Sand AI, MAGI-1 출시: 대규모 자기회귀 비디오 생성 모델
Sand AI가 MAGI-1을 오픈소스로 공개했습니다. 이 자기회귀 모델은 비디오를 청크별로 생성하며, 24B 및 4.5B 매개변수 버전을 제공하고 다양한 비디오 생성 모드를 지원합니다
Sand AI 팀은 4월 21일에 MAGI-1 비디오 생성 모델을 공식적으로 오픈소스로 공개했으며, 4월 말까지 4.5B 매개변수 버전을 출시할 계획입니다. 이는 비디오 청크 시퀀스를 자기회귀적으로 예측할 수 있는 세계 모델로, 텍스트-투-비디오(T2V), 이미지-투-비디오(I2V) 및 비디오-투-비디오(V2V) 생성 방법을 지원합니다.
기술 혁신
MAGI-1은 비디오 생성 분야에서 고유한 이점을 제공하는 여러 기술 혁신을 채택했습니다:
트랜스포머 기반 VAE
- 8배 공간 압축 및 4배 시간 압축을 갖춘 트랜스포머 기반 변분 오토인코더 사용
- 고품질 재구성을 유지하면서 가장 빠른 평균 디코딩 시간 제공
자기회귀 디노이징 알고리즘
MAGI-1은 한 번에 모든 것을 생성하는 대신 자기회귀적으로 청크별로 비디오를 생성합니다. 각 청크(24프레임)는 전체적으로 디노이징되며, 현재 청크가 특정 디노이징 수준에 도달하면 다음 청크의 생성이 시작됩니다. 이 설계는 효율적인 비디오 생성을 위해 최대 4개의 청크를 동시에 처리할 수 있게 합니다.

확산 모델 아키텍처
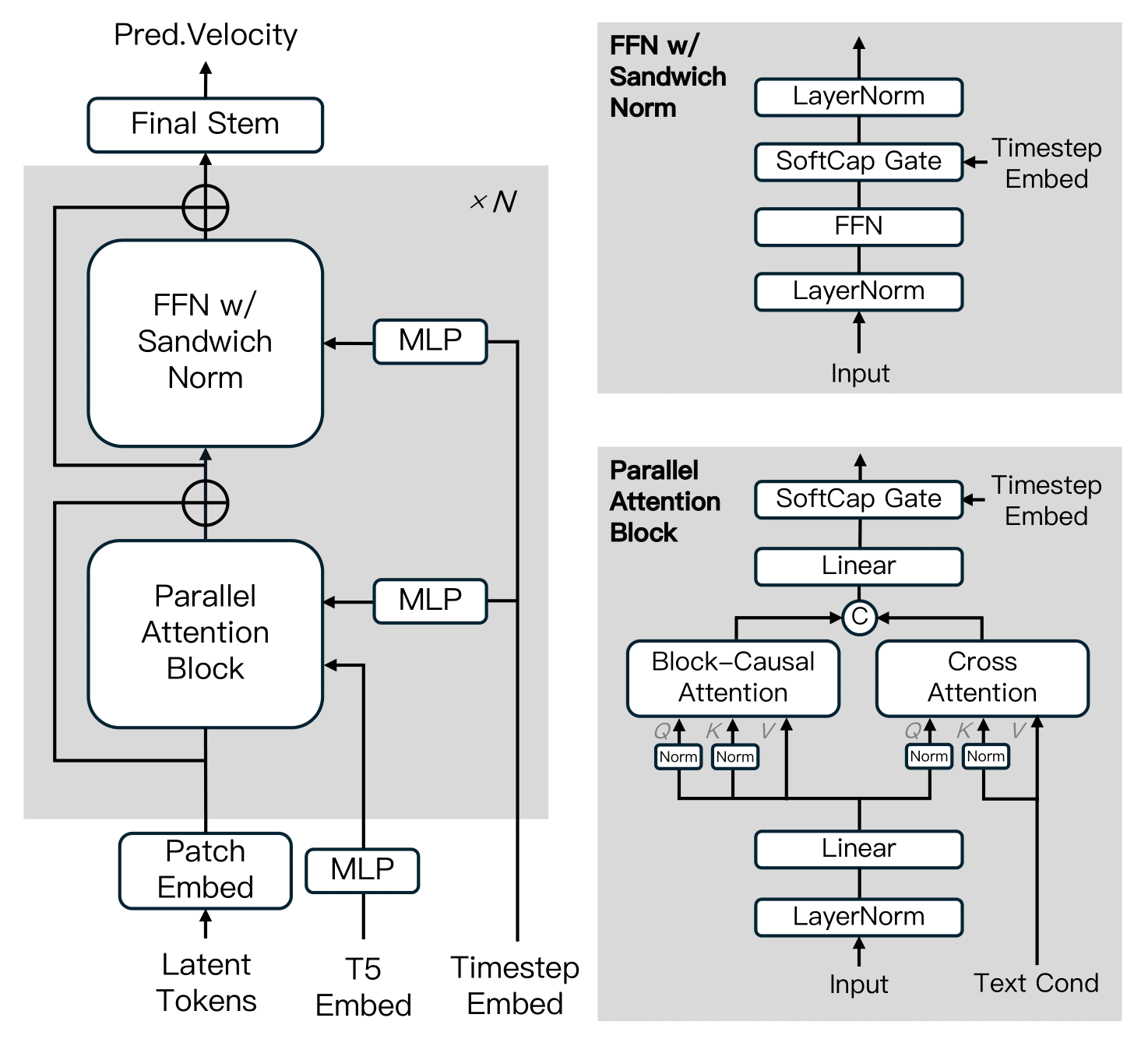
MAGI-1은 확산 트랜스포머를 기반으로 구축되었으며, 대규모에서 훈련 효율성과 안정성을 향상시키기 위한 여러 핵심 혁신을 통합했습니다. 이러한 발전에는 블록-인과 어텐션, 병렬 어텐션 블록, QK-정규화 및 GQA, FFN의 샌드위치 정규화, SwiGLU 및 소프트캡 모듈레이션이 포함됩니다.
증류 알고리즘
