StdGEN: 단일 이미지에서 의미적으로 분해된 3D 캐릭터 생성
칭화대학교와 텐센트 AI 연구소가 공동으로 StdGEN을 발표, 단일 이미지에서 신체, 의복, 머리카락 등 구성 요소가 분리된 고품질 의미 분해 3D 캐릭터를 생성하는 혁신적인 파이프라인 제공

칭화대학교와 텐센트 AI 연구소의 연구팀이 최근 StdGEN(Semantic-Decomposed 3D Character Generation)이라는 혁신적인 기술을 발표했습니다. 이 기술은 단일 이미지에서 의미적으로 분해된 고품질 3D 캐릭터 모델을 생성할 수 있습니다. 이 연구는 컴퓨터 비전 분야의 최고 학회인 CVPR 2025에 채택되었습니다.
기술적 혁신
StdGEN은 혁신적인 파이프라인을 통해 세 가지 주요 특징을 구현합니다:
- 의미적 분해 능력: 생성된 3D 캐릭터 모델은 신체, 의복, 머리카락 등의 의미적 구성 요소로 완전히 분리될 수 있어 후속 편집 및 사용자 지정이 용이합니다.
- 효율성: 단일 이미지에서 완전한 3D 캐릭터로의 처리 과정이 단 3분만에 완료됩니다.
- 고품질 재구성: 생성된 3D 모델은 미세한 기하학적 세부 사항과 텍스처를 갖추고 있습니다.
핵심 기술
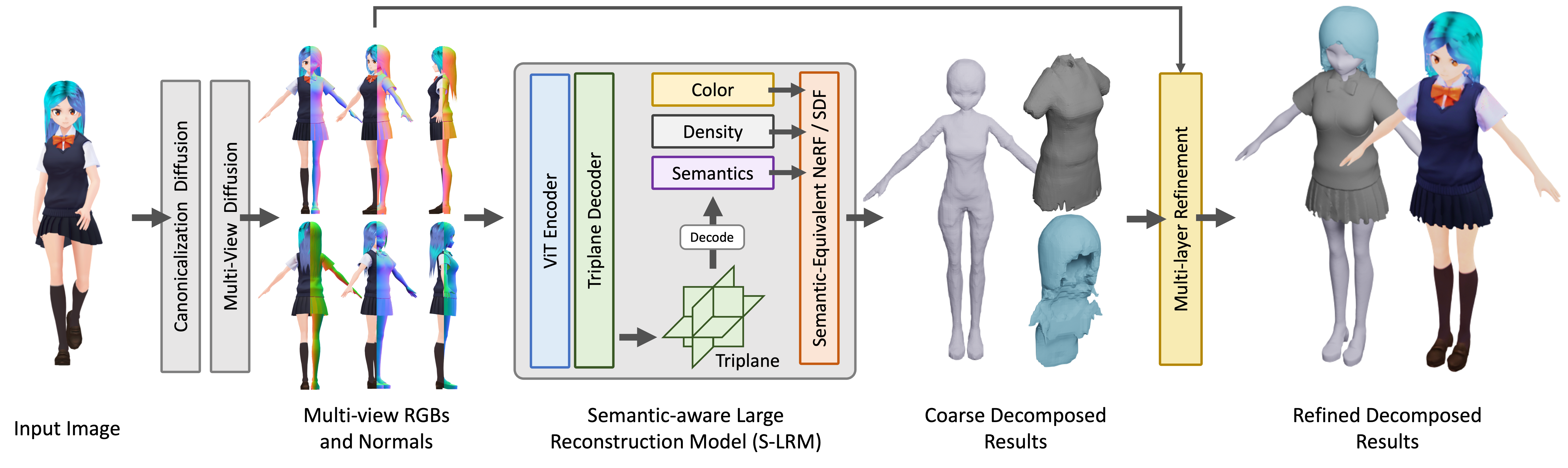 StdGEN의 핵심은 연구팀이 제안한 **의미 인식 대규모 재구성 모델(S-LRM)**입니다. 이는 다중 시점 이미지에서 기하학, 색상 및 의미적 정보를 피드포워드 방식으로 공동 재구성할 수 있는 일반화 가능한 트랜스포머 기반 모델입니다.
StdGEN의 핵심은 연구팀이 제안한 **의미 인식 대규모 재구성 모델(S-LRM)**입니다. 이는 다중 시점 이미지에서 기하학, 색상 및 의미적 정보를 피드포워드 방식으로 공동 재구성할 수 있는 일반화 가능한 트랜스포머 기반 모델입니다.
또한, 이 방법은 다음과 같은 혁신을 도입합니다:
- S-LRM이 재구성한 하이브리드 암시적 필드에서 메시를 얻기 위한 차등 다층 의미적 표면 추출 방식
- 특수화된 효율적인 다중 시점 확산 모델
- 반복적 다층 표면 정제 모듈
응용 전망
이 기술은 가상 현실, 게임 개발 및 영화 제작 분야에서 광범위한 응용 전망을 가지고 있습니다. 기존 방법에 비해 StdGEN은 기하학, 텍스처 및 분해 가능성 측면에서 상당한 개선을 이루어, 사용자에게 유연한 맞춤화를 지원하는 즉시 사용 가능한 의미적으로 분해된 3D 캐릭터를 제공합니다.
연구팀은 추론 코드, 데이터셋 및 사전 훈련된 체크포인트를 오픈소스로 공개했으며, HuggingFace Gradio를 통한 온라인 데모도 제공하고 있습니다.
댓글
GitHub로 로그인하고 토론에 참여하세요.