Sand AI lanza MAGI-1: Generación autorregresiva de vídeos a escala
Sand AI ha lanzado como código abierto MAGI-1, un modelo autorregresivo que genera vídeos por fragmentos, ofreciendo versiones de 24B y 4.5B parámetros y admitiendo múltiples modos de generación de vídeo
El equipo de Sand AI lanzó oficialmente como código abierto el modelo de generación de vídeos MAGI-1 el 21 de abril, con planes para lanzar una versión de 4.5B parámetros a finales de abril. Este es un modelo mundial capaz de predecir secuencias de fragmentos de vídeo de forma autorregresiva, compatible con métodos de generación de Texto a Vídeo (T2V), Imagen a Vídeo (I2V) y Vídeo a Vídeo (V2V).
Innovaciones técnicas
MAGI-1: emplea múltiples innovaciones técnicas que le otorgan ventajas únicas en el campo de la generación de vídeos:
VAE basado en Transformer
- Utiliza un autocodificador variacional basado en Transformer con compresión espacial 8x y temporal 4x
- Presenta el tiempo de decodificación promedio más rápido mientras mantiene una reconstrucción de alta calidad
Algoritmo de eliminación de ruido autorregresivo
MAGI-1 genera vídeos de manera autorregresiva, fragmento por fragmento, en lugar de hacerlo todo a la vez. Cada fragmento (24 fotogramas) se elimina el ruido de forma holística, y la generación del siguiente fragmento comienza tan pronto como el actual alcanza cierto nivel de eliminación de ruido. Este diseño permite el procesamiento concurrente de hasta cuatro fragmentos para una generación eficiente de vídeos.

Arquitectura del modelo de difusión
MAGI-1 se basa en el Transformador de Difusión, incorporando varias innovaciones clave para mejorar la eficiencia del entrenamiento y la estabilidad a escala. Estos avances incluyen Atención Causal por Bloques, Bloque de Atención Paralela, QK-Norm y GQA, Normalización Sándwich en FFN, SwiGLU y Modulación Softcap.
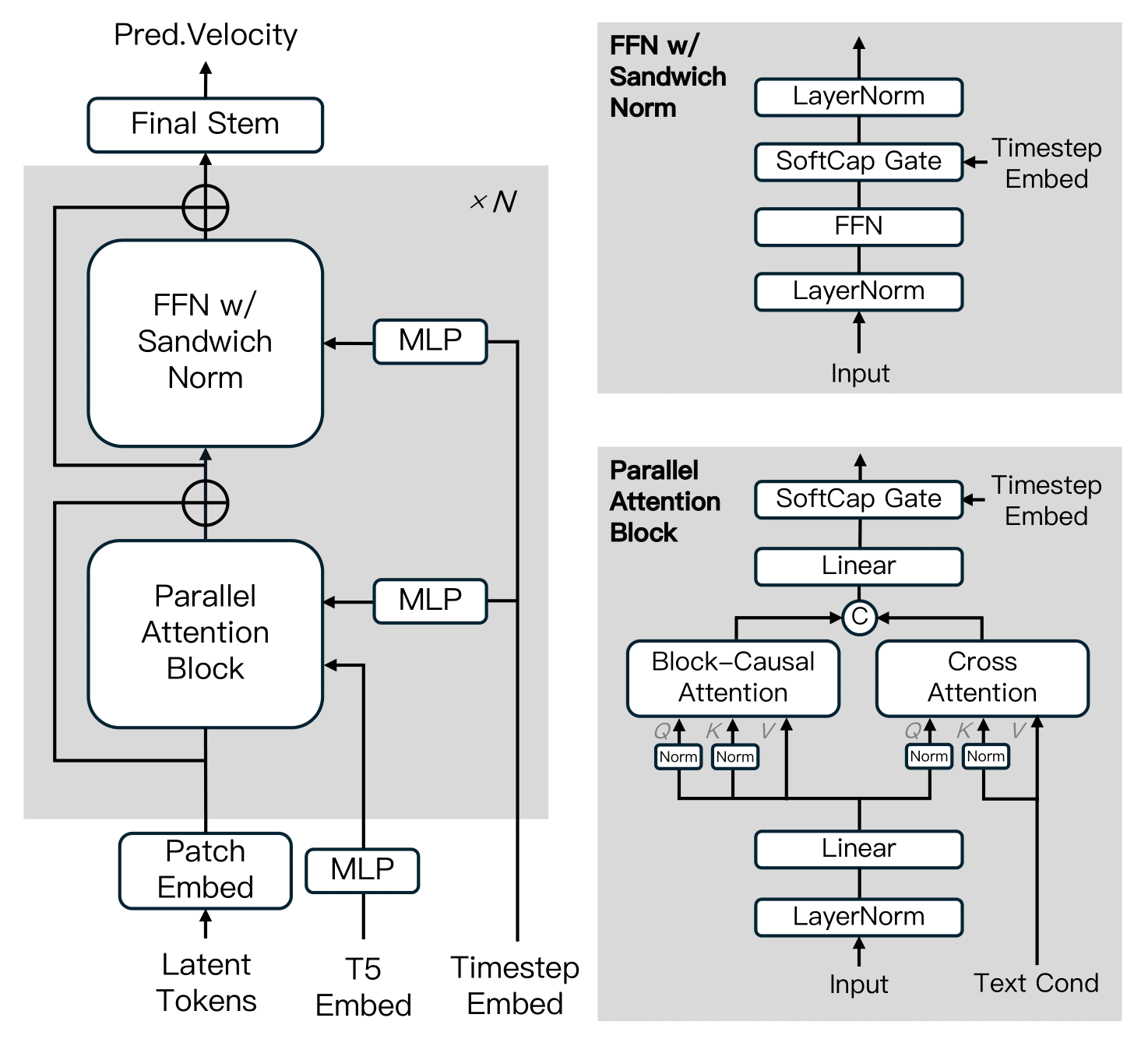
Algoritmo de destilación
