XVerse 출시: 다중 객체 식별과 의미론적 속성 제어가 가능한 고일관성 이미지 생성 모델
ByteDance가 XVerse 모델을 오픈소스로 공개. 다중 객체의 식별과 의미론적 속성(포즈, 스타일, 조명 등)을 정밀하게 독립적으로 제어할 수 있어 AI 이미지 생성의 개인화와 복잡한 장면 생성 능력을 향상
XVerse는 ByteDance의 Creative AI 팀이 2025년에 오픈소스로 공개한 제어 가능한 다중 객체 이미지 생성 모델입니다. AI 생성 이미지에서 여러 객체(사람, 동물, 사물 등)의 정밀한 독립 제어라는 과제 해결에 중점을 두고 있습니다. 이 모델은 이미지 내 여러 객체의 식별, 포즈, 스타일, 조명 등의 속성을 세밀하게 간섭 없이 조정할 수 있어 개인화된 복잡한 장면의 생성 능력을 크게 향상시켰습니다.

I. 핵심 기능과 혁신
- 독립적인 다중 객체 제어: 여러 객체의 식별, 동작, 스타일을 동시에 정밀하게 제어하여 기존 방식에서 흔히 발생하는 "속성 얽힘" 문제를 해결합니다.
- 높은 충실도와 세부 사항 보존: VAE 이미지 특징 인코딩을 통해 머리카락과 텍스처 같은 세부 사항을 보존하고 아티팩트와 왜곡을 줄입니다.
- 유연한 의미론적 속성 편집: 조명과 예술적 스타일 같은 비식별 속성의 유연한 조정을 지원하며 장면 전환 시 객체의 특성을 유지합니다.
