Pixel-Reasoner: Lanzamiento del modelo de razonamiento visual a nivel de píxel de código abierto
Pixel-Reasoner, basado en Qwen2, ofrece comprensión y razonamiento visual a nivel de píxel tanto global como local, admite análisis detallados con zoom y promueve avances en modelos de lenguaje visual.
Pixel-Reasoner es un modelo de lenguaje visual de código abierto basado en Qwen2, enfocado en mejorar la comprensión y el razonamiento visual a nivel de píxel. El modelo puede analizar imágenes de manera global y también permite hacer zoom en áreas locales para observar detalles, ayudando a captar información fina en las imágenes.
Características principales
- Razonamiento a nivel de píxel: Pixel-Reasoner puede razonar directamente en el espacio de los píxeles de la imagen, sin limitarse al razonamiento tradicional basado en texto.
- Combinación de comprensión global y local: El modelo puede captar el contenido general de la imagen y también "acercarse" para analizar áreas específicas con mayor detalle.
- Entrenamiento impulsado por la curiosidad: Mediante un mecanismo de recompensa por curiosidad, se anima al modelo a explorar y utilizar operaciones a nivel de píxel, mejorando la diversidad y precisión del razonamiento visual.
- Código abierto disponible: El modelo, los conjuntos de datos y el código relacionado son de código abierto, lo que facilita a la comunidad su descarga y prueba.
Nuevo paradigma de razonamiento a nivel de píxel
Pixel-Reasoner introduce el nuevo concepto de "Razonamiento en el espacio de píxeles". A diferencia de los modelos de lenguaje visual tradicionales que solo dependen del razonamiento textual, Pixel-Reasoner puede analizar y operar directamente en el nivel de los píxeles de la imagen.
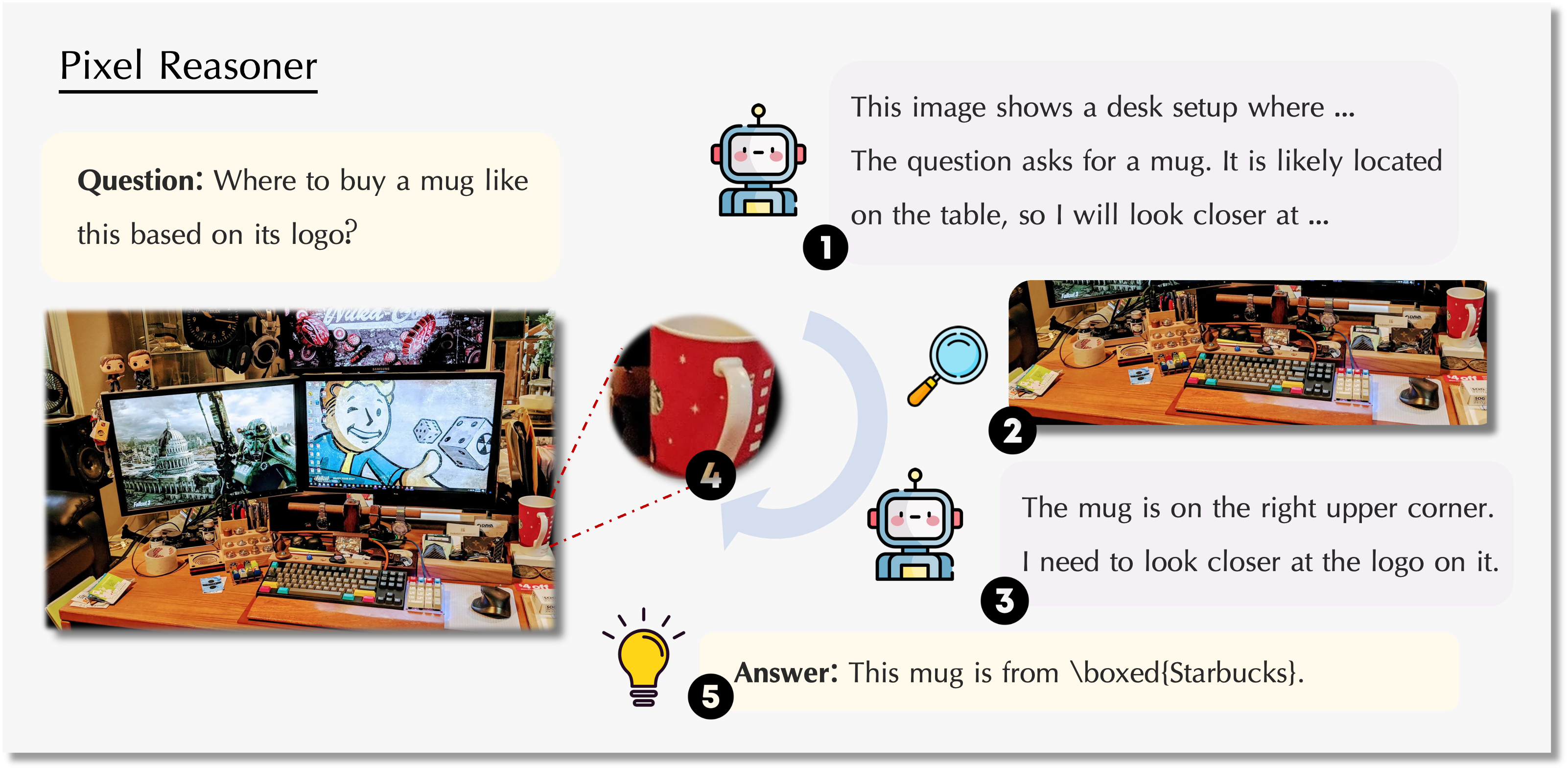 Como se muestra arriba, el modelo puede comprender la imagen completa y también acercarse o seleccionar áreas para centrarse en los detalles, mejorando su capacidad para entender contenido visual complejo.
