Sand AI、MAGI-1をリリース:大規模自己回帰型動画生成モデル
Sand AIは、チャンク単位で動画を生成する自己回帰型モデルMAGI-1をオープンソース化し、24Bおよび4.5Bパラメータバージョンを提供、複数の動画生成モードをサポート
Sand AIチームは4月21日にMAGI-1動画生成モデルを正式にオープンソース化し、4月末までに4.5Bパラメータバージョンをリリースする予定です。これは動画チャンクシーケンスを自己回帰的に予測できるワールドモデルで、テキストから動画(T2V)、画像から動画(I2V)、動画から動画(V2V)などの生成方法をサポートしています。
技術革新
MAGI-1は、動画生成分野で独自の優位性を持つ複数の技術革新を採用しています:
TransformerベースのVAE
- 8倍の空間圧縮と4倍の時間圧縮を実現するTransformerベースの変分オートエンコーダを使用
- 高品質な再構成を維持しながら最速の平均デコード時間を実現
自己回帰型ノイズ除去アルゴリズム
MAGI-1は、一度にすべてを生成するのではなく、自己回帰的にチャンク単位で動画を生成します。各チャンク(24フレーム)は全体的にノイズ除去され、現在のチャンクが一定レベルのノイズ除去に達するとすぐに次のチャンクの生成が開始されます。この設計により、効率的な動画生成のために最大4つのチャンクの同時処理が可能になります。

拡散モデルアーキテクチャ
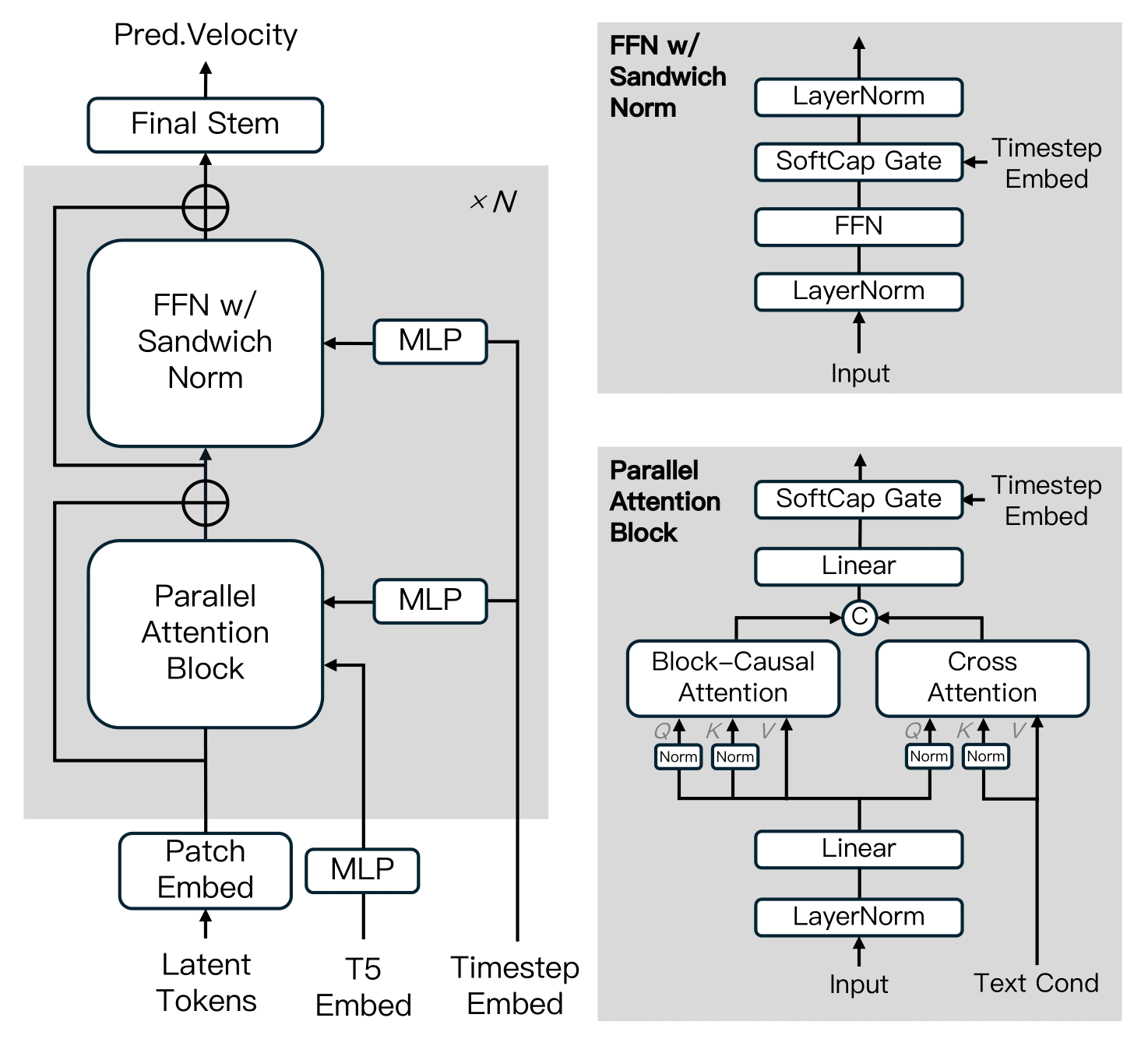
MAGI-1は拡散トランスフォーマーをベースに構築され、大規模なトレーニング効率と安定性を向上させるいくつかの重要な革新を取り入れています。これらの進化には、ブロック因果注意機構、並列注意ブロック、QK正規化とGQA、FFNにおけるサンドイッチ正規化、SwiGLU、ソフトキャップ変調などが含まれます。
蒸留アルゴリズム
このモデルは、様々な推論予算をサポートするために単一の速度ベースモデルを訓練するショートカット蒸留アプローチを採用しています。自己一貫性制約(1つの大きなステップを2つの小さなステップと等価にする)を適用することで、モデルは複数のステップサイズにわたるフローマッチング軌道を近似することを学習します。トレーニング中、ステップサイズは64、32、16、8から周期的にサンプリングされ、条件付き整列を維持するためにクラス分類器フリーガイダンス蒸留が組み込まれています。これにより、忠実度の損失を最小限に抑えながら効率的な推論が可能になります。
