Lanzamiento de XVerse: Un Modelo de Generación de Imágenes de Alta Consistencia con Control de Identidad Multi-sujeto y Atributos Semánticos
ByteDance libera el código del modelo XVerse, permitiendo un control preciso e independiente de múltiples identidades de sujetos y atributos semánticos (como pose, estilo, iluminación), mejorando las capacidades de personalización y escenas complejas en la generación de imágenes por IA.
XVerse es un modelo controlable de generación de imágenes multi-sujeto liberado como código abierto por el equipo de IA Creativa de ByteDance en 2025. Se enfoca en resolver el desafío del control preciso e independiente de múltiples objetos (como personas, animales, objetos) en imágenes generadas por IA. El modelo soporta el ajuste detallado y no interferente de identidad, pose, estilo, iluminación y otros atributos para múltiples sujetos en una imagen, mejorando significativamente las capacidades de generación para escenas personalizadas y complejas.

I. Capacidades Principales e Innovaciones
- Control Multi-sujeto Independiente: Controla con precisión la identidad, acciones y estilo de múltiples sujetos simultáneamente, evitando el problema común de "entrelazamiento de atributos" en métodos tradicionales.
- Alta Fidelidad y Preservación de Detalles: Preserva detalles como mechones de cabello y texturas a través de la codificación de características de imagen VAE, reduciendo artefactos y distorsión.
- Edición Flexible de Atributos Semánticos: Soporta el ajuste flexible de atributos no relacionados con la identidad como iluminación y estilo artístico, manteniendo las características del sujeto durante las transiciones de escena.
