Alibaba Open Source ACE++: Generación de Imágenes Consistentes de Personajes Sin Entrenamiento
El Instituto de Investigación de Alibaba lanza la herramienta de código abierto ACE++ para generación de imágenes, que utiliza tecnología de relleno de contenido contextual para generar nuevas imágenes consistentes de personajes a partir de una sola entrada, ofreciendo experiencia en línea y tres modelos especializados.
10 de febrero de 2025 — El Instituto de Investigación de Alibaba anuncia oficialmente el lanzamiento de código abierto de su nueva herramienta de imagen AI ACE++. Basada en innovadores algoritmos de relleno de contenido contextual, los usuarios pueden generar nuevas imágenes con características altamente consistentes de personajes a partir de una sola imagen de entrada, con soporte para experiencia en línea y despliegue local.
Innovaciones Técnicas Principales
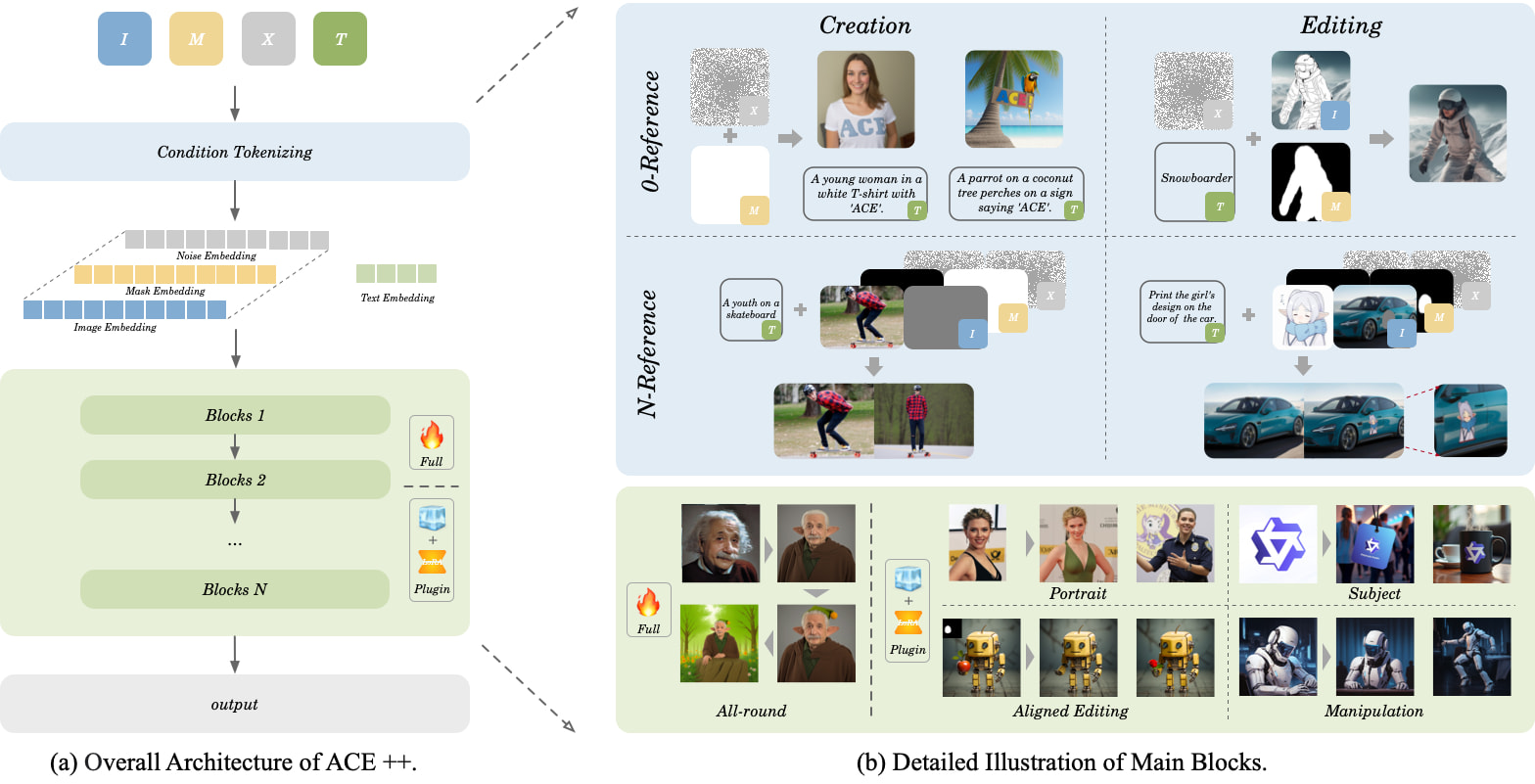
Características Clave
- Generación Sin Entrenamiento: Aprovecha el modelo base FLUX.1-Fill-dev, logrando despliegue sin entrenamiento mediante adaptación LoRA
- Edición Multimodal:
- Cambio de Vestuario de Personajes (soporta cambios de ropa/peinado/accesorios)
- Reconstrucción de Escenas (reemplazo de fondos/adición/eliminación de objetos)
- Restauración Inteligente (eliminación de defectos/mejora de calidad)
- Comprensión Semántica: Puede procesar instrucciones compuestas como "agregar vapor a la taza de café, colocar sobre mesa de madera"
Avances Técnicos
- Unidad de Contexto Largo (LCU): Procesa simultáneamente contenido de imagen, instrucciones de texto y regiones de edición
- Mecanismo de Atención Dinámica: Logra una tasa de retención de características del 92.3% en resolución 512×512
- Optimización en Dos Etapas: Enfoque de entrenamiento paso a paso que combina restauración básica y habilidades de edición especializadas
Pruebas de Escenarios de Aplicación
|  |
|  |
|
|
|
-|
-|
|  |
|  |
|
Aplicaciones Típicas
-
