StdGEN: Generación de personajes 3D semánticamente descompuestos a partir de imágenes individuales
La Universidad de Tsinghua y el Laboratorio de IA de Tencent presentan conjuntamente StdGEN, un innovador sistema que genera personajes 3D de alta calidad semánticamente descompuestos a partir de imágenes individuales, permitiendo la separación del cuerpo, la ropa y el cabello

Investigadores de la Universidad de Tsinghua y el Laboratorio de IA de Tencent han lanzado recientemente StdGEN (Semantic-Decomposed 3D Character Generation), una tecnología innovadora capaz de generar modelos de personajes 3D semánticamente descompuestos de alta calidad a partir de imágenes individuales. Esta investigación ha sido aceptada por la prestigiosa conferencia de visión por computadora CVPR 2025.
Innovaciones técnicas
StdGEN implementa tres características clave a través de su innovador sistema:
- Descomposición semántica: Los modelos de personajes 3D generados pueden separarse completamente en componentes semánticos como cuerpo, ropa y cabello, facilitando la edición y personalización posterior.
- Eficiencia: El proceso desde una imagen individual hasta un personaje 3D completo toma solo 3 minutos.
- Reconstrucción de alta calidad: Los modelos 3D generados presentan detalles geométricos y texturas finas.
Tecnología central
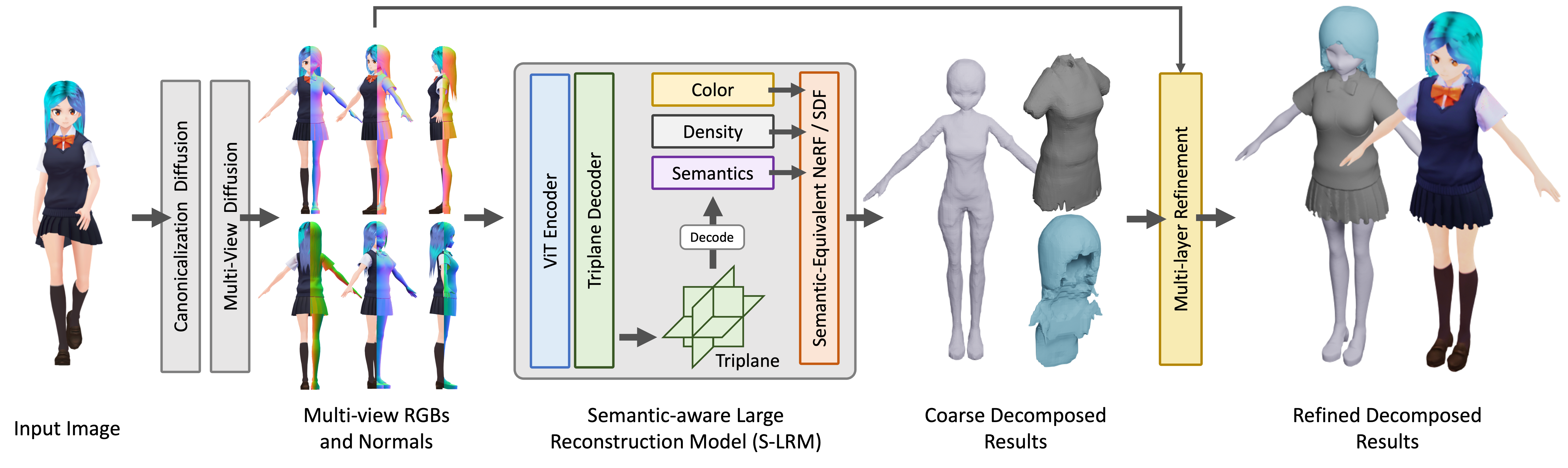 El núcleo de StdGEN es el Modelo de Reconstrucción Grande con Conciencia Semántica (S-LRM) propuesto por el equipo de investigación. Este es un modelo generalizable basado en Transformer capaz de reconstruir conjuntamente geometría, color e información semántica a partir de imágenes multivista de manera directa.
El núcleo de StdGEN es el Modelo de Reconstrucción Grande con Conciencia Semántica (S-LRM) propuesto por el equipo de investigación. Este es un modelo generalizable basado en Transformer capaz de reconstruir conjuntamente geometría, color e información semántica a partir de imágenes multivista de manera directa.
Además, el método introduce las siguientes innovaciones:
- Un esquema de extracción de superficie semántica multicapa diferencial para obtener mallas del campo implícito híbrido reconstruido por S-LRM
- Un modelo de difusión multivista eficiente especializado
- Un módulo de refinamiento de superficie multicapa iterativo
Perspectivas de aplicación
Esta tecnología tiene amplias perspectivas de aplicación en realidad virtual, desarrollo de videojuegos y producción cinematográfica. En comparación con los métodos existentes, StdGEN logra mejoras significativas en geometría, textura y descomponibilidad, proporcionando a los usuarios personajes 3D semánticamente descompuestos listos para usar que admiten personalización flexible.
El equipo de investigación ha publicado en código abierto el código de inferencia, conjuntos de datos y puntos de control preentrenados, y también proporciona una demostración en línea de HuggingFace Gradio.
Comentarios
Inicia sesión con GitHub para unirte a la conversación.