- Alta Consistencia y Estabilidad: Mecanismo innovador de modulación de flujo de texto y doble regularización (pérdida de protección de región, pérdida de atención texto-imagen) aseguran la estabilidad y consistencia en la generación.
II. Descripción General de Principios Técnicos
1. Mecanismo de Modulación de Flujo de Texto (Adaptador T-Mod)
- Convierte imágenes de referencia en desplazamientos de incrustación de texto, logrando un control preciso e independiente de múltiples sujetos a través de señales de control en capas (compartición global + modulación por bloques).
- El adaptador T-Mod integra características de imagen CLIP con indicaciones de texto, generando señales de modulación cruzada para evitar la confusión de características.
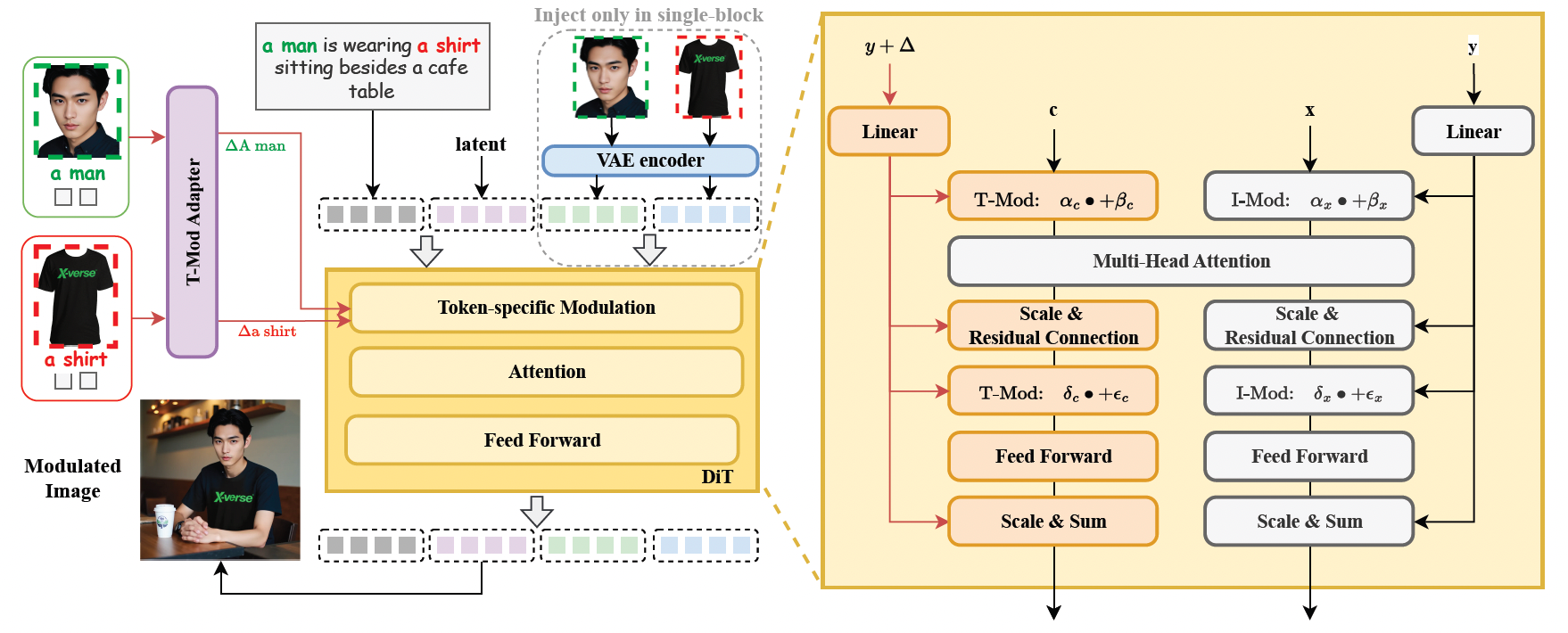
2. Módulo de Codificación de Características de Imagen VAE
- Introduce características codificadas VAE en la estructura FLUX para mejorar la preservación de detalles, haciendo que las imágenes generadas sean más realistas y naturales.
3. Mecanismo de Doble Regularización
- Pérdida de Protección de Región: Preserva aleatoriamente ciertas regiones de la modulación para asegurar que los objetos no objetivo permanezcan sin perturbaciones.
- Pérdida de Atención Texto-Imagen: Optimiza la asignación de atención para mejorar la precisión del alineamiento semántico.
III. Datos de Entrenamiento y Puntos de Referencia de Evaluación
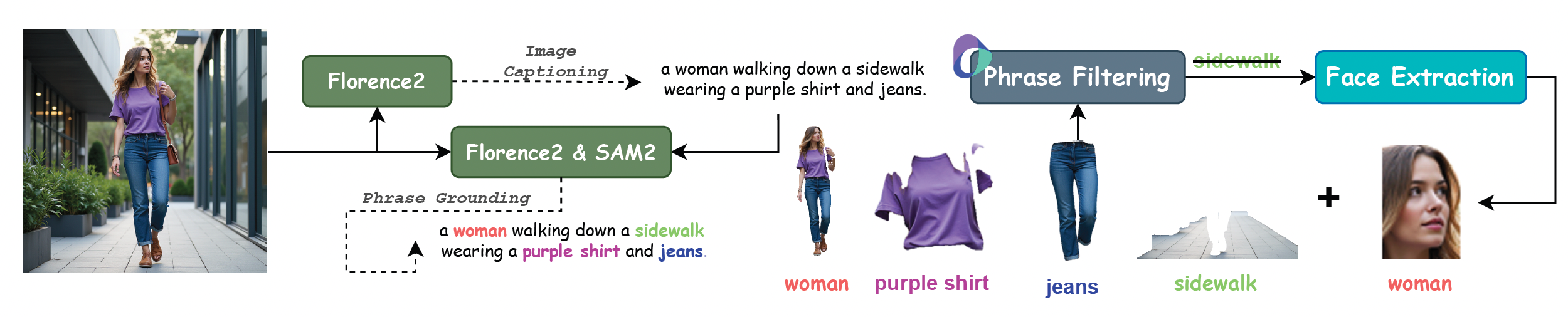
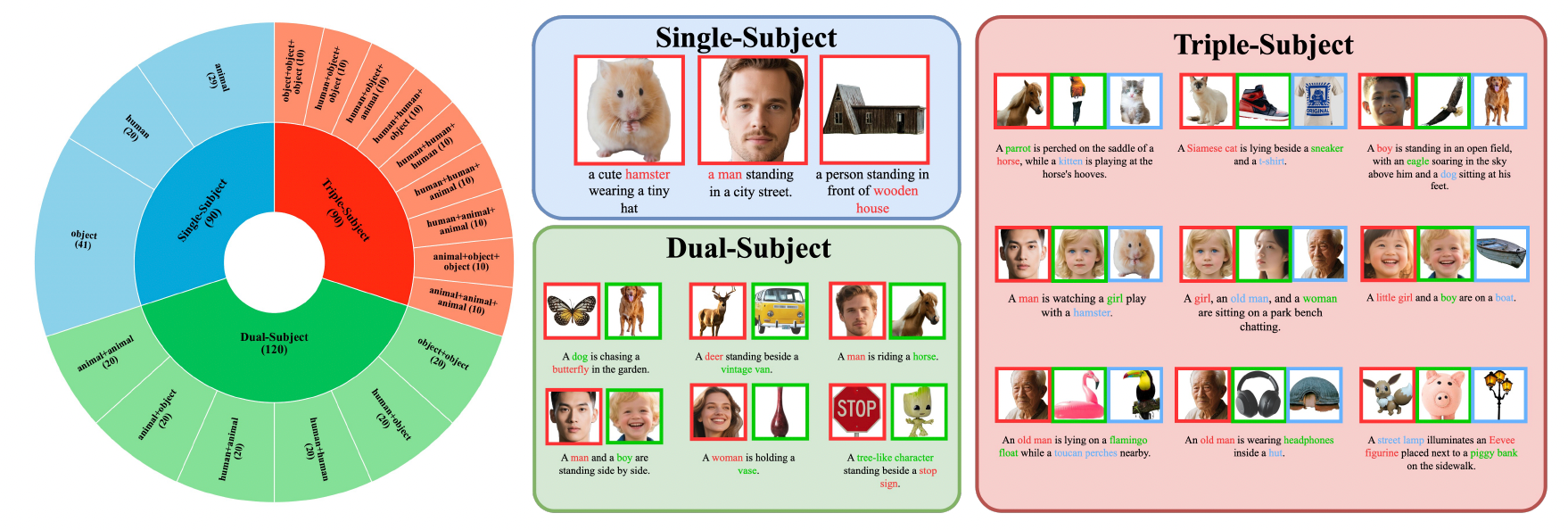
XVerse utiliza un conjunto de datos de control multi-sujeto de alta calidad que cubre 20 tipos de personas, 74 tipos de elementos y 45 tipos de animales, sintetizando millones de imágenes de alta calidad estética.
