Alibaba がACE++をオープンソース化:トレーニング不要のキャラクター一貫性画像生成
アリババ研究所が画像生成ツールACE++をオープンソース化。コンテキスト認識コンテンツ充填技術により、単一入力からキャラクター一貫性のある新しい画像を生成し、オンライン体験と3種類の専用モデルを提供。
2025年2月10日 — アリババ研究所は、次世代AI画像ツールACE++のオープンソース化を正式に発表しました。革新的なコンテキスト認識コンテンツ充填アルゴリズムに基づき、ユーザーは単一の入力画像からキャラクター特徴の高い一貫性を持つ新しい画像を生成でき、オンライン体験とローカル展開をサポートします。
核心技術革新
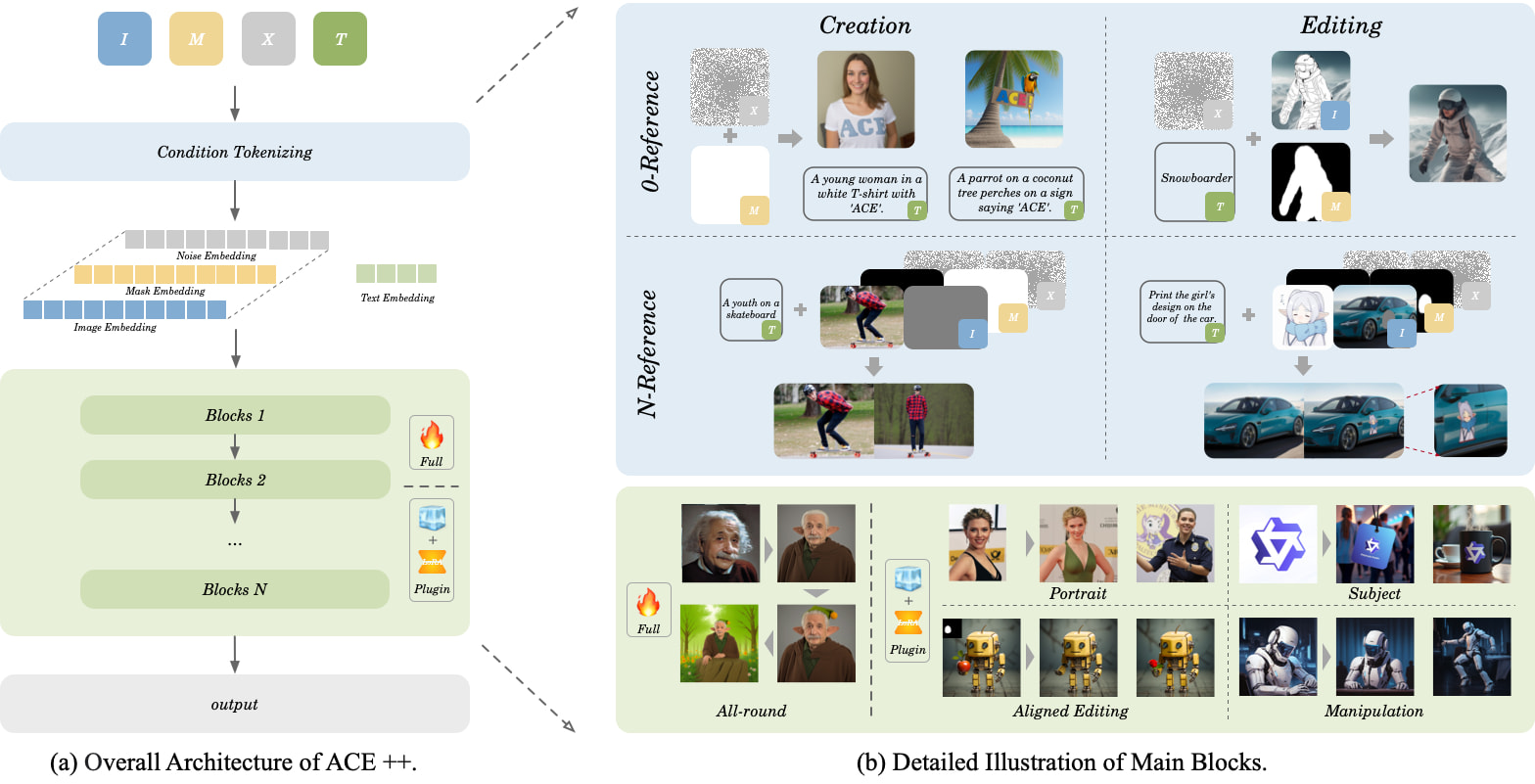
主要特徴
- ゼロトレーニング生成:FLUX.1-Fill-dev基本モデルを活用し、LoRA適応によりトレーニング不要の展開を実現
- マルチモーダル編集:
- キャラクター衣装変更(服装/ヘアスタイル/アクセサリーの変更をサポート)
- シーン再構築(背景置換/オブジェクト追加・削除)
- スマート修復(欠陥除去/品質向上)
- 意味理解:「コーヒーカップに蒸気を追加し、木製テーブルに配置」などの複合指示を解析可能
技術的ブレークスルー
- 長期コンテキストユニット(LCU):画像コンテンツ、テキスト指示、編集領域を同時処理
- 動的注意機構:512×512解像度で92.3%の特徴保持率を達成
- 二段階最適化:基本修復能力と専門編集スキルを組み合わせた段階的トレーニングアプローチ
アプリケーションシナリオテスト
|  |
|  |
|
|
|
-|
-|
|  |
|  |
|
典型的なアプリケーション
-
バーチャルモデル衣装変更
- 平面衣装画像からマルチアングル表示を生成
- 肌色/体型/シーンの動的調整をサポート
-
映画キャラクターデザイン
- クロススタイル変換を実現(リアル→ディズニー/サイバーパンク)
- キャラクター特徴の連続性を保持したマルチシーン生成
-
スマート画像修復
- 古い写真の4K解像度再構築
- 複雑な遮蔽物のシームレスな除去
リソースアクセスチャネル
| | |
|
-|
-|
| | |
公式エントリー
| リソースタイプ | アクセスリンク | |
--|
-| | プロジェクトホームページ | https://ali-vilab.github.io/ACE_plus_page/ | | コードリポジトリ | GitHub | | オンライン体験 | ModelScope |
公式モデルダウンロードリンク
専用適応モデル
| モデルタイプ | ファイル名 | ModelScope ダウンロード | HuggingFace ダウンロード | |
|
--|
-|
| | ポートレート生成 | comfyui_portrait_lora64.safetensors | Portraitモデル | Portraitモデル | | オブジェクト転送 | comfyui_subject_lora16.safetensors | Subjectモデル | Subjectモデル | | ローカル編集 | comfyui_local_lora16.safetensors | LocalEditingモデル | LocalEditingモデル |
基本依存モデル
| モデル名 | ダウンロードチャネル | |
|
--| | FLUX.1-Fill-dev | HuggingFaceダウンロード | | Flux-Fill FP8 | CivitAIダウンロード |
技術開発展望
現在のバージョンは、複雑なオブジェクト処理(手の細部精度62.3%)と中国語テキストサポートにおいてまだ改善の余地があります。開発チームは2025年第3四半期にビデオ連続フレーム編集機能をリリースし、年末までに完全版ACE++ Fullyモデルをリリースする計画を明らかにしています。
ワークフローファイルはComfyUI Wikiテスト後のコンテンツ更新をお待ちください ワークフロー更新を見る
コメント
GitHubでサインインしてディスカッションに参加しましょう。