Como se muestra arriba, el modelo puede comprender la imagen completa y también acercarse o seleccionar áreas para centrarse en los detalles, mejorando su capacidad para entender contenido visual complejo.
Retos de entrenamiento y mecanismos innovadores
Durante el entrenamiento, el equipo descubrió que los modelos de lenguaje visual existentes enfrentan una "trampa de aprendizaje" en el razonamiento a nivel de píxel: son mejores en el razonamiento textual y tienden a fallar en las operaciones a nivel de píxel, careciendo de motivación para explorar acciones visuales.
 La imagen anterior muestra el cuello de botella encontrado en las primeras etapas del razonamiento en el espacio de píxeles: debido a la capacidad inicial limitada, el modelo tiende a evitar operaciones visuales, lo que afecta el desarrollo de habilidades de razonamiento a nivel de píxel.
La imagen anterior muestra el cuello de botella encontrado en las primeras etapas del razonamiento en el espacio de píxeles: debido a la capacidad inicial limitada, el modelo tiende a evitar operaciones visuales, lo que afecta el desarrollo de habilidades de razonamiento a nivel de píxel.
Para abordar esto, Pixel-Reasoner utiliza un mecanismo de aprendizaje por refuerzo impulsado por la curiosidad, recompensando al modelo por intentar activamente operaciones a nivel de píxel y mejorando gradualmente su capacidad de razonamiento en el espacio visual.
Síntesis de datos y proceso de entrenamiento
El entrenamiento de Pixel-Reasoner se divide en dos etapas:
- Ajuste fino por instrucciones: Trayectorias de razonamiento sintéticas con operaciones visuales ayudan al modelo a familiarizarse con diversas acciones a nivel de píxel.
- Aprendizaje por refuerzo impulsado por la curiosidad: Un mecanismo de recompensa anima al modelo a explorar y utilizar activamente operaciones visuales durante el razonamiento.
