Sesame, CSM 음성 모델 공개로 음성 인터랙션 혁신
ComfyUI Wikinews
Sesame 연구팀이 이중 Transformer 아키텍처 기반 대화형 음성 모델 CSM 공개, 실시간 음성 상호작용 구현 및 오픈소스 코어 제공
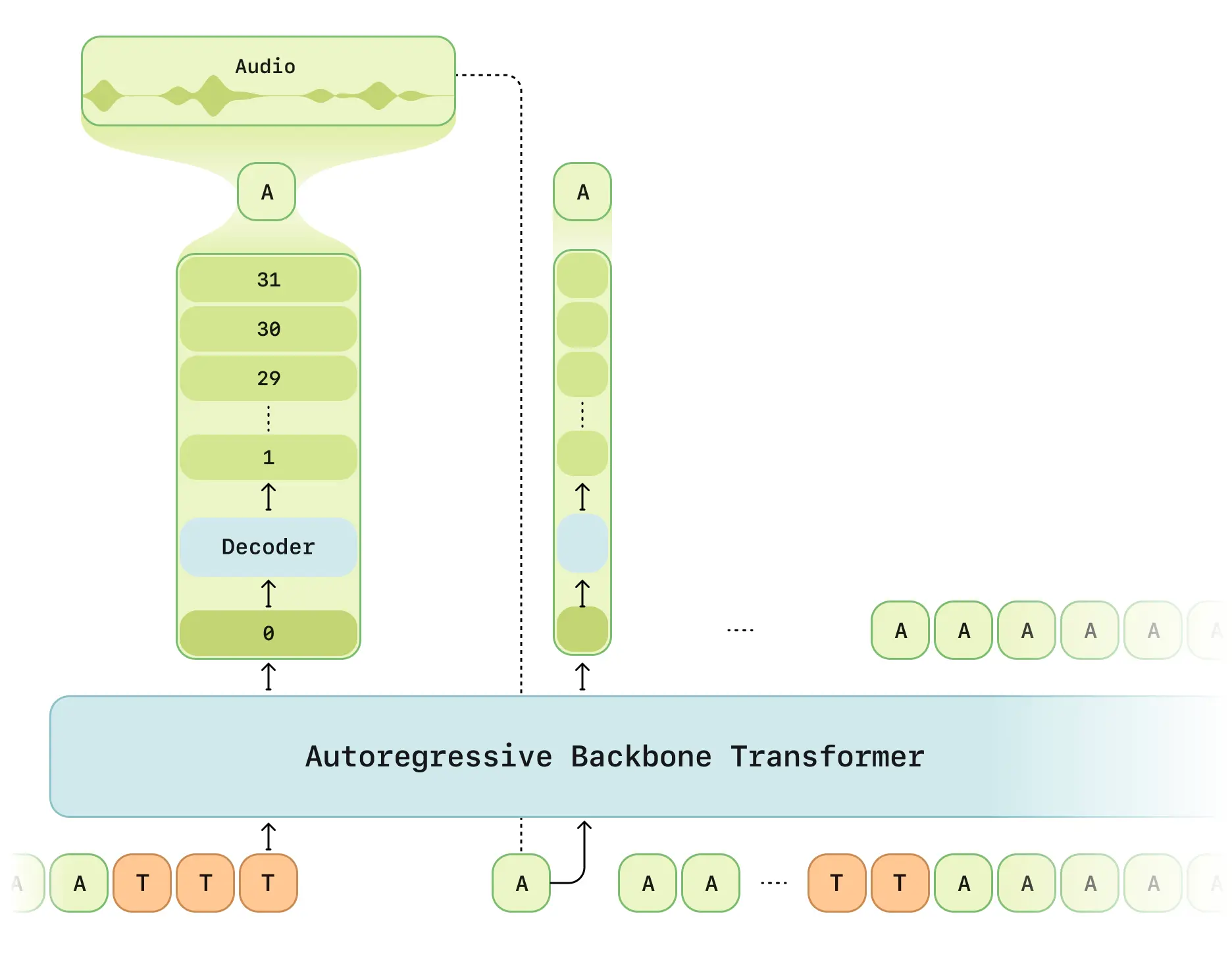
Sesame 연구팀이 공개한 대화형 음성 모델 CSM이 공식 데모를 통해 혁신적인 음성 상호작용 능력을 선보였습니다. 이중 Transformer 아키텍처를 통해 인간과 유사한 수준의 음성 대화를 구현했습니다.
기술 아키텍처
CSM의 핵심 설계 요소:
- 이중 처리 단계: 멀티모달 백본 네트워크(텍스트/음성 처리) + 오디오 디코더
- RVQ 토크나이저: Mimi 분리형 양자화 인코더 적용 (12.5Hz 프레임 레이트)
- 지연 최적화 모드: 기존 RVQ 생성의 시간 지연 문제 해결
- 계산 분담 방식: 1/16 프레임 샘플링으로 학습 효율 향상
- Llama 구조: LLaMA 모델 기반 개선된 백본 네트워크
핵심 기능
- 맥락 인식: 최대 2분 대화 기억 (2048 토큰)
- 감정 인텔리전스: 6계층 감정 분류기로 대화 감정 분석
- 실시간 상호작용: 종단 간 지연 시간 < 500ms (평균 380ms)
- 다중 화자 지원: 단일 생성으로 다중 화자 음성 처리
기술 사양
| 항목 | 내용 | |
|
-| | 학습 데이터 | 100만 시간 영어 대화 녹음 | | 모델 규모 | 8B 백본 + 300M 디코더 | | 시퀀스 길이 | 2048 토큰 (약 2분) | | 지원 장비 | RTX 4090 이상 |
오픈소스 현황
GitHub 저장소 제공 내용:
- 완전한 아키텍처 백서
- REST API 호출 예시
- 오디오 전처리 툴킷
- 모델 양자화 배포 가이드
⚠️ 사용 제한:
- 핵심 학습 코드 미공개 (2025년 3분기 예정)
- API 키 필요
- 영어 환경 우선 지원
평가 결과
공식 테스트 보고서 기준:
- 자연스러움: CMOS 점수 인간 음성과 유사
- 맥락 이해: 상황 인식 정확도 37% 향상
- 발음 일관성: 95% 발음 안정성 유지
- 지연 시간: 첫 프레임 생성 시간 68% 개선
댓글
GitHub로 로그인하고 토론에 참여하세요.