알리바바, ACE++ 오픈소스 공개: 학습 없이 캐릭터 일관성 이미지 생성 구현
알리바바 연구소가 이미지 생성 도구 ACE++를 오픈소스로 공개. 문맥 인식 콘텐츠 채우기 기술을 통해 단일 입력에서 캐릭터 일관성이 있는 새로운 이미지 생성을 지원하며, 온라인 체험과 3가지 전용 모델을 제공.
2025년 2월 10일 — 알리바바 연구소가 차세대 AI 이미지 도구 ACE++의 오픈소스 공개를 공식 발표했습니다. 혁신적인 문맥 인식 콘텐츠 채우기 알고리즘을 기반으로, 사용자는 단일 입력 이미지만으로 캐릭터 특징의 높은 일관성을 가진 새로운 이미지를 생성할 수 있으며, 온라인 체험과 로컬 배포를 지원합니다.
핵심 기술 혁신
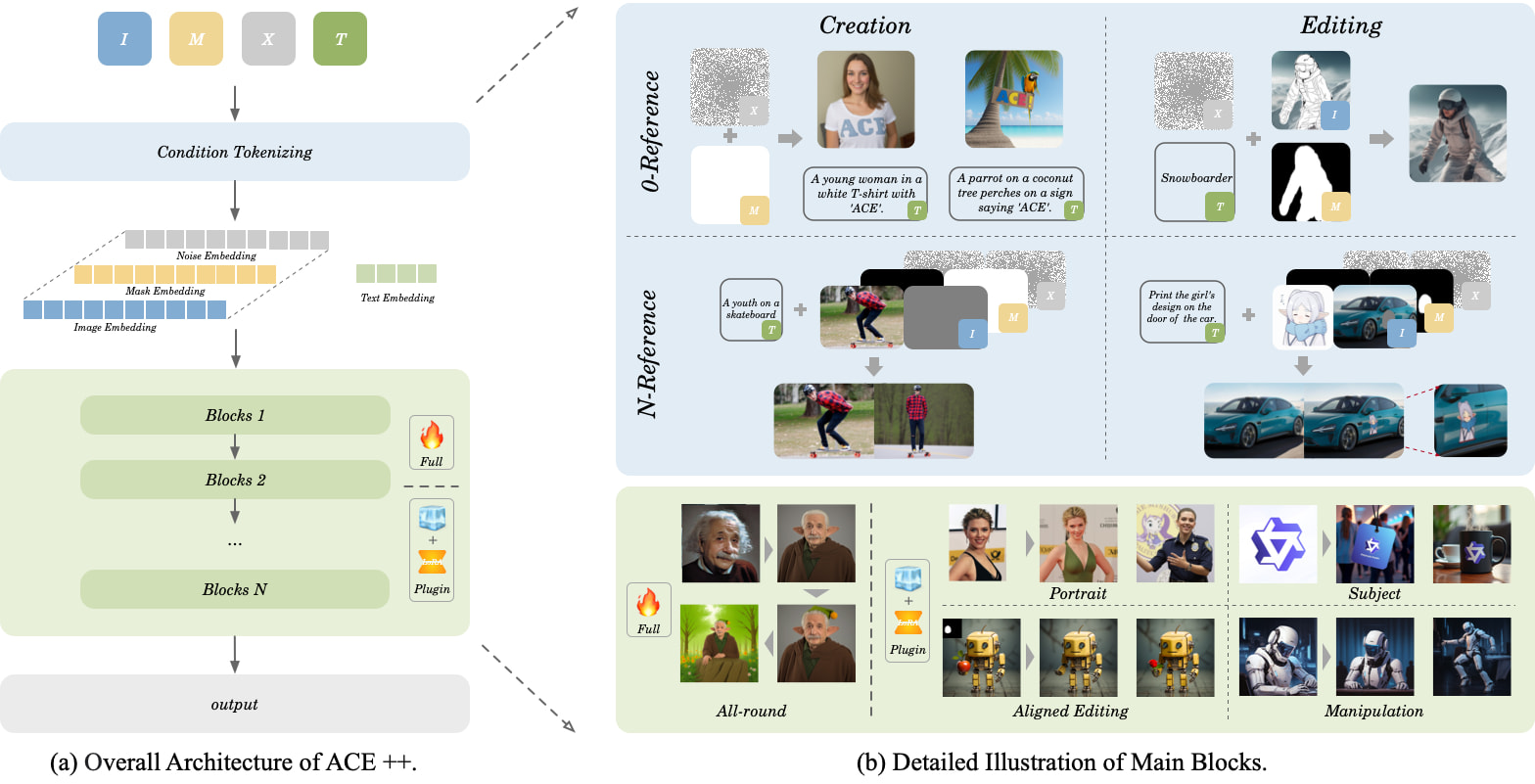
주요 특징
- 제로 트레이닝 생성: FLUX.1-Fill-dev 기본 모델을 활용하여 LoRA 적응을 통한 학습 없는 배포 실현
- 멀티모달 편집:
- 캐릭터 의상 변경 (의상/헤어스타일/액세서리 변경 지원)
- 장면 재구성 (배경 교체/객체 추가·제거)
- 스마트 복원 (결함 제거/화질 개선)
- 의미 이해: "커피잔에 증기를 추가하고 나무 테이블에 배치" 등의 복합 명령 해석 가능
기술적 돌파구
- 장기 컨텍스트 유닛(LCU): 이미지 콘텐츠, 텍스트 지시, 편집 영역을 동시 처리
- 동적 어텐션 메커니즘: 512×512 해상도에서 92.3% 특징 유지율 달성
- 이중 단계 최적화: 기본 복원 능력과 전문 편집 기술을 결합한 단계적 학습 접근
응용 시나리오 테스트
|  |
|  |
|
|
|
-|
-|
|  |
|  |
|
대표적인 응용
-
가상 모델 의상 변경
- 평면 의상 이미지에서 다각도 표시 생성
- 피부톤/체형/장면 동적 조정 지원
-
영화 캐릭터 디자인
- 크로스 스타일 변환 구현 (사실적→디즈니/사이버펑크)
