TTT-Video: 長時間ビデオ生成のための技術
研究者らがCogVideoX 5Bをベースにしたテスト時学習技術を用いたTTT-Videoモデルを開発し、最大63秒の一貫性のあるビデオ生成を実現
研究者たちは最近、TTT-Videoと呼ばれるオープンソースプロジェクトをリリースしました。この技術はAIビデオ生成の従来の時間的制限を超え、最大63秒の一貫性のあるビデオコンテンツを生成することができます。この技術は、革新的なTest-Time Training(テスト時学習)手法により、長時間ビデオ生成におけるコンテンツの一貫性の問題を解決しています。
ビデオ生成の主要な課題への対応
現在、ほとんどのAIビデオ生成モデルは3〜5秒の短いビデオクリップしか作成できません。これは、ビデオ生成に使用されるTransformerモデルが、自己注意機構により長いシーケンスを処理する際に計算コストが二次的に増加するため、長いビデオを効率的に処理できないためです。
TTT-Videoは革新的な方法でこの問題を解決します:元の事前学習モデルの注意層を保持して各3秒セグメントのローカルな注意に使用しながら、グローバルコンテキストの長距離関係を処理するための特別なTest-Time Training層を導入しています。
技術的実装
このプロジェクトはCogVideoX 5Bモデル(テキストからビデオを生成するための拡散Transformer)をベースにしており、主な革新点は以下の通りです:
- グローバルシーケンスとその反転バージョンを処理するTTT層の導入、ゲート付き残差接続を通じて出力を組み合わせる
- 各セグメントとテキストおよびビデオの埋め込みを交互に配置することによるコンテキストの拡張
- 段階的なトレーニング:最初に元の事前学習された3秒のビデオ長でファインチューニングし、その後9秒、18秒、30秒、63秒のビデオ長で段階的にトレーニング
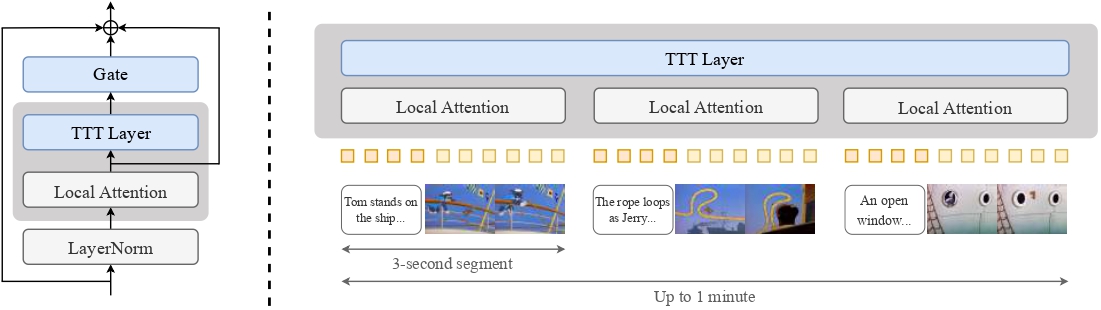
TTT-Videoモデルアーキテクチャ:TTT層を通じたグローバルシーケンスの処理とローカル注意機構の組み合わせ
研究チームは古典的なアニメーション「トムとジェリー」をテストケースとして使用し、スタイル的に一貫性があり、約1分間の連続したアニメーションビデオを生成しましたが、5Bパラメータのサイズに制限があるため、生成品質にはまだ改善の余地があります。
印象的な生成結果
<video style={{ width: '100%', maxWidth: '680px' }} src="https://test-time-training.github.io/video-dit/videos/63s-demo/homeless.mp4" controls />
TTT-Videoの最も印象的な側面は、1分間までの「トムとジェリー」スタイルのアニメーションを一度のパスで生成できることです:
- 編集、スプライシング、ポストプロセッシングが一切不要
- オリジナルのアニメーションには存在しないシーンを含む完全にオリジナルのコンテンツ
- キャラクターの行動、シーンの遷移、ストーリーラインの一貫性

TTT-Videoによって生成されたトムとジェリースタイルのアニメーションフレーム
AI制作者にとっての意義
この技術はComfyUIなどのツールを使用するAI制作者にとって以下のことを意味します:
- 将来的により長く、より物語性のあるAIビデオ生成の可能性
- ビデオ生成における一貫性と連続性の主要な問題への解決策
- 制作者が複数のセグメントを手動でスプライシングすることなく、より長いビデオコンテンツを作成できる可能性
コメント
GitHubでサインインしてディスカッションに参加しましょう。