Sesame presenta el modelo vocal CSM para conversaciones realistas
Sesame lanza modelo de conversación vocal CSM con arquitectura dual Transformer, ofreciendo interacción en tiempo real y núcleo open source
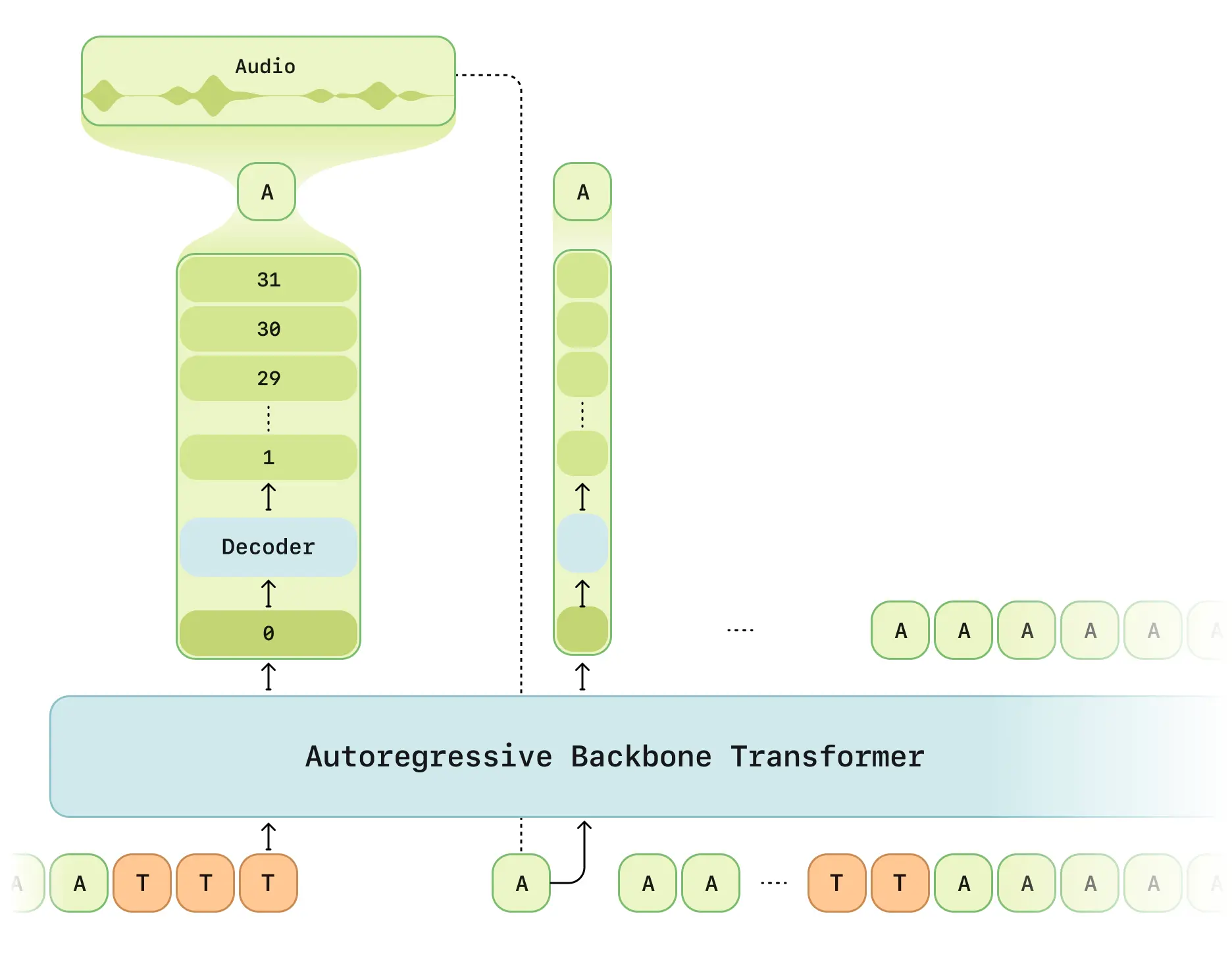
El modelo de conversación vocal CSM presentado por Sesame Research en su demostración oficial muestra capacidades revolucionarias. La arquitectura dual Transformer permite interacciones vocales casi humanas.
Arquitectura técnica
Características clave del CSM:
- Procesamiento en dos etapas: Red multimodal (texto/voz) + decodificador de audio
- Tokenizador RVQ: Codificador Mimi de cuantización a 12.5Hz
- Modo de latencia optimizada: Resuelve retrasos de generación RVQ
- Cálculo distribuido: Muestreo 1/16 para eficiencia
- Estructura Llama: Red principal basada en LLaMA
Funcionalidades principales
- Conciencia contextual: Memoria de 2 minutos (2048 tokens)
- Inteligencia emocional: Clasificador de 6 capas
- Tiempo real: Latencia < 500ms (promedio 380ms)
- Multihablante: Gestión simultánea de voces
Especificaciones técnicas
| Parámetro | Detalles | |
|
--| | Datos de entrenamiento | 1 millón de horas de conversaciones | | Tamaño del modelo | 8B backbone + 300M decodificador | | Longitud de secuencia | 2048 tokens (~2 minutos) | | Hardware requerido | RTX 4090 o superior |
Estado open source
Repositorio GitHub incluye:
- Libro blanco completo
- Ejemplos de API REST
- Kit de preprocesamiento de audio
- Guía de despliegue cuantizado
⚠️ Limitaciones:
- Código de entrenamiento no publicado (previsto Q3 2025)
- Requiere clave API
- Prioridad a escenarios en inglés
Resultados de evaluación
Según el informe oficial:
- Naturalidad: Puntuación CMOS equivalente a grabaciones humanas
- Comprensión contextual: +37% precisión
- Consistencia fonética: 95% estabilidad
- Latencia: Tiempo inicial reducido 68%
Fuentes: Artículo de investigación|X
Comentarios
Inicia sesión con GitHub para unirte a la conversación.