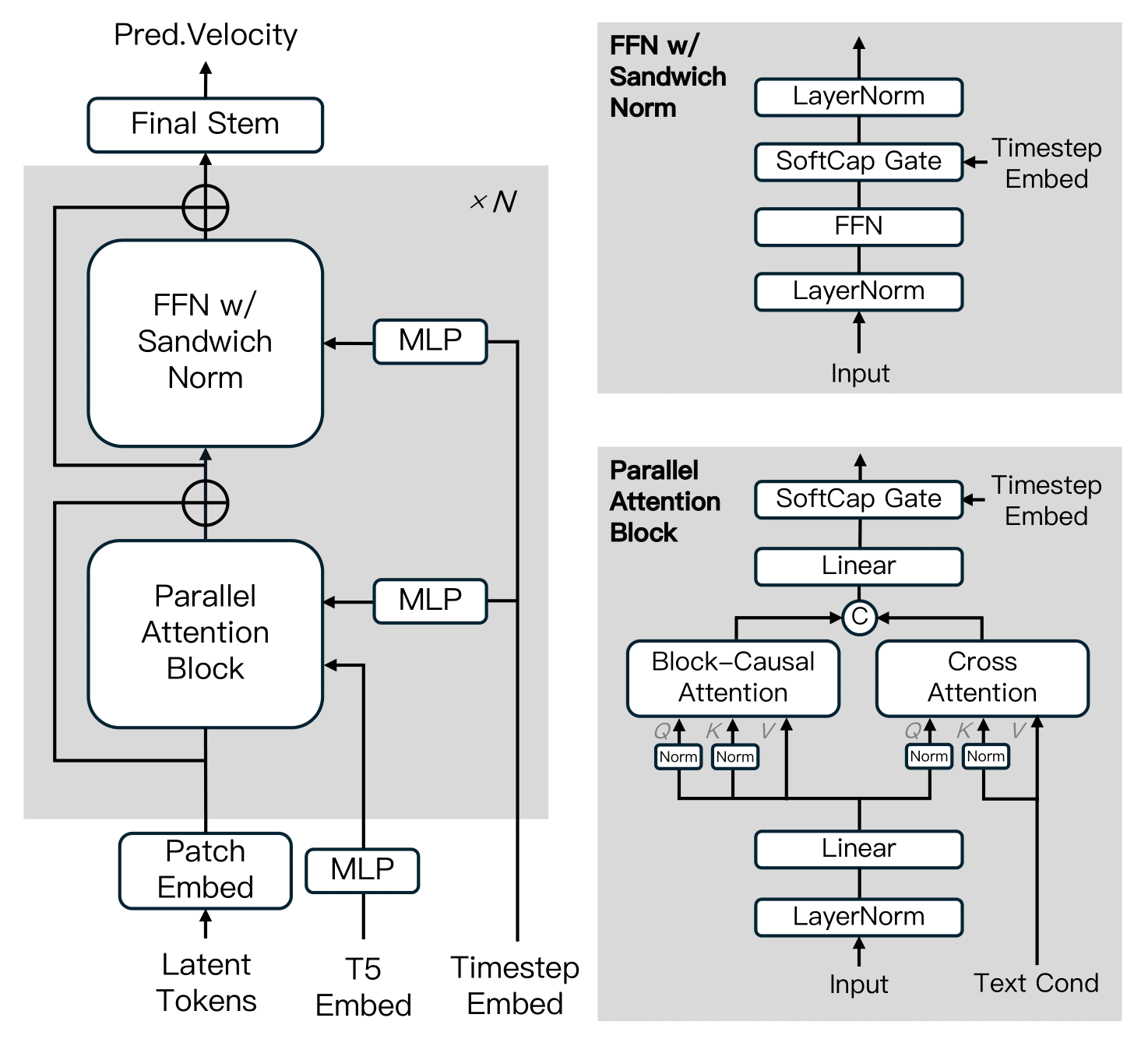
Алгоритм дистилляции
Модель принимает подход shortcut дистилляции, который обучает единственную модель на основе скорости для поддержки переменных бюджетов вывода. Принуждая ограничение самосогласованности — приравнивая один большой шаг к двум меньшим шагам — модель учится аппроксимировать flow-matching траектории через множественные размеры шагов. Во время обучения размеры шагов циклически выбираются из 64, 32, 16, 8, и включается classifier-free guidance дистилляция для сохранения условного выравнивания. Это позволяет эффективный вывод с минимальной потерей в верности.
Версии модели
Sand AI предоставляет предобученные веса для множественных версий MAGI-1, включая 24B и 4.5B модели, а также соответствующие дистиллированные и квантизированные модели:
| Модель | Рекомендуемое оборудование | |
-- |
- | | MAGI-1-24B | H100/H800 × 8 | | MAGI-1-24B-distill | H100/H800 × 8 | | MAGI-1-24B-distill+fp8_quant | H100/H800 × 4 или RTX 4090 × 8 | | MAGI-1-4.5B | RTX 4090 × 1 |
Оценка производительности
Физическая оценка
Благодаря естественным преимуществам авторегрессивной архитектуры, MAGI-1 достигает далеко превосходящей точности в предсказании физического поведения на бенчмарке Physics-IQ через продолжение видео.
В оценке Physics-IQ режим Видео-в-Видео (V2V) MAGI достигает 56.02 баллов, в то время как его режим Изображение-в-Видео (I2V) достигает 30.23 баллов, значительно превосходя другие модели с открытым и закрытым исходным кодом, такие как VideoPoet, Kling1.6 и Sora.
Как запустить
MAGI-1 поддерживает запуск через либо Docker окружение (рекомендуется), либо исходный код. Пользователи могут гибко контролировать ввод и вывод, настраивая параметры в скрипте run.sh для удовлетворения различных требований:
--mode: Указывает режим операции (t2v, i2v или v2v)--prompt: Текстовый промпт, используемый для генерации видео--image_path: Путь к файлу изображения (используется только в режиме i2v)--prefix_video_path: Путь к файлу префиксного видео (используется только в режиме v2v)--output_path: Путь, где будет сохранен сгенерированный видео файл
Комментарии
Войдите через GitHub, чтобы участвовать в обсуждении.