StdGEN: 単一画像からの意味分解3Dキャラクター生成
ComfyUI Wikinews
清華大学とテンセントAI研究所が共同でStdGENを発表、単一画像から体、衣服、髪などのコンポーネントが分離された高品質な意味分解3Dキャラクターを生成する革新的パイプライン

清華大学とテンセントAI研究所の研究チームが最近、StdGEN(Semantic-Decomposed 3D Character Generation)という革新的な技術を発表しました。この技術は単一画像から意味的に分解された高品質3Dキャラクターモデルを生成することができます。この研究はコンピュータビジョン分野のトップカンファレンスであるCVPR 2025に採択されました。
技術革新
StdGENは革新的なパイプラインを通じて、三つの主要な特徴を実現しています:
- 意味分解能力: 生成された3Dキャラクターモデルは、体、衣服、髪などの意味的コンポーネントに完全に分離でき、後続の編集やカスタマイズが容易になります。
- 効率性: 単一画像から完全な3Dキャラクターへの処理がわずか3分で完了します。
- 高品質再構築: 生成された3Dモデルは細かい幾何学的詳細とテクスチャを備えています。
核心技術
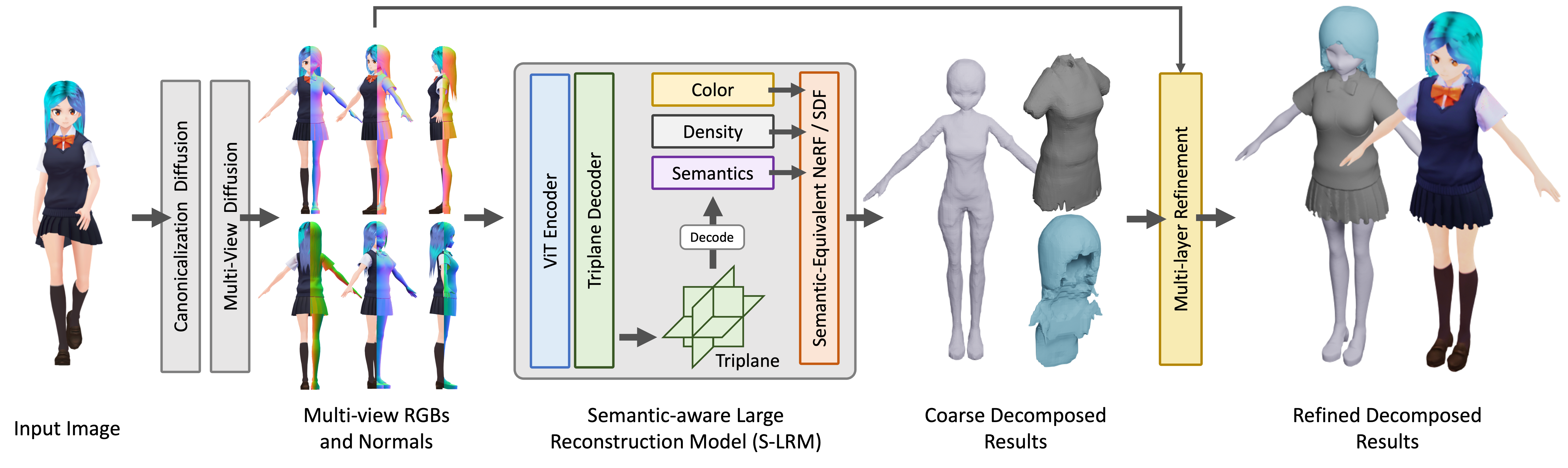 StdGENの核心は研究チームが提案した**意味認識大規模再構築モデル(S-LRM)**です。これはTransformerベースの汎用モデルで、マルチビュー画像から幾何学、色、意味情報をフィードフォワード方式で共同再構築することができます。
StdGENの核心は研究チームが提案した**意味認識大規模再構築モデル(S-LRM)**です。これはTransformerベースの汎用モデルで、マルチビュー画像から幾何学、色、意味情報をフィードフォワード方式で共同再構築することができます。
さらに、この方法は以下の革新を導入しています:
- S-LRMによって再構築されたハイブリッド暗黙場からメッシュを取得するための微分多層意味表面抽出スキーム
- 特化した効率的なマルチビュー拡散モデル
- 反復多層表面洗練モジュール
応用展望
この技術は仮想現実、ゲーム開発、映画制作などの分野で幅広い応用展望があります。既存の手法と比較して、StdGENは幾何学、テクスチャ、分解可能性の面で顕著な改善を達成し、ユーザーに柔軟なカスタマイズをサポートする即時使用可能な意味分解3Dキャラクターを提供します。
研究チームは推論コード、データセット、事前訓練済みチェックポイントをオープンソース化し、HuggingFace Gradioによるオンラインデモも提供しています。
コメント
GitHubでサインインしてディスカッションに参加しましょう。