- 높은 일관성과 안정성: 혁신적인 텍스트 흐름 변조 메커니즘과 이중 정규화(영역 보호 손실, 텍스트-이미지 주의 손실)로 생성의 안정성과 일관성을 보장합니다.
II. 기술 원리 개요
1. 텍스트 흐름 변조 메커니즘(T-Mod Adapter)
- 참조 이미지를 텍스트 임베딩 오프셋으로 변환하여 계층화된 제어 신호(전역 공유 + 블록 변조)를 통해 다중 객체의 정밀한 독립 제어를 실현합니다.
- T-Mod 어댑터는 CLIP 이미지 특징과 텍스트 프롬프트를 통합하여 특징 혼동을 피하기 위한 교차 변조 신호를 생성합니다.
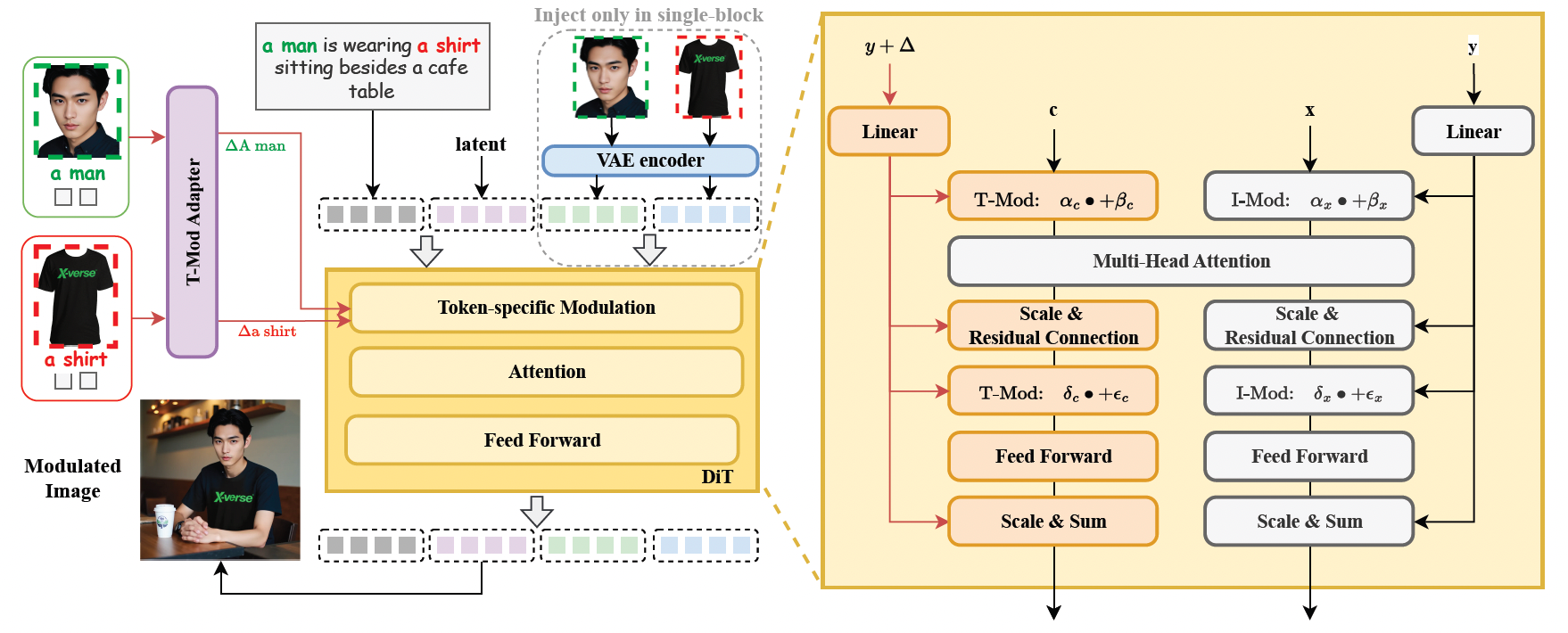
2. VAE 이미지 특징 인코딩 모듈
- FLUX 구조에 VAE 인코딩된 특징을 도입하여 세부 사항 보존을 강화하고 생성된 이미지를 더욱 사실적이고 자연스럽게 만듭니다.
3. 이중 정규화 메커니즘
- 영역 보호 손실: 변조로부터 특정 영역을 무작위로 보호하여 비대상 객체가 영향을 받지 않도록 합니다.
- 텍스트-이미지 주의 손실: 주의력 할당을 최적화하여 의미론적 정렬 정확도를 향상시킵니다.
III. 학습 데이터와 평가 벤치마크
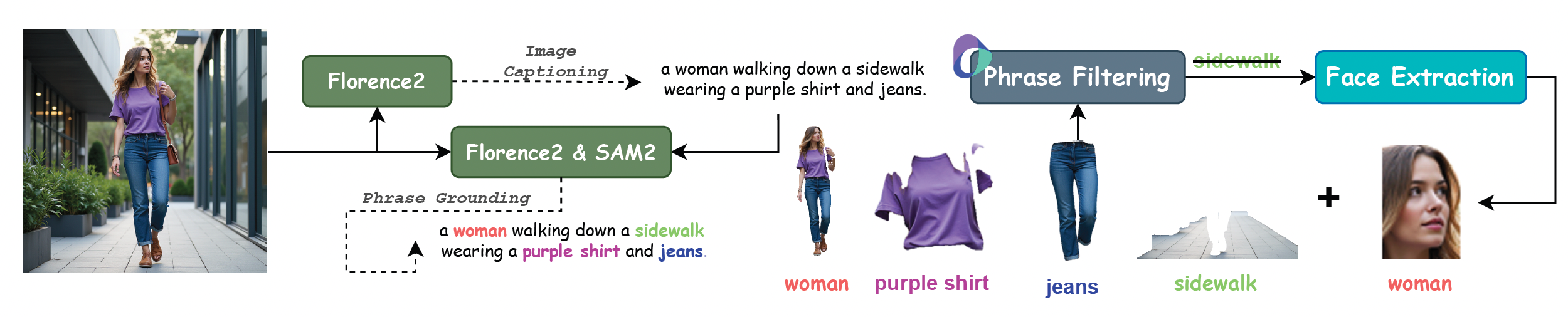
XVerse는 20종의 사람, 74종의 아이템, 45종의 동물을 포함하는 고품질 다중 객체 제어 데이터셋을 사용하여 수백만 개의 높은 미적 품질의 이미지를 합성합니다.
