Sesame представляет голосовую модель CSM для естественных разговоров
Sesame Research представляет двухтрансформерную разговорную голосовую модель CSM, достигающую человеческого взаимодействия с архитектурой открытого исходного кода
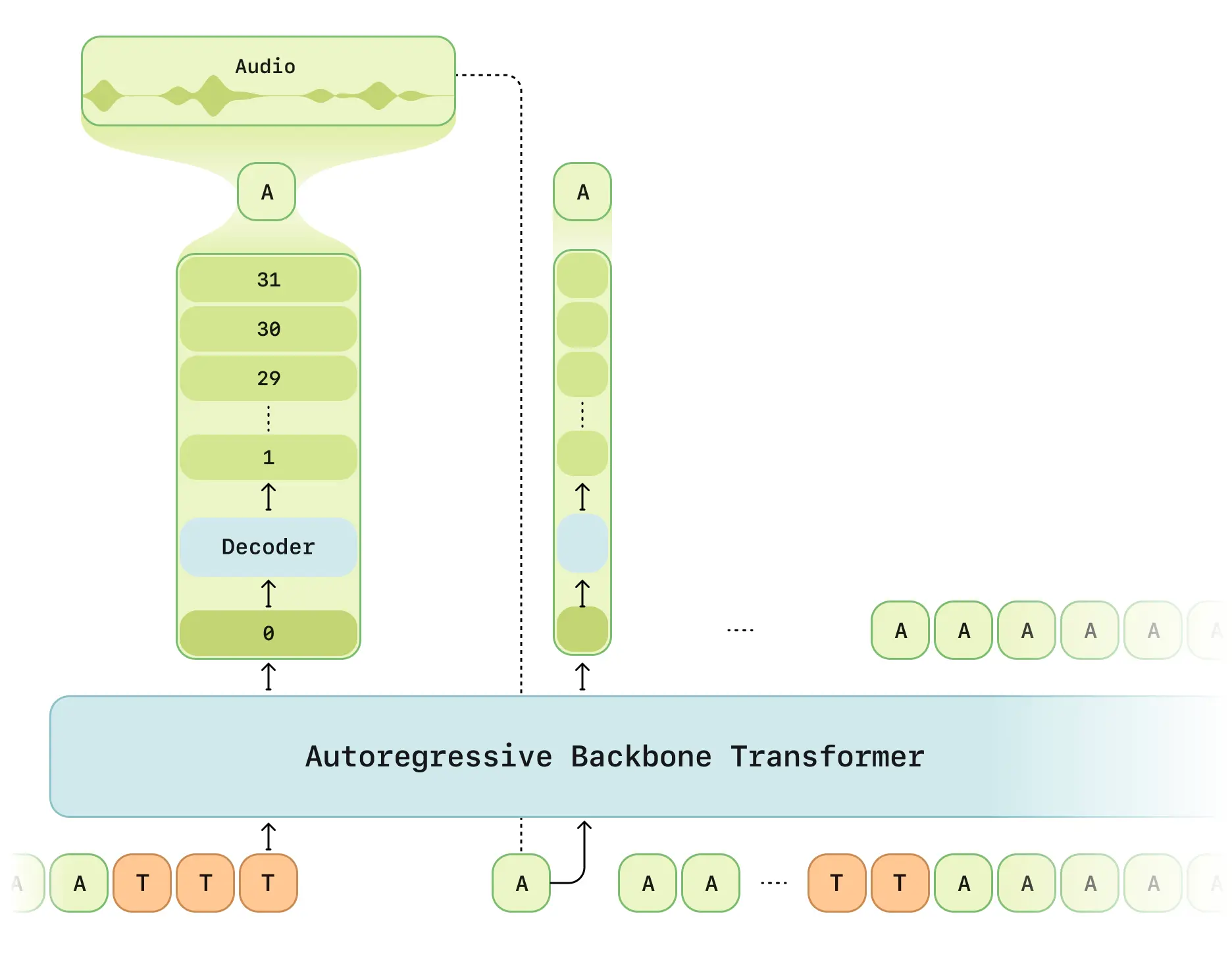
Модель разговорной речи (CSM) от Sesame Research демонстрирует прорывные возможности в официальной демонстрации. Двухтрансформерная архитектура обеспечивает почти человеческое голосовое взаимодействие.
Техническая архитектура
Ключевые особенности дизайна:
- Двухэтапная обработка: Мультимодальная основа (текст/речь) + аудио декодер
- RVQ токенизатор: Дискретный квантизатор Mimi с частотой кадров 12.5Гц
- Оптимизация задержки: Решает традиционные задержки генерации RVQ
- Планирование вычислений: 1/16 сэмплирование кадров для эффективности
- Фреймворк Llama: Базовая сеть на основе LLaMA
Ключевые особенности
- Осведомленность о контексте: 2-минутная память разговора (2048 токенов)
- Эмоциональный интеллект: 6-слойный классификатор эмоций
- Интеракция в реальном времени: < 500мс сквозная задержка (средняя 380мс)
- Поддержка множественных говорящих: Одновременная обработка голоса
Технические спецификации
| Параметр | Детали | |
--|
--| | Данные обучения | 1M часов английских разговоров | | Масштаб модели | 8B основа + 300M декодер | | Длина последовательности | 2048 токенов (~2 минуты) | | Поддержка оборудования| RTX 4090 или выше |
Статус открытого исходного кода
Репозиторий GitHub включает:
- Полный технический документ архитектуры
- Примеры REST API
- Инструментарий предварительной обработки аудио
- Руководство по квантизации модели
⚠️ Ограничения:
- Основной код обучения не выпущен (планируется Q3 2025)
- Требуется API ключ
- Реализация в первую очередь на английском
Результаты оценки
Официальные бенчмарки показывают:
- Естественность: CMOS оценка соответствует человеческим записям
- Понимание контекста: 37% улучшение точности
- Согласованность произношения: 95% стабильность
- Задержка: 68% улучшение генерации первого кадра
Технические источники: Исследовательская статья | X
Комментарии
Войдите через GitHub, чтобы участвовать в обсуждении.