Pixel-Reasoner:オープンソースのピクセルレベル視覚推論モデル公開
Pixel-ReasonerはQwen2をベースに、グローバルおよびローカルなピクセルレベルの視覚理解と推論能力を備え、細部の拡大分析をサポートし、視覚言語モデルの新たな進展を促します。
Pixel-ReasonerはQwen2を基盤としたオープンソースの視覚言語モデルで、ピクセルレベルでの視覚理解と推論能力の向上に特化しています。このモデルは画像全体をグローバルに分析できるだけでなく、ローカル領域を拡大して細部まで観察できるため、画像内の細かな情報をより的確に捉えることができます。
主な特徴
- ピクセルレベルの推論能力:Pixel-Reasonerは画像のピクセル空間で直接推論でき、従来のテキストベースの推論に限定されません。
- グローバルとローカルの理解を両立:モデルは全体像を把握できるだけでなく、「拡大」操作で細部にフォーカスし、より精密な分析が可能です。
- 好奇心駆動のトレーニングメカニズム:好奇心報酬メカニズムを導入し、モデルがピクセルレベルの操作を積極的に探求・活用するよう促し、視覚推論の多様性と精度を高めます。
- オープンソースで利用可能:モデル、データセット、関連コードはすべてオープンソースで公開されており、コミュニティで自由にダウンロード・体験できます。
ピクセルレベル推論の新しいパラダイム
Pixel-Reasonerは「ピクセル空間推論(Pixel-Space Reasoning)」という新しい概念を導入しています。従来の視覚言語モデルがテキスト推論のみに依存していたのに対し、Pixel-Reasonerは画像のピクセルレベルで直接分析・操作が可能です。
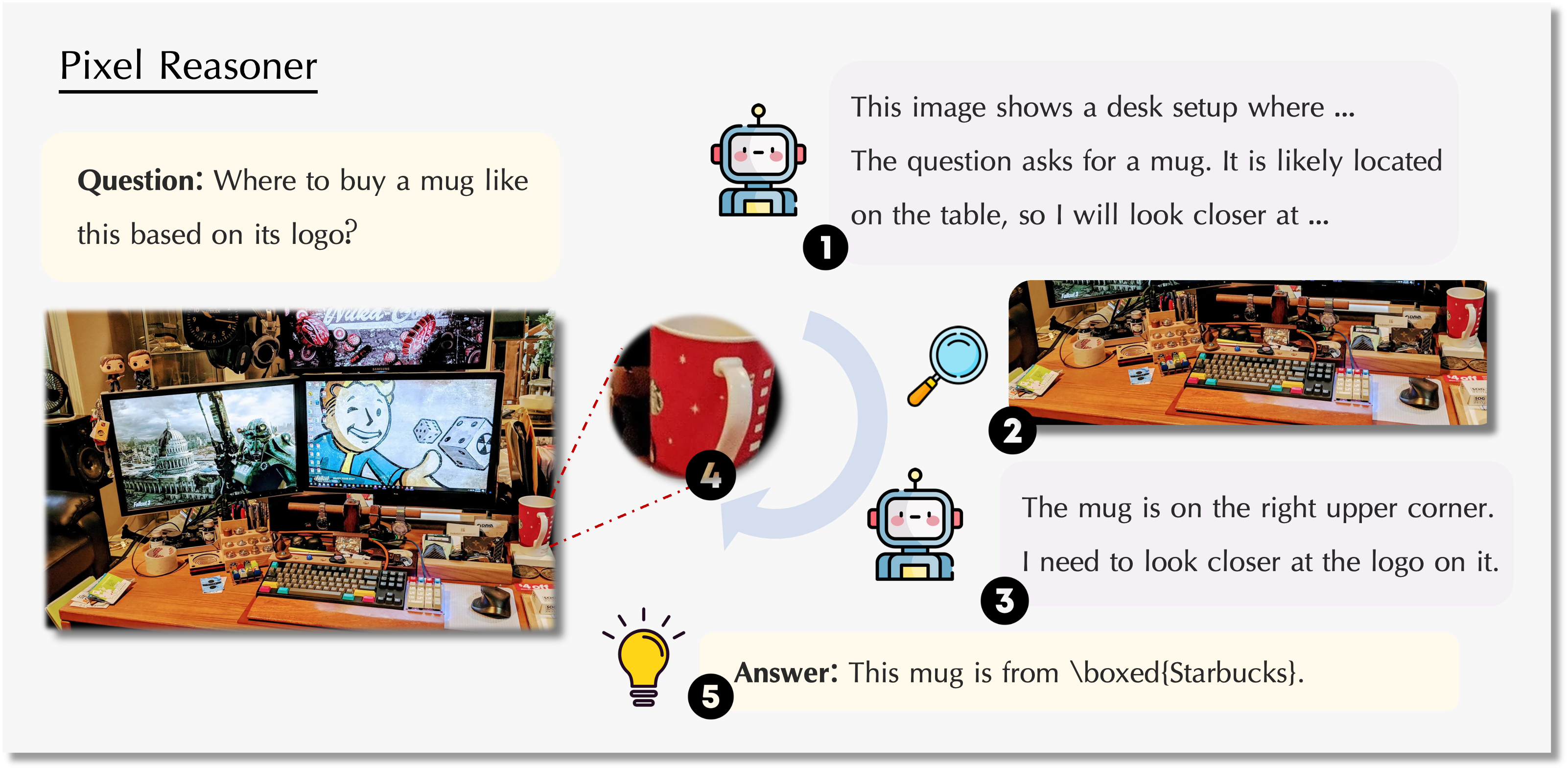 上図のように、モデルは全体像を理解できるだけでなく、拡大や選択操作で画像の細部にフォーカスし、複雑な視覚内容の理解力を高めます。
上図のように、モデルは全体像を理解できるだけでなく、拡大や選択操作で画像の細部にフォーカスし、複雑な視覚内容の理解力を高めます。
トレーニングの課題と革新的な仕組み
モデルのトレーニング過程で、従来の視覚言語モデルはピクセルレベル推論において「学習の落とし穴」に陥ることが判明しました。テキスト推論には長けているものの、ピクセルレベルの操作では失敗しやすく、視覚的な操作を積極的に探求する動機が不足しています。
 上図はピクセル空間推論の初期段階で直面するボトルネックを示しています。初期能力が不十分なため、モデルは視覚的な操作を回避しがちで、ピクセルレベル推論能力の育成が妨げられます。
