TTT-Video: Tecnología para la generación de videos largos
Investigadores desarrollan el modelo TTT-Video utilizando tecnología Test-Time Training basada en CogVideoX 5B, capaz de generar videos coherentes de hasta 63 segundos
Investigadores han lanzado recientemente un proyecto de código abierto llamado TTT-Video, una tecnología que supera las limitaciones tradicionales de tiempo en la generación de videos por IA, capaz de producir contenido de video coherente de hasta 63 segundos. Esta tecnología resuelve problemas de consistencia de contenido en la generación de videos largos mediante el innovador método Test-Time Training (Entrenamiento en Tiempo de Prueba).
Abordando desafíos clave en la generación de videos
Actualmente, la mayoría de los modelos de generación de videos por IA solo pueden crear clips cortos de 3-5 segundos. Esto se debe a que los modelos Transformer utilizados para la generación de videos tienen costos computacionales que aumentan cuadráticamente al procesar secuencias largas debido a su mecanismo de autoatención, lo que hace ineficiente procesar videos largos.
TTT-Video resuelve este problema de manera innovadora: conserva las capas de atención del modelo original preentrenado para la atención local en cada segmento de 3 segundos, mientras introduce capas especiales de Test-Time Training para manejar relaciones de larga distancia en el contexto global.
Implementación técnica
El proyecto se basa en el modelo CogVideoX 5B (un Transformer de difusión para generación de texto a video) con innovaciones clave que incluyen:
- Introducción de capas TTT para procesar la secuencia global y su versión invertida, combinando salidas mediante conexiones residuales con puertas
- Extensión del contexto intercalando cada segmento con incrustaciones de texto y video
- Entrenamiento por etapas: primero ajustando el modelo a la duración original preentrenada de 3 segundos, luego entrenando gradualmente con duraciones de 9, 18, 30 y 63 segundos
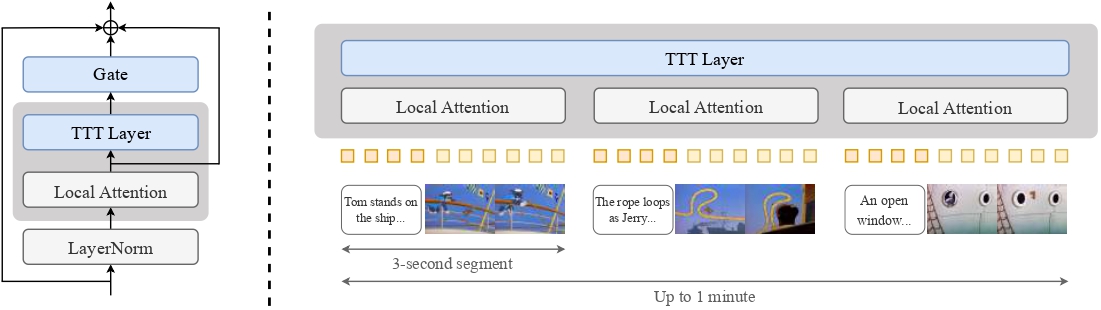
Arquitectura del modelo TTT-Video: Procesamiento de secuencias globales a través de capas TTT combinadas con mecanismos de atención local
El equipo de investigación utilizó el clásico dibujo animado "Tom y Jerry" como caso de prueba, generando videos animados estilísticamente consistentes y coherentes de aproximadamente un minuto de duración, aunque limitados por el tamaño de 5B parámetros, todavía hay margen para mejorar la calidad de generación.
Impresionantes resultados de generación
<video style={{ width: '100%', maxWidth: '680px' }} src="https://test-time-training.github.io/video-dit/videos/63s-demo/homeless.mp4" controls />
El aspecto más impresionante de TTT-Video es su capacidad para generar animaciones al estilo "Tom y Jerry" de hasta un minuto de duración en una sola pasada, con:
- Sin necesidad de edición, empalme o postprocesamiento
- Contenido completamente original, con escenas que no existen en el dibujo animado original
- Acciones de personajes, transiciones de escenas y líneas argumentales coherentes

Fotogramas de animación generados por TTT-Video en el estilo de Tom y Jerry
Importancia para creadores de IA
Esta tecnología significa lo siguiente para los creadores de IA que utilizan herramientas como ComfyUI:
- El potencial para una generación de videos de IA más larga y narrativa en el futuro
- Soluciones a problemas clave de consistencia y coherencia en la generación de videos
- La posibilidad de que los creadores creen contenido de video más largo sin necesidad de empalmar manualmente múltiples segmentos
Comentarios
Inicia sesión con GitHub para unirte a la conversación.