El rendimiento del modelo supera significativamente métodos similares en el punto de referencia XVerseBench, soportando varios escenarios de control incluyendo sujetos individuales, dobles y triples.
| Métrica | Significado | | | | | Puntuación DPG | Capacidad de Edición | | Similitud de ID Facial | Consistencia de Identidad de Persona | | Similitud DINOv2 | Consistencia de Características de Objeto | | Puntuación Estética | Calidad Estética de la Imagen |
IV. Resultados Experimentales y Estudios de Caso
1. Control Preciso de Identidad y Atributos de Sujeto Individual
XVerse mantiene la consistencia de identidad del sujeto a través de diversos escenarios mientras ajusta flexiblemente la pose, vestimenta, entorno y otros atributos.





2. Consistencia Multi-sujeto y Control Independiente
XVerse logra el control independiente de múltiples identidades de sujetos y atributos dentro de la misma imagen mientras mantiene la interacción natural y la consistencia de la escena.





3. Control Flexible de Atributos Semánticos
XVerse soporta el ajuste detallado de atributos semánticos como iluminación, pose y estilo para satisfacer diversas necesidades creativas.

V. Código Abierto y Recursos Relacionados
- Página del Proyecto: https://bytedance.github.io/XVerse/
- Repositorio GitHub: https://github.com/bytedance/XVerse
- Descarga del Modelo: https://huggingface.co/ByteDance/XVerse
- Documento Técnico: https://arxiv.org/abs/2506.21416
Contenido referenciado de Página Oficial de XVerse, GitHub, y materiales relacionados de código abierto.
Comentarios
Inicia sesión con GitHub para unirte a la conversación.