上図はピクセル空間推論の初期段階で直面するボトルネックを示しています。初期能力が不十分なため、モデルは視覚的な操作を回避しがちで、ピクセルレベル推論能力の育成が妨げられます。
この課題に対処するため、Pixel-Reasonerは好奇心駆動型の強化学習メカニズムを採用し、モデルがピクセルレベルの操作を積極的に試みることで報酬を与え、視覚空間での推論能力を段階的に向上させます。
データ合成とトレーニングプロセス
Pixel-Reasonerのトレーニングは2段階に分かれます:
- 指示によるファインチューニング:視覚操作を含む合成推論軌跡で、モデルがさまざまなピクセルレベルの操作に慣れるようにします。
- 好奇心駆動型強化学習:報酬メカニズムを導入し、推論過程でモデルが視覚操作を積極的に探求・活用するよう促します。
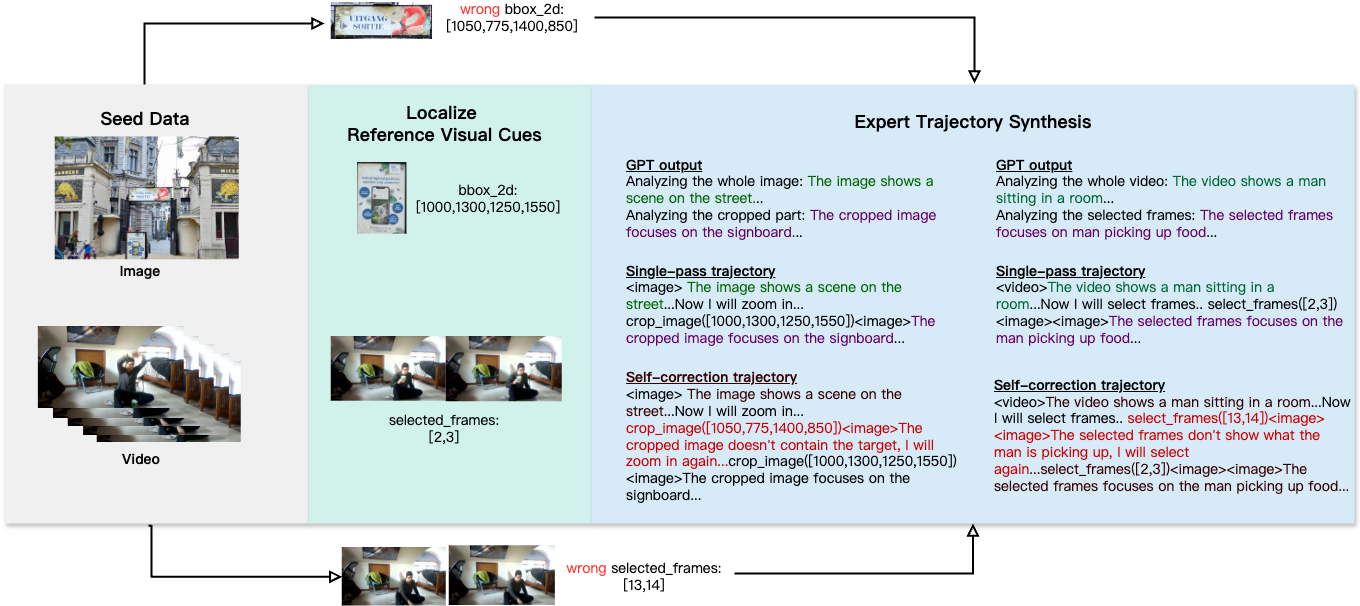 上図のように、チームは高解像度の画像や動画を自動・手動アノテーションと組み合わせ、多様な推論データを生成し、モデルが視覚空間で分析や自己修正を学べるようにしています。
上図のように、チームは高解像度の画像や動画を自動・手動アノテーションと組み合わせ、多様な推論データを生成し、モデルが視覚空間で分析や自己修正を学べるようにしています。
主な活用シーン
Pixel-Reasonerは特に以下のような場面に適しています:
- 画像内の小さな物体や細部を識別する必要があるタスク
- 複雑な画像や動画で複数領域・多層情報を理解するタスク
- 全体と部分の情報を組み合わせた視覚推論タスク
活用シーン
Pixel-Reasonerは、詳細な視覚理解が求められるシーンに最適です。例えば:
- 複雑な画像や動画コンテンツの分析
- 小さな物体、微細な関係、埋め込まれた文字の認識
- 全体と部分の情報を組み合わせた視覚タスク
関連リンク
- 論文: https://arxiv.org/abs/2505.15966
- 公式サイト: https://tiger-ai-lab.github.io/Pixel-Reasoner/
- HuggingFaceモデル: https://huggingface.co/TIGER-Lab/PixelReasoner-RL-v1
- オンラインデモ: https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
本記事の内容はPixel-Reasoner公式資料および論文を参考にしています。
コメント
GitHubでサインインしてディスカッションに参加しましょう。