DeepSeek hace público Janus-Pro-7B: Modelo de IA multimodal
DeepSeek publica Janus-Pro-7B, un modelo de IA multimodal para comprensión y generación de imágenes. Aprende a usarlo en ComfyUI.
La empresa china de IA DeepSeek anunció la liberación de su modelo multimodal de próxima generación, Janus-Pro-7B, en las primeras horas de hoy. El modelo supera a DALL-E 3 de OpenAI y a Stable Diffusion 3 en tareas como la generación de imágenes y la respuesta a preguntas visuales, y ha causado sensación en la comunidad de IA con su arquitectura de "doble vía de comprensión-generación" y su solución de despliegue minimalista. Ver anuncio oficial
Rendimiento: Modelo pequeño supera a gigantes de la industria

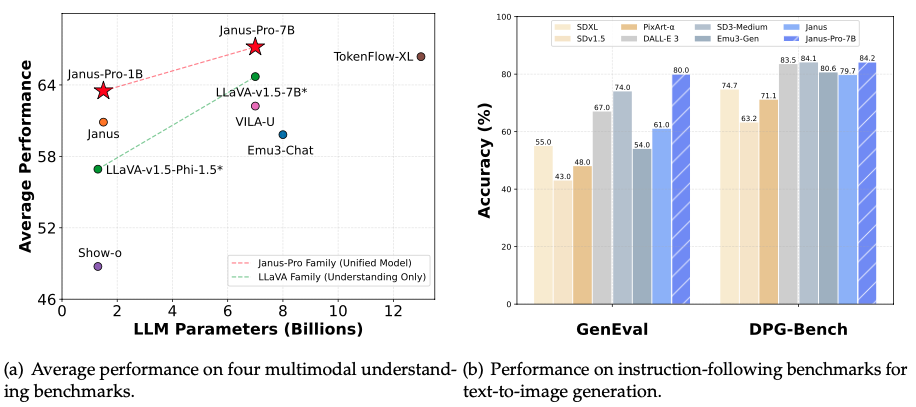
A pesar de tener solo 7 mil millones de parámetros (aproximadamente 1/25 de GPT-4), Janus-Pro-7B supera a sus competidores en pruebas clave:
- Calidad de texto a imagen: Logra un 80% de precisión en la prueba GenEval, superando a DALL-E 3 (67%) y Stable Diffusion 3 (74%)
- Comprensión de instrucciones complejas: Obtiene un 84.19% de precisión en la prueba DPG-Bench, generando con precisión escenas complejas como "una montaña nevada con un lago azul en su base"
- Respuesta a preguntas multimodales: La precisión en la respuesta a preguntas visuales supera a GPT-4V, con una puntuación de 79.2 en la prueba MMBench, cercana a los modelos de análisis profesional
Avance técnico: Colaboración de doble vía como "Janus"
Los modelos tradicionales utilizan el mismo codificador visual para comprender y generar imágenes, como pedirle a un chef que diseñe un menú y cocine al mismo tiempo. Janus-Pro-7B divide de manera innovadora el procesamiento visual en dos vías independientes:
- Vía de comprensión: Utiliza el codificador visual SigLIP-L para extraer rápidamente la información central de las imágenes (por ejemplo, "Este es un gato naranja en un sofá")
- Vía de generación: Descompone las imágenes en matrices de píxeles a través de un tokenizador VQ, dibujando gradualmente detalles como ensamblar bloques de Lego (por ejemplo, textura del pelaje, efectos de iluminación) Este diseño de "divide y vencerás" resuelve el conflicto de roles en los modelos tradicionales y mejora la estabilidad de la generación al entrenar con una mezcla de 72 millones de imágenes sintéticas y datos reales.
Código abierto y uso comercial
- Gratuito para uso comercial: Publicado bajo la licencia MIT, permitiendo uso comercial ilimitado
- Despliegue minimalista: Ofrece versiones de 1.5B (requiere 16GB de VRAM) y 7B (requiere 24GB de VRAM), ejecutables en GPUs estándar
- Generación con un clic: Se proporciona una interfaz oficial de Gradio; ingrese
generate_image(prompt="montaña nevada al atardecer", num_images=4)para generar imágenes en lote
Recursos oficiales:
- Repositorio en GitHub: https://github.com/deepseek-ai/Janus
- Descarga del modelo: HuggingFace Janus-Pro-7B
Escenarios de aplicación: Desde el arte hasta la protección de la privacidad
- Industrias creativas: Los diseñadores ingresan texto para generar prototipos de carteles; los desarrolladores de juegos construyen rápidamente activos de escenas
- Herramientas educativas: Los profesores usan el modelo para generar ilustraciones dinámicas de erupciones volcánicas para lecciones de geografía
- Privacidad empresarial: Hospitales y bancos pueden implementar localmente, evitando la necesidad de subir registros de pacientes o datos financieros a la nube
- Difusión cultural: Reconoce hitos globales (por ejemplo, el Lago del Oeste en Hangzhou) y genera imágenes con símbolos culturales
Recursos oficiales de DeepSeek Janus**
- Repositorio de código: GitHub Janus-Pro-7B
- Descarga del modelo: Página del modelo en HuggingFace
Comentarios
Inicia sesión con GitHub para unirte a la conversación.