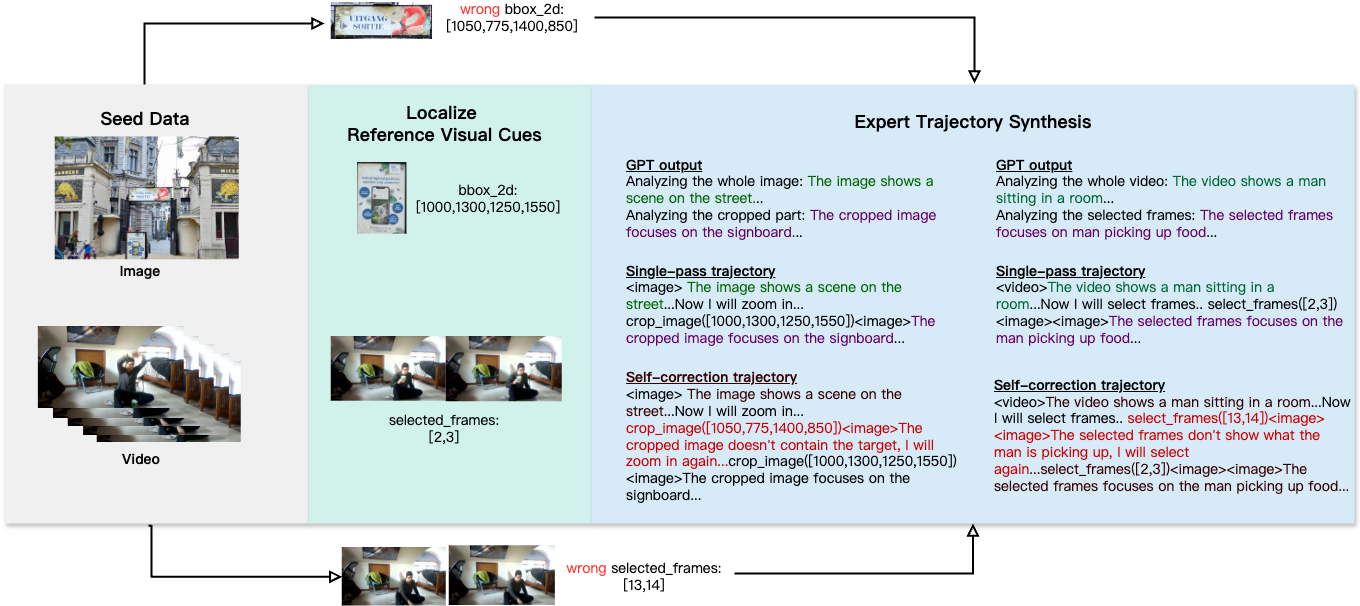 Como se muestra arriba, el equipo utiliza imágenes y videos de alta resolución, combinados con anotaciones automáticas y manuales, para generar datos de razonamiento diversos, ayudando al modelo a aprender a analizar y autocorregirse en el espacio visual.
Como se muestra arriba, el equipo utiliza imágenes y videos de alta resolución, combinados con anotaciones automáticas y manuales, para generar datos de razonamiento diversos, ayudando al modelo a aprender a analizar y autocorregirse en el espacio visual.
Escenarios de aplicación típicos
Pixel-Reasoner es especialmente adecuado para:
- Tareas que requieren identificar objetos pequeños o detalles en imágenes
- Comprender información de múltiples regiones y niveles en imágenes o videos complejos
- Tareas de razonamiento visual que combinan información global y local
Escenarios de aplicación
Pixel-Reasoner es ideal para escenarios que requieren comprensión visual detallada, como:
- Análisis de contenido complejo de imágenes o videos
- Reconocimiento de objetos pequeños, relaciones sutiles o texto incrustado
- Tareas visuales que combinan información global y local
Enlaces relacionados
- Artículo: https://arxiv.org/abs/2505.15966
- Página oficial: https://tiger-ai-lab.github.io/Pixel-Reasoner/
- Modelo en HuggingFace: https://huggingface.co/TIGER-Lab/PixelReasoner-RL-v1
- Demostración en línea: https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
El contenido de este artículo se basa en materiales y artículos oficiales de Pixel-Reasoner.
Comentarios
Inicia sesión con GitHub para unirte a la conversación.