이 모델은 다양한 추론 예산을 지원하기 위해 단일 속도 기반 모델을 훈련시키는 단축 증류 접근 방식을 채택했습니다. 자체 일관성 제약(하나의 큰 단계를 두 개의 작은 단계와 동등하게 만드는 것)을 적용함으로써, 모델은 여러 단계 크기에 걸쳐 흐름 매칭 궤적을 근사하는 법을 배웁니다. 훈련 중에는 64, 32, 16, 8에서 단계 크기가 주기적으로 샘플링되며, 조건부 정렬을 유지하기 위해 분류기 없는 지침 증류가 통합됩니다. 이를 통해 충실도 손실을 최소화하면서 효율적인 추론이 가능합니다.
모델 버전
Sand AI는 MAGI-1의 여러 버전에 대한 사전 훈련된 가중치를 제공하며, 24B 및 4.5B 모델과 해당 증류 및 양자화 모델이 포함됩니다:
| 모델 | 권장 하드웨어 | |
-- |
- | | MAGI-1-24B | H100/H800 × 8 | | MAGI-1-24B-distill | H100/H800 × 8 | | MAGI-1-24B-distill+fp8_quant | H100/H800 × 4 또는 RTX 4090 × 8 | | MAGI-1-4.5B | RTX 4090 × 1 |
성능 평가
물리적 평가
자기회귀 아키텍처의 자연적인 이점 덕분에, MAGI-1은 비디오 연속을 통해 Physics-IQ 벤치마크에서 물리적 행동을 예측하는 데 훨씬 우수한 정확도를 달성합니다.
Physics-IQ 점수에서 MAGI의 비디오-투-비디오(V2V) 모드는 56.02점을 달성하고, 이미지-투-비디오(I2V) 모드는 30.23점에 도달하여 VideoPoet, Kling1.6, Sora와 같은 다른 오픈소스 및 폐쇄소스 상업 모델을 크게 능가합니다.
실행 방법
MAGI-1은 Docker 환경(권장) 또는 소스 코드를 통한 실행을 지원합니다. 사용자는 run.sh 스크립트의 매개변수를 조정하여 다양한 요구 사항을 충족하기 위해 입력과 출력을 유연하게 제어할 수 있습니다:
--mode: 작동 모드 지정(t2v, i2v 또는 v2v)--prompt: 비디오 생성에 사용되는 텍스트 프롬프트--image_path: 이미지 파일 경로(i2v 모드에서만 사용)--prefix_video_path: 접두사 비디오 파일 경로(v2v 모드에서만 사용)--output_path: 생성된 비디오 파일이 저장될 경로
댓글
GitHub로 로그인하고 토론에 참여하세요.