Cambios de Vestuario de Modelos Virtuales
- Genera visualizaciones multiángulo desde imágenes planas de ropa
- Soporta ajuste dinámico de tono de piel/tipo de cuerpo/escena
-
Diseño de Personajes para Películas
- Logra transformación entre estilos (realista→Disney/cyberpunk)
- Generación multiscena manteniendo continuidad de características
-
Restauración Inteligente de Imágenes
- Reconstrucción en resolución 4K de fotos antiguas
- Eliminación perfecta de oclusiones complejas
Canales de Acceso a Recursos
Entradas Oficiales
| Tipo de Recurso | Enlace de Acceso | |
--|
-| | Página del Proyecto | https://ali-vilab.github.io/ACE_plus_page/ | | Repositorio de Código | GitHub | | Experiencia en Línea | ModelScope |
Enlaces Oficiales de Descarga de Modelos
Modelos de Adaptación Especializados
| Tipo de Modelo | Nombre de Archivo | Descarga ModelScope | Descarga HuggingFace | |
|
--|
-|
| | Generación de Retratos | comfyui_portrait_lora64.safetensors | Modelo de Retrato | Modelo de Retrato | | Transferencia de Objetos | comfyui_subject_lora16.safetensors | Modelo de Sujeto | Modelo de Sujeto | | Edición Local | comfyui_local_lora16.safetensors | Modelo de Edición Local | Modelo de Edición Local |
Modelos Base Dependientes
| Nombre del Modelo | Canal de Descarga | |
|
--| | FLUX.1-Fill-dev | Descarga HuggingFace | | Flux-Fill FP8 | Descarga CivitAI |
Perspectivas de Desarrollo Técnico
La versión actual todavía tiene margen de mejora en el procesamiento de objetos complejos (precisión de detalles de manos 62.3%) y soporte de texto en chino. El equipo de desarrollo revela planes para lanzar funcionalidad de edición de fotogramas continuos de video en el tercer trimestre de 2025, y lanzará el modelo completo ACE++ Fully a finales de año.
Por favor, espere a los archivos de flujo de trabajo después de las pruebas de ComfyUI Wiki para actualizaciones de contenido Ver Actualizaciones de Flujo de Trabajo
Comentarios
Inicia sesión con GitHub para unirte a la conversación.