モデルバージョン
Sand AIはMAGI-1の複数バージョンの事前訓練済み重みを提供しており、24Bおよび4.5Bモデル、ならびに対応する蒸留モデルと量子化モデルが含まれます:
| モデル | 推奨ハードウェア | |
-- |
- | | MAGI-1-24B | H100/H800 × 8 | | MAGI-1-24B-distill | H100/H800 × 8 | | MAGI-1-24B-distill+fp8_quant | H100/H800 × 4 または RTX 4090 × 8 | | MAGI-1-4.5B | RTX 4090 × 1 |
パフォーマンス評価
物理評価
自己回帰アーキテクチャの自然な利点により、MAGI-1はPhysics-IQベンチマークにおいて動画継続を通じて物理的挙動の予測に非常に優れた精度を達成しています。
Physics-IQスコアにおいて、MAGIの動画から動画(V2V)モードは56.02ポイントを達成し、画像から動画(I2V)モードは30.23ポイントに達しており、VideoPoet、Kling1.6、Soraなどの他のオープンソースおよびクローズドソースの商用モデルを大幅に上回っています。
実行方法
MAGI-1はDocker環境(推奨)またはソースコードを通じた実行をサポートしています。ユーザーはrun.shスクリプトのパラメータを調整することで、異なる要件を満たすために入力と出力を柔軟に制御できます:
--mode:操作モードを指定(t2v、i2v、またはv2v)--prompt:動画生成に使用されるテキストプロンプト--image_path:画像ファイルのパス(i2vモードでのみ使用)--prefix_video_path:プレフィックス動画ファイルのパス(v2vモードでのみ使用)--output_path:生成された動画ファイルが保存されるパス
コメント
GitHubでサインインしてディスカッションに参加しましょう。