TTT-Video: 장편 비디오 생성을 위한 기술
연구진이 CogVideoX 5B 기반 Test-Time Training 기술을 활용한 TTT-Video 모델을 개발하여 최대 63초 길이의 일관된 비디오 생성 가능
연구진은 최근 TTT-Video라는 오픈소스 프로젝트를 공개했습니다. 이 기술은 AI 비디오 생성의 전통적인 시간 제한을 극복하여 최대 63초의 일관된 비디오 콘텐츠를 생성할 수 있습니다. 이 기술은 혁신적인 Test-Time Training(테스트 시간 학습) 방법을 통해 장편 비디오 생성 과정에서의 콘텐츠 일관성 문제를 해결합니다.
비디오 생성의 주요 도전 과제 해결
현재 대부분의 AI 비디오 생성 모델은 3-5초의 짧은 비디오 클립만 생성할 수 있습니다. 이는 비디오 생성에 사용되는 Transformer 모델이 자기 주의 메커니즘으로 인해 긴 시퀀스를 처리할 때 계산 비용이 제곱으로 증가하여 긴 비디오를 효율적으로 처리하기 어렵기 때문입니다.
TTT-Video는 혁신적인 방식으로 이 문제를 해결합니다: 원래 사전 훈련된 모델의 주의 레이어를 각 3초 세그먼트의 로컬 주의에 사용하면서, 글로벌 컨텍스트의 장거리 관계를 처리하기 위한 특별한 Test-Time Training 레이어를 도입했습니다.
기술적 구현
이 프로젝트는 CogVideoX 5B 모델(텍스트에서 비디오 생성을 위한 확산 Transformer)을 기반으로 하며, 주요 혁신 사항은 다음과 같습니다:
- 게이트된 잔차 연결을 통해 출력을 결합하는 전역 시퀀스와 그 역방향 버전을 처리하는 TTT 레이어 도입
- 각 세그먼트와 텍스트 및 비디오 임베딩을 인터리빙하여 컨텍스트 확장
- 단계적 훈련: 먼저 원래 사전 훈련된 3초 비디오 길이에서 미세 조정한 다음 9초, 18초, 30초, 63초 비디오 길이에서 점진적으로 훈련
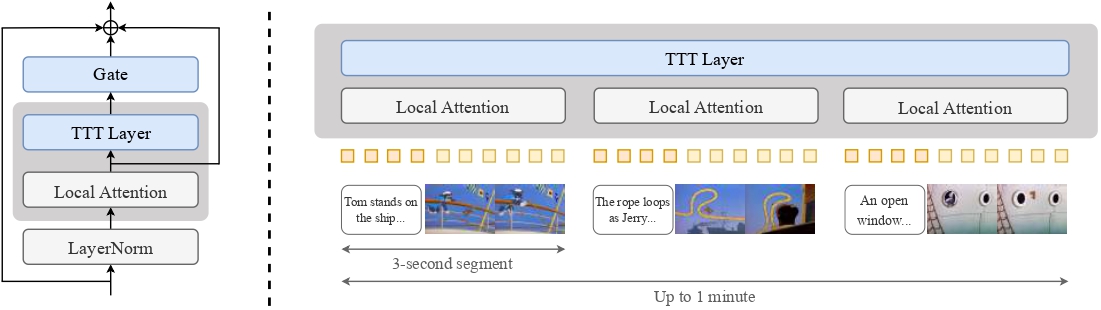
TTT-Video 모델 아키텍처: 로컬 주의 메커니즘과 결합된 TTT 레이어를 통한 글로벌 시퀀스 처리
연구팀은 고전 만화 "톰과 제리"를 테스트 케이스로 사용하여 스타일적으로 일관되고 약 1분 길이의 연속된 애니메이션 비디오를 생성했습니다. 다만 5B 매개변수 크기의 제한으로 인해 생성 품질에는 아직 개선의 여지가 있습니다.
인상적인 생성 결과
<video style={{ width: '100%', maxWidth: '680px' }} src="https://test-time-training.github.io/video-dit/videos/63s-demo/homeless.mp4" controls />
TTT-Video의 가장 인상적인 측면은 한 번에 최대 1분 길이의 "톰과 제리" 스타일 애니메이션을 생성할 수 있다는 점입니다:
- 편집, 스플라이싱 또는 후처리가 필요 없음
- 원본 만화에 존재하지 않는 장면으로 완전히 독창적인 콘텐츠
- 일관된 캐릭터 동작, 장면 전환 및 스토리라인

TTT-Video가 톰과 제리 스타일로 생성한 애니메이션 프레임
AI 창작자에게 주는 의미
이 기술은 ComfyUI와 같은 도구를 사용하는 AI 창작자에게 다음과 같은 의미가 있습니다:
- 미래에 더 길고 서사적인 AI 비디오 생성 가능성
- 비디오 생성에서 일관성과 연속성의 주요 문제 해결
- 창작자가 여러 세그먼트를 수동으로 스플라이싱할 필요 없이 더 긴 비디오 콘텐츠를 만들 수 있는 가능성
댓글
GitHub로 로그인하고 토론에 참여하세요.