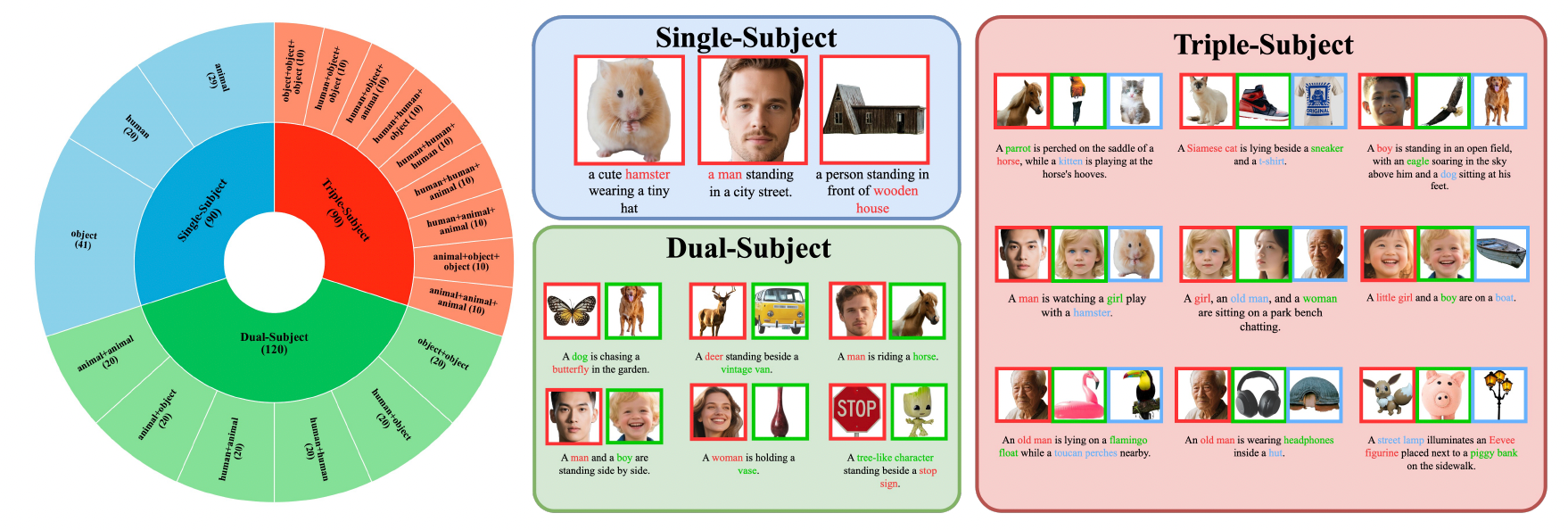
모델 성능은 XVerseBench 벤치마크에서 유사한 방법들을 크게 능가하며, 단일, 이중, 삼중 객체를 포함한 다양한 제어 시나리오를 지원합니다.
| 메트릭 | 의미 | | | | | DPG 점수 | 편집 능력 | | 얼굴 ID 유사도 | 인물 식별 일관성 | | DINOv2 유사도 | 객체 특징 일관성 | | 미적 점수 | 이미지 미적 품질 |
IV. 실험 결과와 사례 연구
1. 단일 객체 식별과 속성의 정밀 제어
XVerse는 다양한 시나리오에서 객체의 식별 일관성을 유지하면서 포즈, 의상, 환경 등의 속성을 유연하게 조정합니다.





2. 다중 객체 일관성과 독립 제어
XVerse는 동일 이미지 내에서 여러 객체의 식별과 속성을 독립적으로 제어하면서 자연스러운 상호작용과 장면의 일관성을 유지합니다.





3. 유연한 의미론적 속성 제어
XVerse는 조명, 포즈, 스타일 등의 의미론적 속성을 세밀하게 조정하여 다양한 창작 요구를 충족합니다.

V. 오픈소스와 관련 리소스
- 프로젝트 홈페이지: https://bytedance.github.io/XVerse/
- GitHub 저장소: https://github.com/bytedance/XVerse
- 모델 다운로드: https://huggingface.co/ByteDance/XVerse
- 기술 논문: https://arxiv.org/abs/2506.21416
XVerse 공식 홈페이지, GitHub 및 관련 오픈소스 자료를 참조한 내용입니다.
댓글
GitHub로 로그인하고 토론에 참여하세요.