El modelo adopta un enfoque de destilación por atajos que entrena un único modelo basado en velocidad para admitir presupuestos de inferencia variables. Al imponer una restricción de autoconsistencia —equiparando un paso grande con dos pasos más pequeños— el modelo aprende a aproximar trayectorias de coincidencia de flujo en múltiples tamaños de paso. Durante el entrenamiento, los tamaños de paso se muestrean cíclicamente de 64, 32, 16, 8, y se incorpora la destilación de guía sin clasificador para preservar la alineación condicional. Esto permite una inferencia eficiente con una pérdida mínima de fidelidad.
Versiones del modelo
Sand AI proporciona pesos preentrenados para múltiples versiones de MAGI-1, incluidos modelos de 24B y 4.5B, así como los correspondientes modelos destilados y cuantificados:
| Modelo | Hardware recomendado | |
-- |
- | | MAGI-1-24B | H100/H800 × 8 | | MAGI-1-24B-distill | H100/H800 × 8 | | MAGI-1-24B-distill+fp8_quant | H100/H800 × 4 o RTX 4090 × 8 | | MAGI-1-4.5B | RTX 4090 × 1 |
Evaluación de rendimiento
Evaluación física
Gracias a las ventajas naturales de la arquitectura autorregresiva, MAGI-1 logra una precisión muy superior en la predicción del comportamiento físico en el punto de referencia Physics-IQ a través de la continuación de vídeo.
En la puntuación de Physics-IQ, el modo Vídeo a Vídeo (V2V) de MAGI alcanza 56.02 puntos, mientras que su modo Imagen a Vídeo (I2V) alcanza 30.23 puntos, superando significativamente a otros modelos comerciales de código abierto y cerrado como VideoPoet, Kling1.6 y Sora.
Cómo ejecutar
MAGI-1 admite la ejecución a través del entorno Docker (recomendado) o el código fuente. Los usuarios pueden controlar de manera flexible la entrada y la salida ajustando los parámetros en el script run.sh para satisfacer diferentes requisitos:
--mode: Especifica el modo de operación (t2v, i2v o v2v)--prompt: El texto utilizado para la generación de vídeo--image_path: Ruta al archivo de imagen (utilizado solo en modo i2v)--prefix_video_path: Ruta al archivo de vídeo prefijo (utilizado solo en modo v2v)--output_path: Ruta donde se guardará el archivo de vídeo generado
Comentarios
Inicia sesión con GitHub para unirte a la conversación.