- 캐릭터 특징 연속성을 유지하는 다중 장면 생성
-
스마트 이미지 복원
- 오래된 사진의 4K 해상도 재구축
- 복잡한 가림 객체의 완벽한 제거
리소스 접근 채널
공식 입구
| 리소스 유형 | 접근 주소 | |
|
--| | 프로젝트 홈페이지 | https://ali-vilab.github.io/ACE_plus_page/ | | 코드 저장소 | GitHub | | 온라인 체험 | ModelScope |
공식 모델 다운로드 링크
전용 적응 모델
| 모델 유형 | 파일명 | ModelScope 다운로드 | HuggingFace 다운로드 | |
--|
--|
-|
-| | 인물 초상화 생성 | comfyui_portrait_lora64.safetensors | Portrait 모델 | Portrait 모델 | | 객체 전이 | comfyui_subject_lora16.safetensors | Subject 모델 | Subject 모델 | | 국부 편집 | comfyui_local_lora16.safetensors | LocalEditing 모델 | LocalEditing 모델 |
기본 의존 모델
| 모델명 | 다운로드 채널 | |
--|
--| | FLUX.1-Fill-dev | HuggingFace 다운로드 | | Flux-Fill FP8 | CivitAI 다운로드 |
기술 개발 전망
현재 버전은 복잡한 객체 처리(손 세부 정확도 62.3%)와 중국어 텍스트 지원 면에서 여전히 개선의 여지가 있습니다. 개발팀은 2025년 3분기에 비디오 연속 프레임 편집 기능을 출시하고, 연말까지 완전한 ACE++ Fully 모델을 출시할 계획을 밝혔습니다.
구체적인 워크플로우 파일은 ComfyUI Wiki 실제 테스트 후 내용 업데이트를 기다려주세요 워크플로우 업데이트 보기
댓글
GitHub로 로그인하고 토론에 참여하세요.