OmniAvatar: Lanzamiento de un Modelo Eficiente de Generación de Videos de Humanos Virtuales Controlados por Audio
El modelo OmniAvatar ahora es de código abierto, permitiendo la generación de videos de humanos virtuales de cuerpo completo controlados por audio con movimientos naturales y expresiones ricas, adecuado para podcasts, interacciones, escenas dinámicas y diversas aplicaciones.
OmniAvatar es un proyecto de código abierto desarrollado conjuntamente por la Universidad de Zhejiang y el Grupo Alibaba (lanzado en junio de 2025). Es un modelo de generación de videos de humanos digitales de cuerpo completo controlado por audio que crea videos de humanos virtuales naturales y fluidos a través de una sola imagen de referencia, entrada de audio y indicaciones de texto. Admite sincronización labial precisa, control de movimiento de cuerpo completo e interacción multi-escena, marcando un avance significativo en la tecnología de humanos digitales.
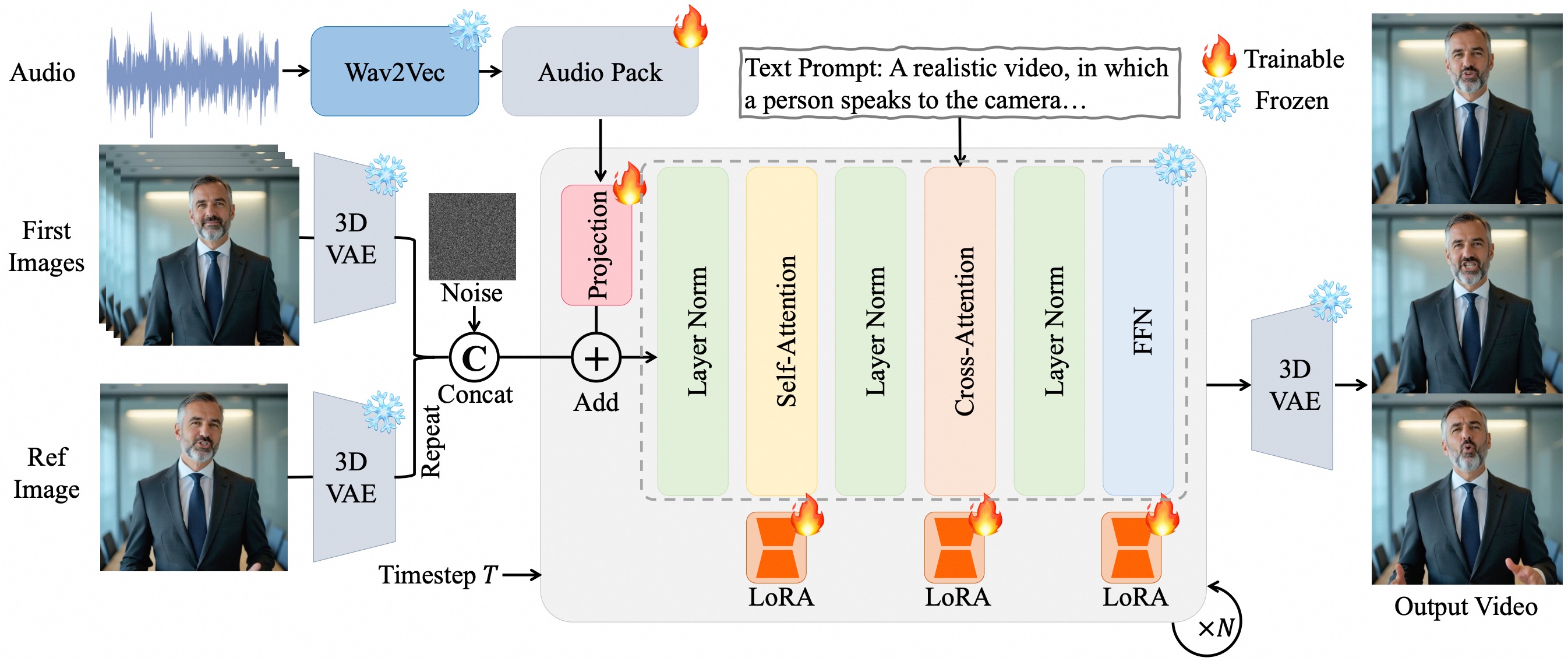
I. Principios Técnicos Centrales
Incrustación de Audio Multicapa a Nivel de Píxel
- Utiliza Wav2Vec2 para extraer características de audio, alineando las características de voz al espacio latente del video píxel por píxel a través del módulo Audio Pack, incrustando información de audio a través de múltiples capas temporales en el modelo de difusión (DiT).
- Ventajas: Logra sincronización labial a nivel de fotograma (como expresiones sutiles desencadenadas por palabras aspiradas) y coordinación de movimiento de cuerpo completo (como movimientos de hombros y ritmos de gestos), con mayor precisión de sincronización que los modelos convencionales.
Estrategia de Ajuste Fino LoRA
- Inserta matrices de adaptación de bajo rango (LoRA) en las capas de atención del Transformer y las capas de red feed-forward, ajustando solo los parámetros adicionales mientras mantiene las capacidades del modelo base.
- Efectos: Previene el sobreajuste, mejora la estabilidad de alineación audio-video y admite control detallado a través de indicaciones de texto (como amplitud de gestos y expresión emocional).
Mecanismo de Generación de Videos Largos
- Incorpora codificación latente de imagen de referencia como anclas de identidad, combinada con estrategia de superposición de fotogramas y algoritmos de generación progresiva para mitigar problemas de deriva de color e inconsistencia de identidad en videos largos.
II. Características Principales e Innovaciones
Generación de Movimiento de Cuerpo Completo
- Supera la limitación tradicional de "movimiento solo de cabeza", generando movimientos corporales naturales y coordinados (como saludar, brindar, bailar).
Capacidades de Control Multimodal
- Control por Indicaciones de Texto: Ajusta con precisión acciones (como "celebración brindando"), fondos (como "estudio en vivo estrellado") y emociones (como "alegría/enojo") a través de descripciones.
- Interacción con Objetos: Admite la interacción del humano virtual con objetos de la escena (como demostraciones de productos), mejorando el realismo en marketing de comercio electrónico.
Soporte Multilingüe y de Videos Largos
- Admite adaptación de sincronización labial para 31 idiomas incluyendo chino, inglés y japonés, capaz de generar videos coherentes de más de 10 segundos (requiere dispositivos con alta VRAM).
III. Ricas Demostraciones en Video
El sitio web oficial de OmniAvatar proporciona numerosas demostraciones reales que cubren varios escenarios y capacidades de control. Aquí hay videos seleccionados:
1. Movimiento y Expresiones de Cuerpo Completo del Orador
2. Acciones Diversas y Expresiones Emocionales
3. Interacción Humano-Objeto
4. Control de Fondo y Escena
5. Expresión Emocional
6. Escenarios de Podcast y Canto
Para más demostraciones, visite el Sitio Web Oficial de OmniAvatar
IV. Código Abierto y Ecosistema
- Repositorio de Código Abierto: GitHub - OmniAvatar
- Descarga del Modelo: HuggingFace - OmniAvatar-14B
- Artículo de Investigación: arXiv:2506.18866
Contenido referenciado del Sitio Web Oficial de OmniAvatar, GitHub, y materiales de código abierto relacionados.
Comentarios
Inicia sesión con GitHub para unirte a la conversación.